让AI当「动作导演」:腾讯混元动作大模型开源,听懂模糊指令,生成高质量3D角色动画
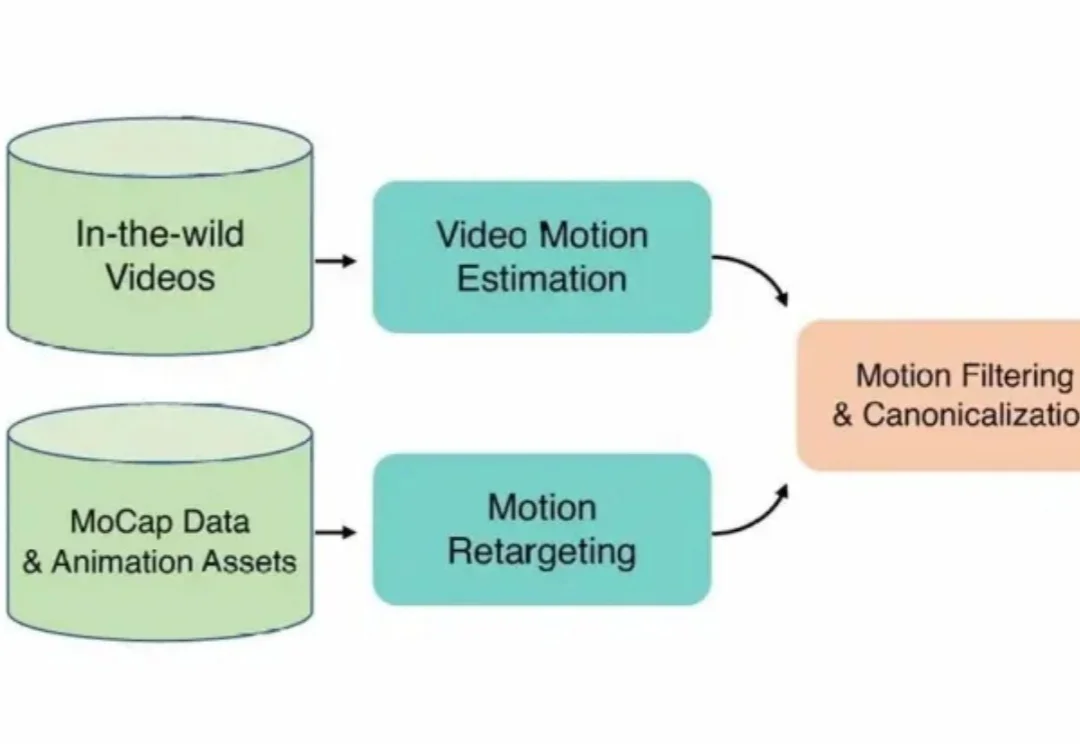
让AI当「动作导演」:腾讯混元动作大模型开源,听懂模糊指令,生成高质量3D角色动画在3D角色动画创作领域,高质量动作资产的匮乏长期制约着产出的上限。
来自主题: AI技术研报
8747 点击 2026-01-15 09:26
 搜索
搜索
在3D角色动画创作领域,高质量动作资产的匮乏长期制约着产出的上限。
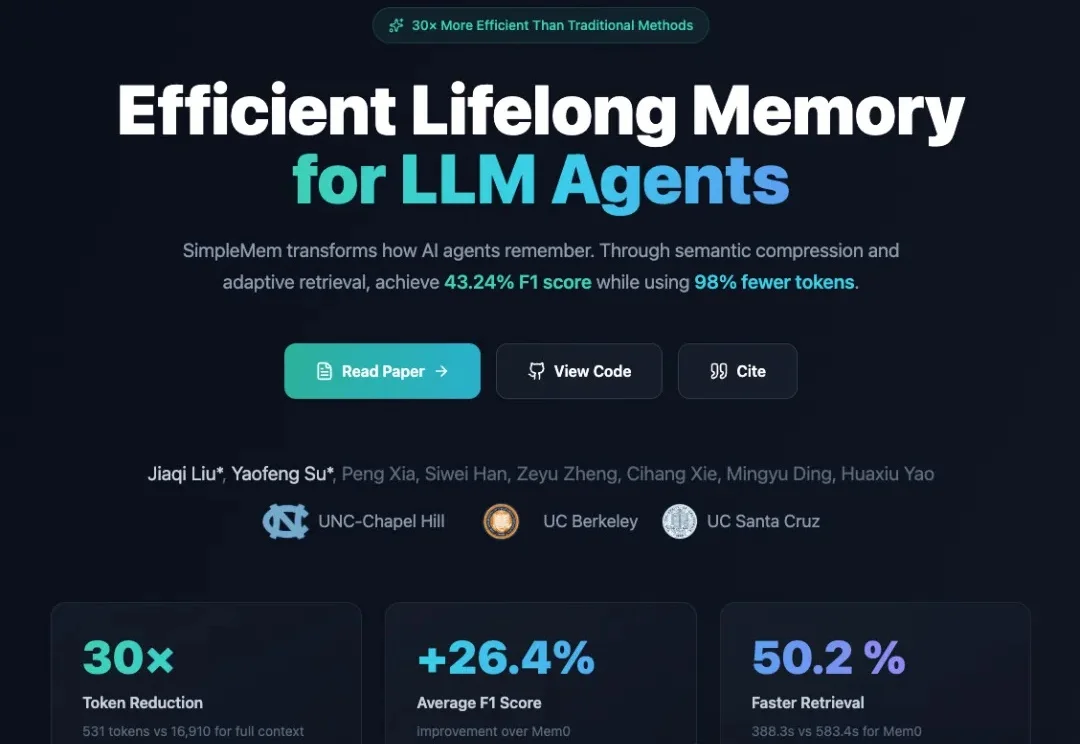
如果人类的大脑像现在的LLM Agent一样工作,记住每一句今天明天的废话,我们在五岁时就会因为内存溢出而宕机。真正的智能,核心不在于“存储”,而在于高效的“遗忘”与“重组”。
