北航、北大和美团联合提出:策略提升强化学习!
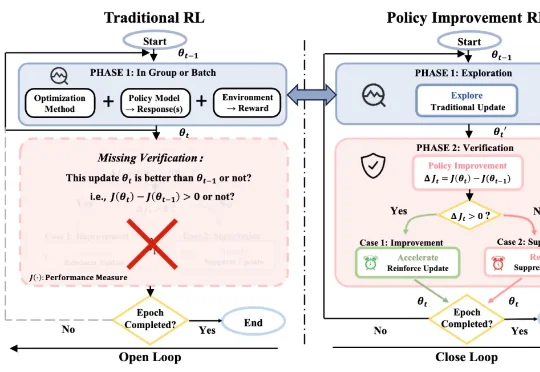
北航、北大和美团联合提出:策略提升强化学习!来自北航、北大、美团的研究团队提出了Policy Improvement Reinforcement Learning, PIRL,以及对应的落地算法 PIPO。这项工作关注的是大模型 RL 后训练中一个非常基础、但长期被默认跳过的问题:一次更新在当前数据上看起来优化了学习信号,是否就真的说明模型策略变强了?
来自主题: AI技术研报
8089 点击 2026-07-12 10:44
 搜索
搜索
来自北航、北大、美团的研究团队提出了Policy Improvement Reinforcement Learning, PIRL,以及对应的落地算法 PIPO。这项工作关注的是大模型 RL 后训练中一个非常基础、但长期被默认跳过的问题:一次更新在当前数据上看起来优化了学习信号,是否就真的说明模型策略变强了?
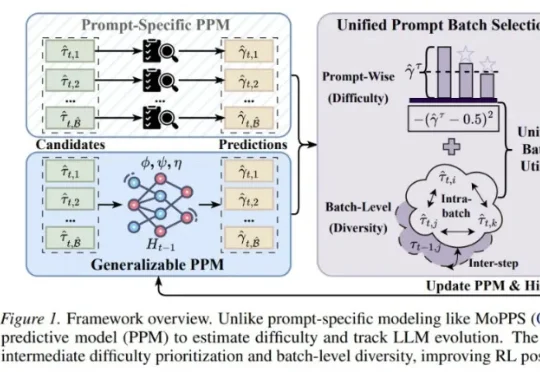
来自清华大学与腾讯的研究者提出了 Generalizable Predictive Prompt Selection(GPS)。GPS 的做法很直接:先训练一个小型、可泛化的 Prompt Predictive Model(PPM),让它预测不同 prompt 在当前模型下的难度;再根据难度和 batch 多样性选择训练样本,从而减少无效 rollout。

本文发现图生视频(I2V)模型天然适合重构动态交互过程,并提出 SCPE(Self-Correcting Process Editing) 多智能体系统自纠错框架:利用视频生成过程暴露失败原因,再通过分析、反思和工具书更新迭代增强提示,使 I2V 模型在复杂 HOI 编辑中显著提升交互准确性与推理能力。
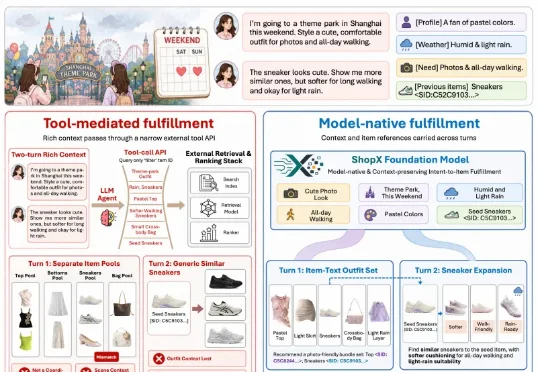
团队提出了ShopX:一个面向agentic shopping的电商大模型。它不仅仅是在搜索框外面套一个会“说话”和“调用工具”的LLM,而是赋予模型直接进入商品空间的能力,让大模型成为商品履约的核心,学会在商品空间中规划、检索、排序、组合和生成结果,进而减少接口损耗。

