1毫秒级,最快的人体动作捕捉服!开源715万帧数据集| CVPR'26
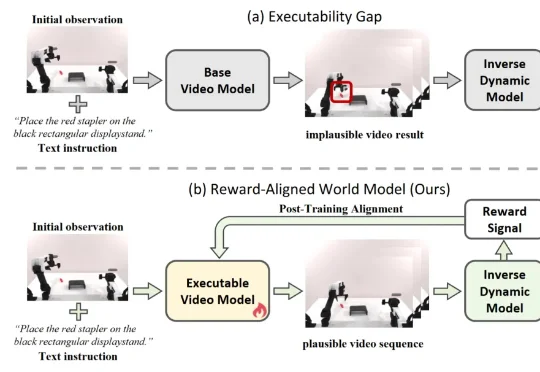
1毫秒级,最快的人体动作捕捉服!开源715万帧数据集| CVPR'26全球首个1毫秒级人体动作捕捉系统FlashCap,通过闪烁LED与事件相机结合,实现1000Hz超高帧率捕捉。无需昂贵设备或强光环境,低成本穿戴服即可精准捕捉极速动作。团队同步开源715万帧的FlashMotion数据集与多模态模型ResPose,显著提升运动分析精度,推动体育、VR与机器人领域迈向高动态智能新阶段。
来自主题: AI技术研报
7207 点击 2026-03-31 14:40