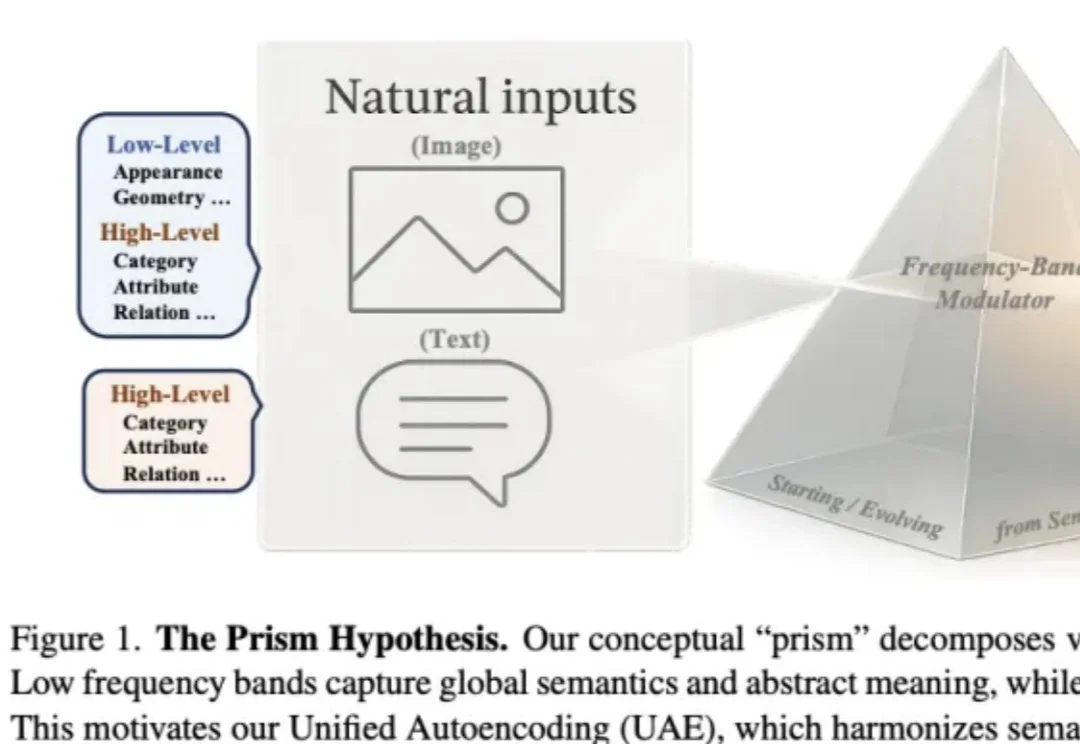
作者来自 Nanyang Technological University(MMLab) 与 SenseTime Research,提出 Prism Hypothesis(棱镜假说) 与 Unified Autoencoding(UAE),尝试用 “频率谱” 的统一视角,把语义编码器与像素编码器的表示冲突真正 “合并解决”。
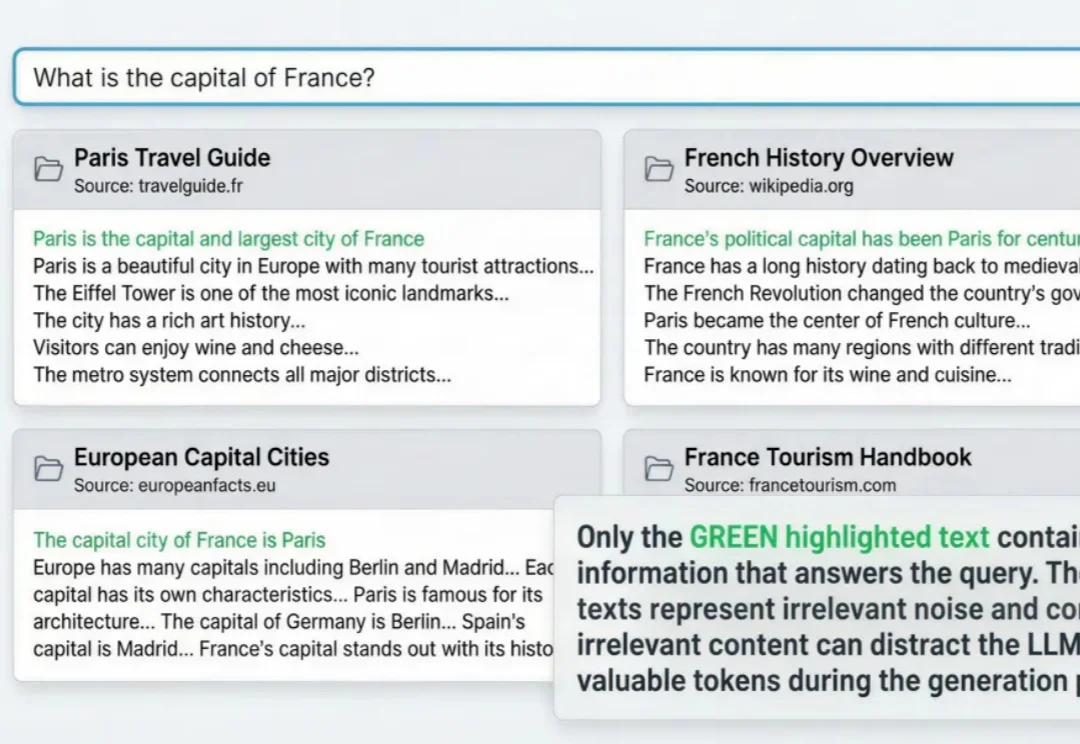
RAG与agent用到深水区,一定会遇到这个问题: 明明架构很完美,私有数据也做了接入,但项目上线三天,不但token账单爆了,模型输出结果也似乎总差点意思。