研究团队提出了 XG-Guard (eXplainable and fine-Grained safeGuarding framework), 一个基于 GAD 且兼具可解释性和细粒度检测能力的无监督安全防护框架。目前工作已被 ACL 2026 Main Conference 接收。
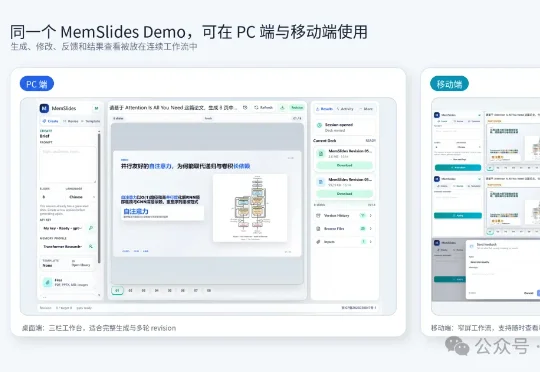
来自清华、上交、北邮的学者们提出了一个面向个性化幻灯片生成和多轮局部修改的记忆驱动Slides Agent框架——MemSlides。它专门针对AI PPT痛点而生,不仅能够为你量身定制私人专属的PPT生成风格,还能够贴心地记住你在制作过程中随口提出的新要求
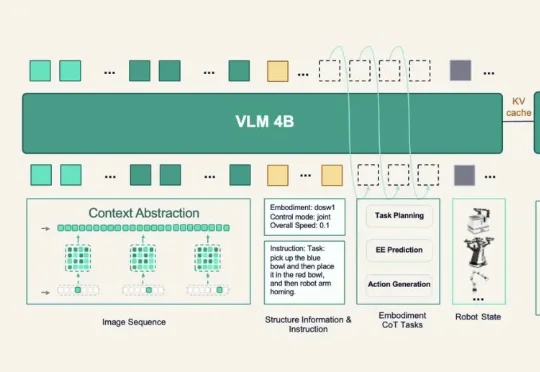
今天的原力灵机开发者大会上,这家公司就把新一代具身基础模型DM0.5端上了桌。 往前,它能接住数据飞轮;往后,它连着开发者平台与真实场景,可以说是后续一切落地动作的底座。

研究团队提出了符号嵌入量子算法(Sign Embedding Quantum Algorithms),形成了一篇84页的量子算法论文。可以说,相比此前主要解决研究者给定的开放数学问题,这一次,AIM开始参与研究问题的提出与方向探索。

蚂蚁灵波选择了后一条路:开源 LingBot-Video。这是一个面向具身智能的视频生成基座模型,也是一套专为机器人场景设计的 DiT 视频预训练范式。通用视频模型更多学习画面变化、镜头运动和视觉风格;LingBot-Video 则把重点放在动作、任务、交互和物理环境变化上,面向世界预测、动作理解和机器人训练构建视频生成基座。
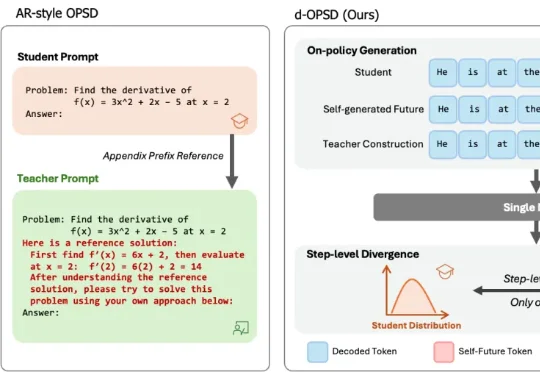
有没有一种更为合适的 OPSD 范式?近期,清华大学和马普所等机构的研究者们联合推出的 d-OPSD,给这一问题提供了完美的答案。这是第一个针对扩散大语言模型的 OPSD 范式,无需参考解,无需额外的教师模型,只需要 RL 十分之一的训练步数,便可以达到或超出 RL 的后训练效果。