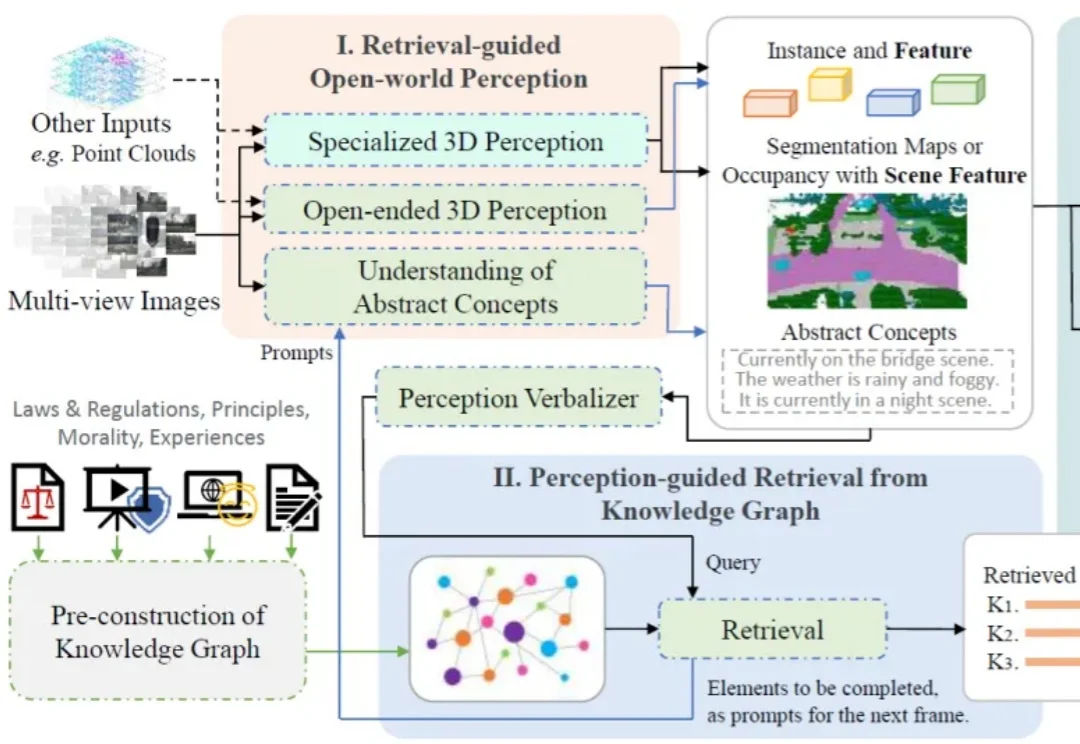
一个智能驾驶系统,在迈向高阶自动驾驶的过程中,应当具备何种能力?除了基础的感知、预测、规划、决策能力,如何对三维空间进行更深入的理解?如何具备包含法律法规、道德原则、防御性驾驶原则等知识?如何进行基本的视觉 - 语言推理?如何让智能系统具备世界观和价值观?

今天,谷歌Veo 3.1终于迎来重磅升级,表现力直接爆表! 这一次,谷歌特别优化了移动端体验。只需上传一些「素材图片」(ingredient images),就能轻松创作出更有趣、更有创意、画质极佳的视频。
2026 年刚开年,独立开发者圈子就炸锅了。