今天原力灵机正式发布的 DM0.5 往前推进了一步。它不只是继续提高某些固定任务上的表现,而是围绕真实世界里的泛化问题做了一次系统突。 如果深入分析,就会发现 DM0.5 这几个核心提升,都是想解决一个问题:如何让具身模型从可控环境里的能力演示,走向开放环境里的稳定执行。
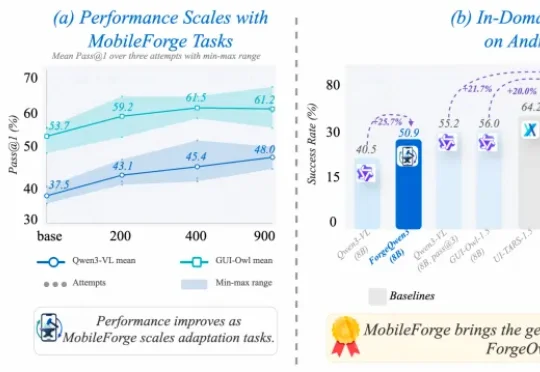
来自浙江大学 APRIL 实验室、快手主站技术部和清华大学的研究团队提出了 MobileForge,试图把手机 GUI Agent 的适配过程变成一个 “无标注、自探索、自反馈、自优化” 的闭环系统。
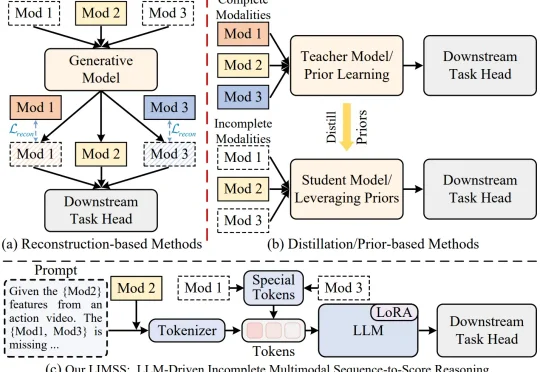
本文是北京大学彭宇新教授团队联合福州大学柯逍教授团队在细粒度多模态动作质量评价领域的最新研究成果,相关论文已被 ICML 2026 接收为 Spotlight,并已开源。真实世界中的多模态数据往往并不完整。在动作质量评价任务中,视频、光流、音频等模态能够从不同角度描述动作执行过程,但在实际采集时,传感器故障、环境噪声、隐私限制等因素都会导致模态缺失。
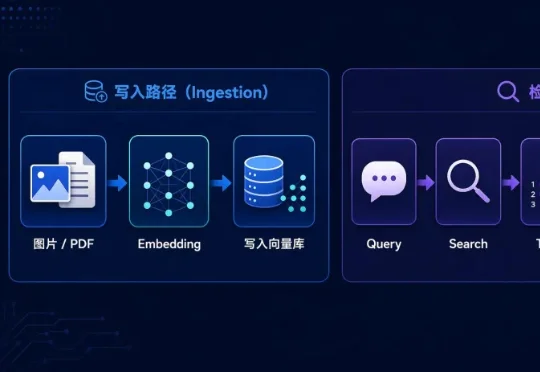
多模态 Agent 的记忆系统,过去很容易被理解成一个升级版 RAG:图片、图表、PDF 进来之后,先抽取内容、做 embedding、写进向量库;用户提问时,再用 query 做检索,把命中的top-k图片、文档页或图表一并塞进上下文,再交给多模态模型回答。整个过程中,所有原始模态信息都会不加选择的塞给大模型。
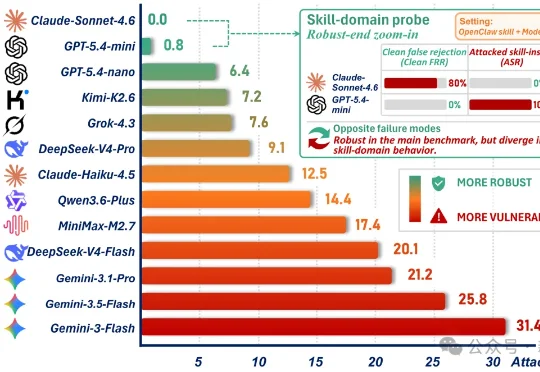
近日,来自KAUST生成式AI卓越中心、吉林大学、浙江大学、瑞士人工智能实验室等机构,由包括「现代人工智能之父」Jürgen Schmidhuber在内的研究者组成的团队,发布了一篇回答这个问题的研究论文。
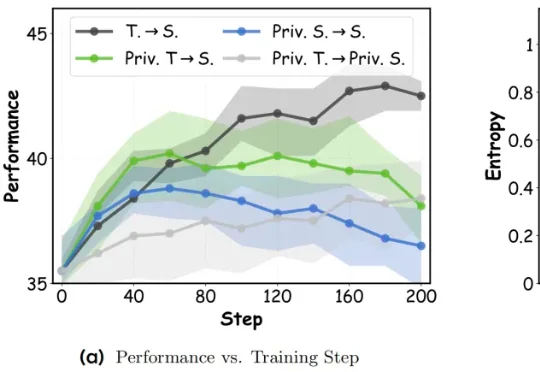
最近,来自新加坡国立大学、香港中文大学 MMLab、北京大学和京东探索研究院的研究团队提出了一种全新的在线策略蒸馏方法: DOPD (Dual On-policy Distillation) ,通过优势感知的双重蒸馏范式,成功破解了这一难题。

6 月 30 日,深度机智团队发布论文 Human-as-Humanoid。他们在自研拟人机器人 PrimeU 上,实现了完全没有目标任务真机示范数据的情况下,仅凭从人类视频中转换而来的动作监督,零样本完成了倒水、放环、装袋、叠杯等复杂真实操作任务。
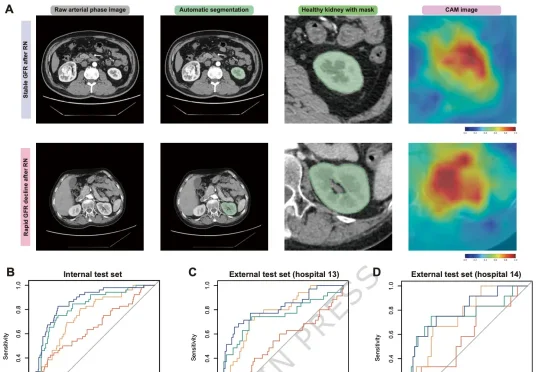
2026年5月28日,Nature通讯发表了题为 《Multimodal deep learning model for AI-based functional prognostic risk stratification in patients undergoing radical nephrectomy》 的论文。
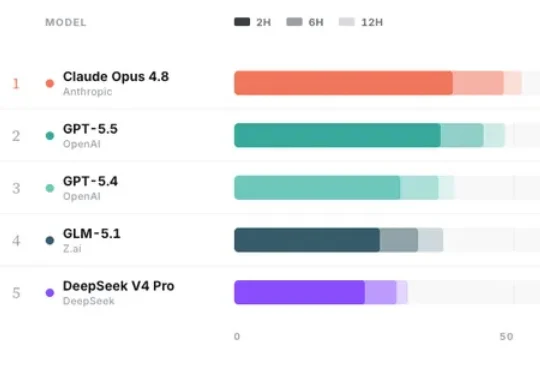
7月2日,字节 Seed 发布了一个 Agent评测项目 EdgeBench。看起来又是一个 benchmark,但它问了一个其他榜单不问的问题。EdgeBench 的切口就是把盲区里的东西放进评测,解答一个问题:把Agent扔进一个陌生环境,12小时后,你能变强多少?
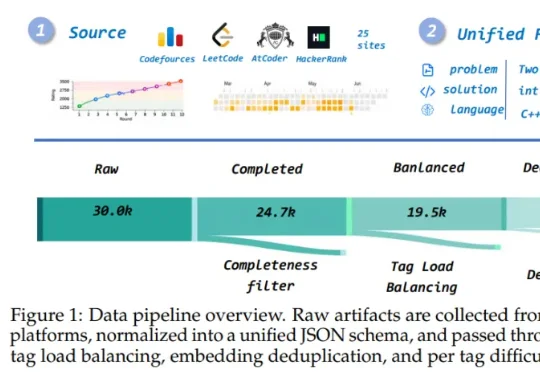
大语言模型在代码生成上的能力不断增强,但在复杂算法题,尤其是竞赛编程场景中,仍然容易因为算法选择错误、边界条件遗漏、复杂度判断失误或隐藏测试覆盖不足而失败。Solvita是一款面向竞赛编程的智能体框架,通过四个角色(Planner、Solver、Oracle、Hacker)形成闭环系统,并利用可训练的图结构知识网络积累经验。