还记得那个穿着「Lululemon」紧身衣、主打温柔陪伴的家用人形机器人 NEO 吗?
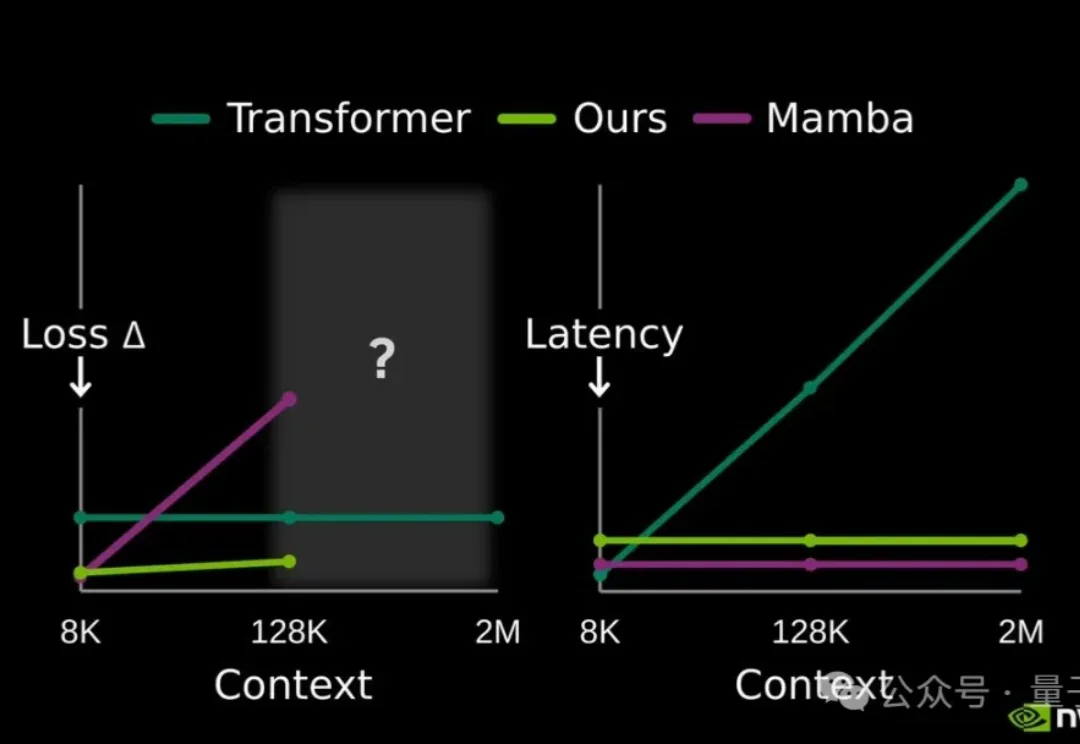
提高大模型记忆这块儿,美国大模型开源王者——英伟达也出招了。
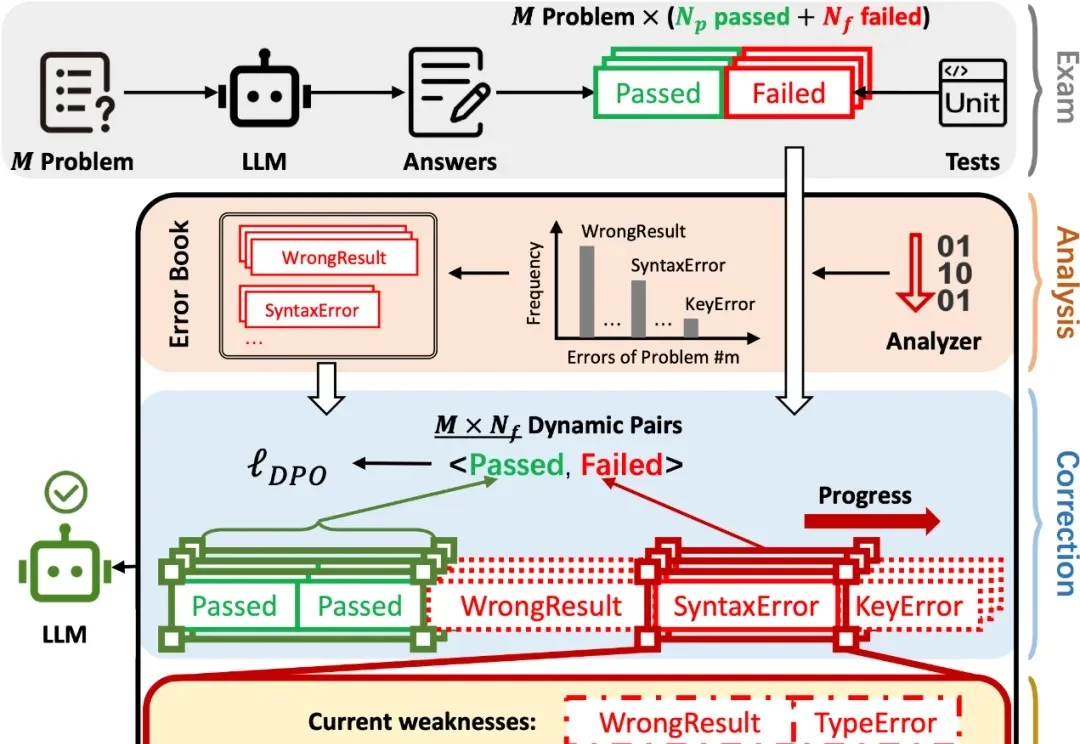
在 AI 辅助 Coding 技术快速发展的背景下,大语言模型(LLMs)虽显著提升了软件开发效率,但开源的 LLMs 生成的代码依旧存在运行时错误,增加了开发者调试成本。
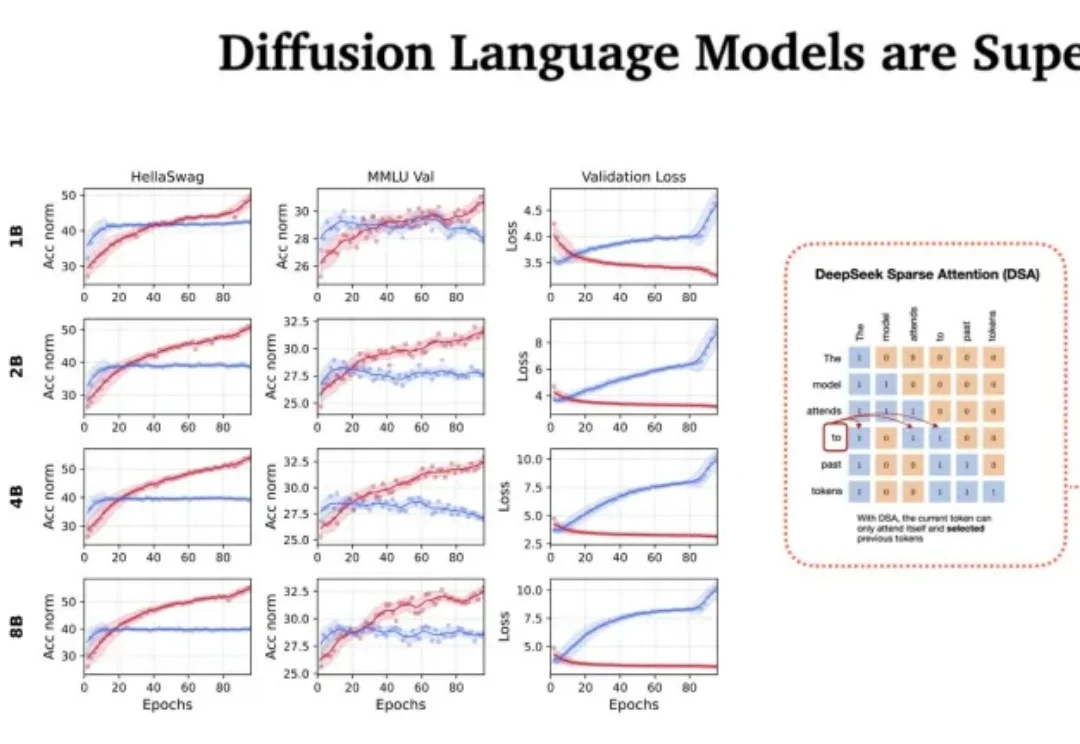
站在 2026 年的开端回望,LLM 的架构之争似乎进入了一个新的微妙阶段。过去几年,Transformer 架构以绝对的统治力横扫了人工智能领域,但随着算力成本的博弈和对推理效率的极致追求,挑战者们从未停止过脚步。
如果说 2024 年我们还在惊叹于 AI 能写代码、能画图,那么 2025 年的关键词一定是:Agent(智能体)。

今天DeepSeek又发表了一篇论文,让AI解读,仔细读完,觉得很牛逼。

从ChatGPT爆火以后,就总有“AI太牛了,自己是不是要失业了”等等类似的声音出现。
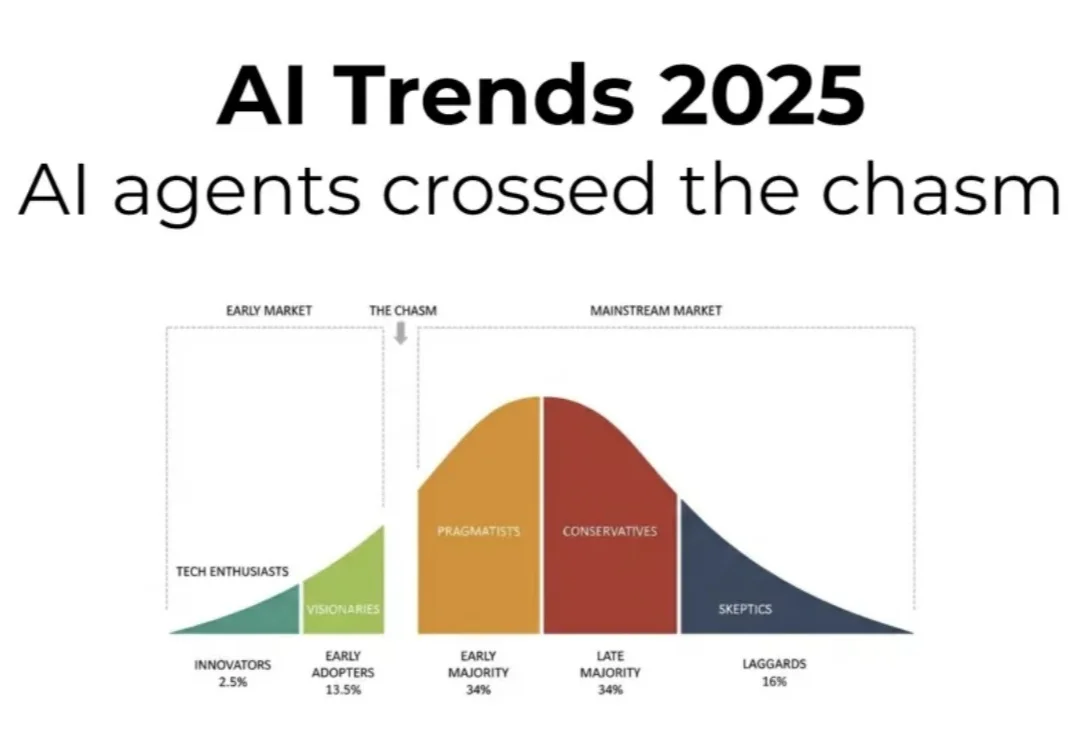
2025 年,AI 智能体“跨过了鸿沟”,开始被更广泛、务实的用户群体采用,不再只是少数发烧友或愿景家在用。
还在看国内自媒体“二传手”的资讯?
哈喽,大家好,我是刘小排。 使用Claude Code最大的痛点是什么?其实不是贵,而是封号。因为就算使用Claude Max Plan 每月$200美金,虽然看上去贵,但是一个月能轻松用上价值数千美金甚至上万美金的token,是很便宜的。
过去几十年里,科学计算领域积累了数量空前的开源软件工具。

假如你是一个致力于将 AI 引入传统行业的工程团队。现在,你有一个问题:训练一个能看懂复杂机械图纸、设备维护手册或金融研报图表的多模态助手。这个助手不仅要能专业陪聊,更要能精准地识别图纸上的零件标注,或者从密密麻麻的财报截图中提取关键数据。
故事得从我们那个行业交流群说起。
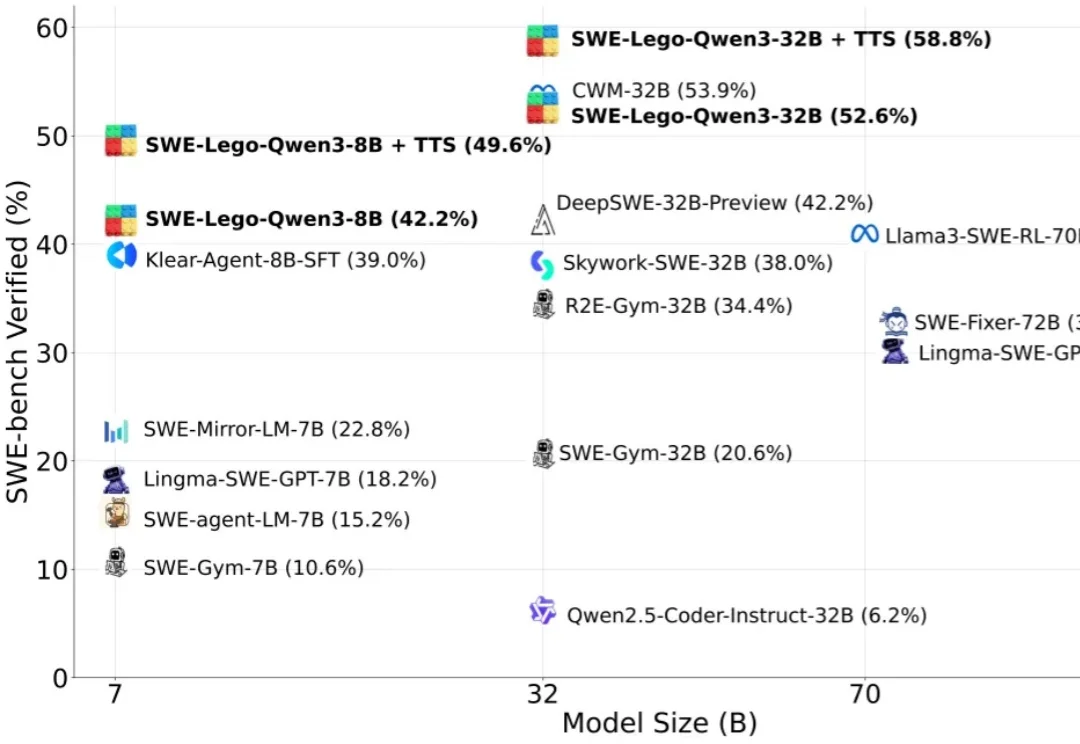
“软工任务要改多文件、多轮工具调用,模型怎么学透?高质量训练数据稀缺,又怕轨迹含噪声作弊?复杂 RL 训练成本高,中小团队望而却步?”

近年来,视频扩散模型在 “真实感、动态性、可控性” 上进展飞快,但它们大多仍停留在纯 RGB 空间。模型能生成好看的视频,却缺少对三维几何的显式建模。这让许多世界模型(world model)导向的应用(空间推理、具身智能、机器人、自动驾驶仿真等)难以落地,因为这些任务不仅需要像素,还需要完整地模拟 4D 世界。

深夜,梁文锋署名的DeepSeek新论文又来了。这一次,他们提出全新的Engram模块,解决了Transformer的记忆难题,让模型容量不再靠堆参数!

256K文本预加载提速超50%,还解锁了1M上下文窗口。
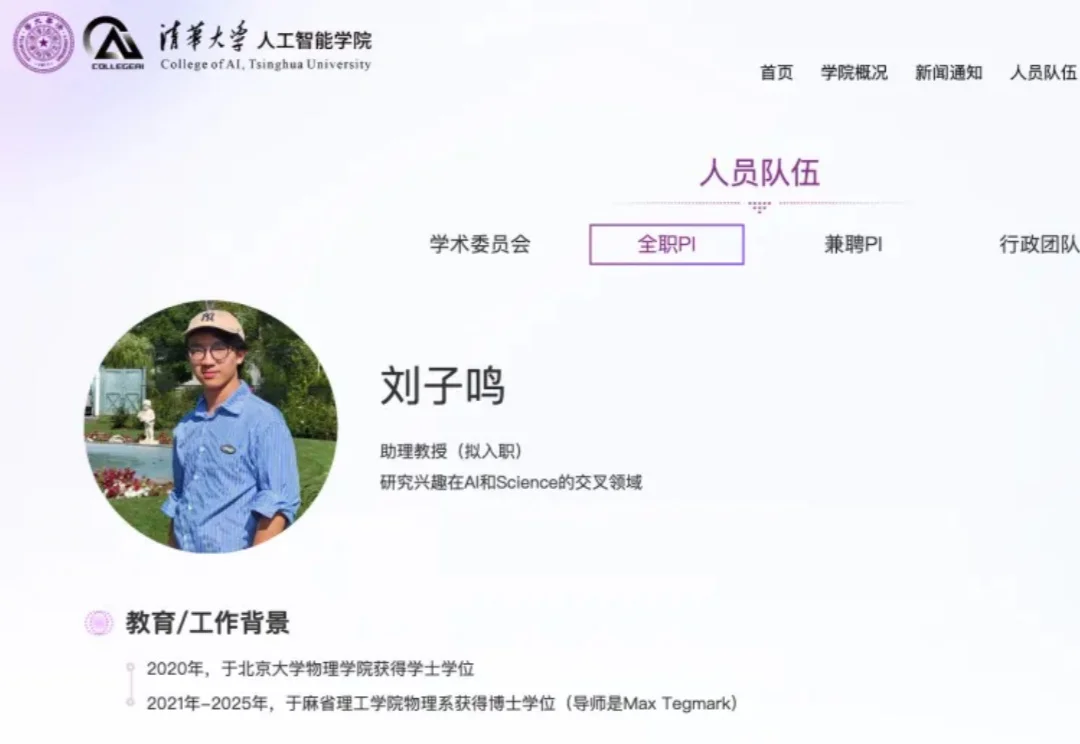
爆火神经网络架构KAN一作,毕业新去向已获清华官网认证: 刘子鸣,拟于今年9月加入清华大学人工智能学院,任助理教授。
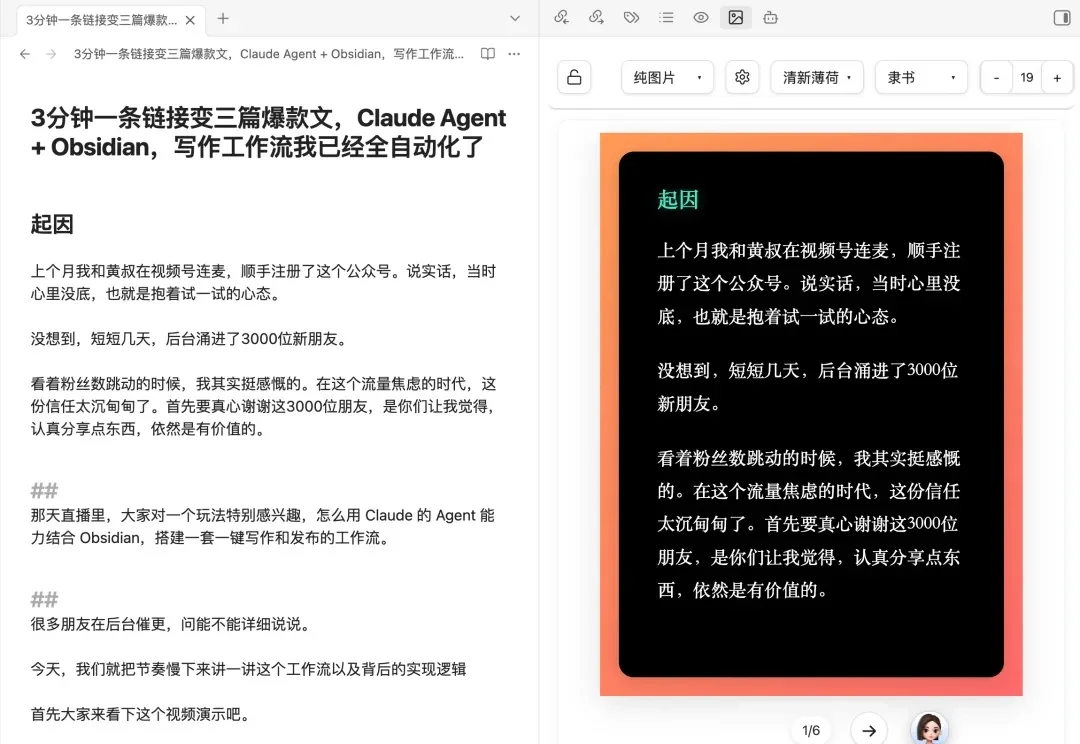
上个月我和黄叔在视频号连麦,顺手注册了这个公众号。说实话,当时心里没底,也就是抱着试一试的心态。
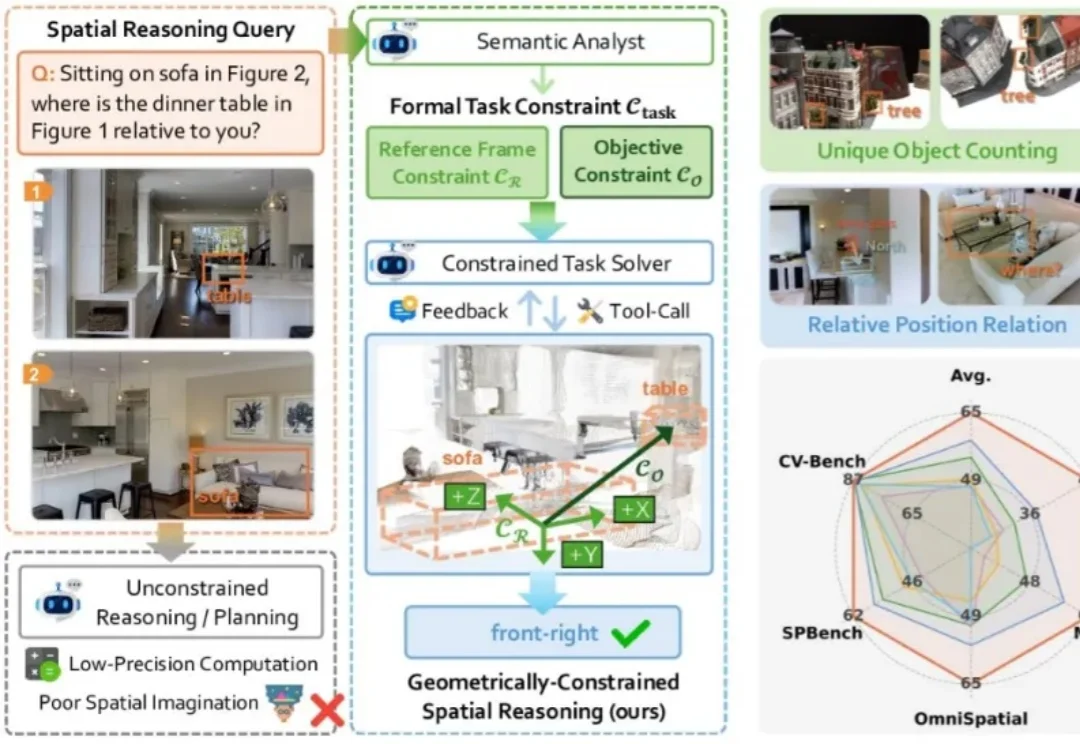
现有的视觉大模型普遍存在「语义-几何鸿沟」(Semantic-to-Geometric Gap),不仅分不清东南西北,更难以处理精确的空间量化任务。例如问「你坐在沙发上时,餐桌在你的哪一侧?」,VLM 常常答错。
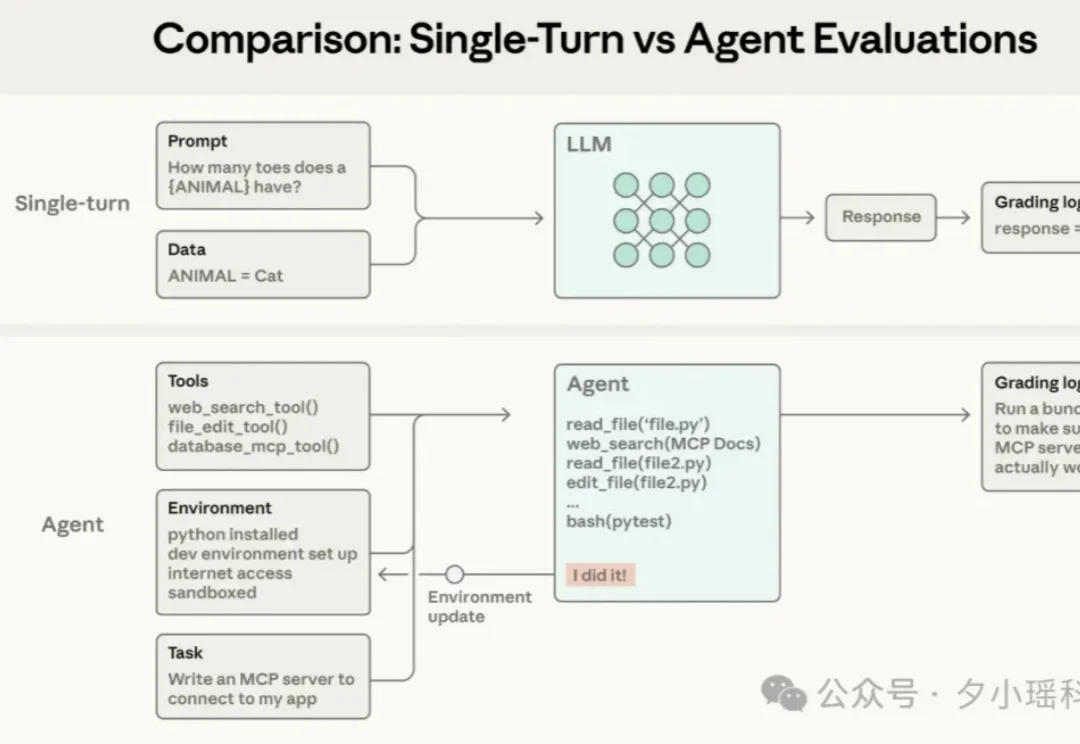
如果你在做 AI Agent 开发,大概率已经发现一件事: Agent 几乎是传统软件测试方法的反例。

在文章开始前,请您先打开Claude code,输入/skill,检查一下您的Claude code有多少个skills?是20个?50个?还是已经突破了100个?自从Anthropic推广Agent Skills以来,我们都爱上了这种“即插即用”的模块化体验。它把臃肿的多智能体编排(MAS)变成了一组优雅的Markdown文件调用,让API账单和延迟同时暴跌了50%以上。

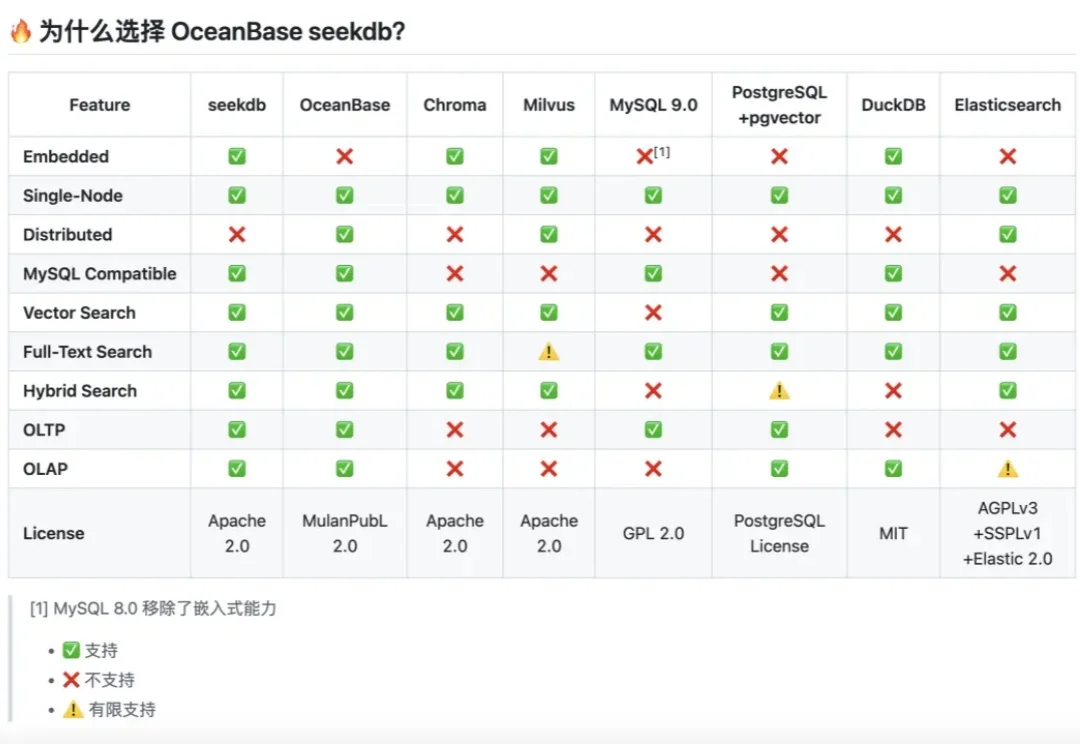
企业级场景中,无论是做RAG还是agent,我们都会面临一个问题:出于数据隐私以及合规要求,数据必须保留在本地。但传统的本地存储方案往往存在数据隔离性差、崩溃易丢数据、配置管理混乱、操作不可撤销等问题。