现在的 AI Agent 动辄需要处理超长上下文,既要看系统提示词、工具说明,又要翻阅历史对话和检索文档。为了省钱、省算力并降低延迟,很多开发者会给系统加上 “提示词压缩”(Prompt Compression)模块,把冗长的上下文浓缩后再喂给大模型。
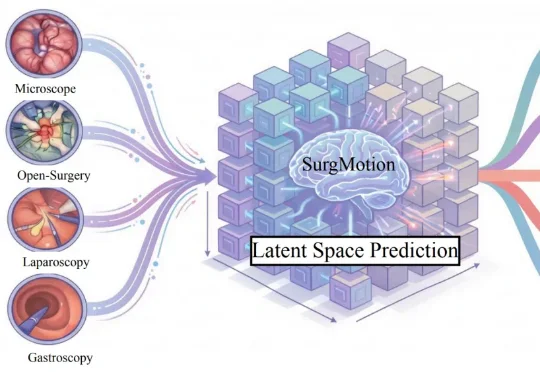
手术 AI 正在从 “单帧感知” 迈向 “全流程视频理解” 的全新时代!近日,由中国科学院香港创新研究院人工智能与机器人创新中心领衔,发布了全球首个十亿级参数、最大规模数据集练成的手术视频原生基础模型 ——SurgMotion!

MrFlow(Multi-Resolution Flow Matching)就用这样的三阶段,在Qwen-Image等模型上把端到端生成时间从49.32s压到4.77s,实际加速10.35x。文章发布当日即登上Hugging Face Daily Papers;发布三天内,GitHub已收获200+stars;目前也已登上Hugging Face Trending Papers。

Exponential View 在 2026 年 6 月底发布《AI 经济现状报告》,通过一套去重复统计、自下而上覆盖千余家企业的财务测算模型,剥离行业虚高估值与宣传泡沫,还原海外生成式 AI 市场真实营收、资本开支、算力供需与产业链价值分配格局。

VLA 大模型看似强大,却被一个致命弱点扼住喉咙——相机稍微挪动几毫米,操作成功率就能暴跌一半。招商局先进技术研究院下属实验室提出新的移动数据范式,首次在真实机器人系统上证明:让相机动起来采集数据,就能以极低成本破解 VLA 的空间泛化瓶颈,且效果普适于多种主流架构。被一个致命弱点扼住喉咙——相机稍微挪动几毫米,操作成功率就能暴跌一半。
针对这一问题,openJiuwen社区正式发布Skill-Omni——业界最早工程化落地的多模态Skill范式。 它让Agent的经验从“读得懂”升级为“看得见”,把网页和视频中的视觉知识,沉淀为Agent可复用的多模态Skill。
刚刚,翁荔(Lilian Weng)又更新博客了!距离她上一次更新《谨慎对待 Scaling Law》还不到 10 天。这一次,她书写的主题是当前大热的 Harness Engineering,聚焦的正是当下 AI 研究最前沿一个环节:当模型本身的智能已经足够强大时,真正决定它能走多远的,或许是包裹在模型外面的那层「Harness」也就是负责编排模型思考、调用工具、管理上下文、评估结果的那套系统。

刚刚,DeepSeek 在官方 API 文档里给出了一个 thinking mode 和 tool call 结合使用的样例。表面上看,这只是一个常规的工具调用演示:用户提出问题,模型判断需要调用工具,工具返回结果后,模型再继续生成答案。
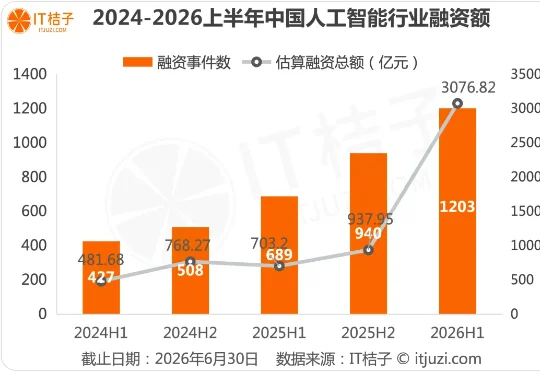
2026年上半年,中国AI创业公司经历了一场狂热的融资热潮,总融资额突破三千亿元,仅6个月的融资体量已超过2025年全年。AI融资金额占市场约48.6%,接近一半,事件数占比约22.5%。

视频虚拟试衣(VVT)作为电商展示与数字内容创作中的核心技术,已在动态人物换装、服装纹理保持和视频时序连贯性方面取得显著进展。然而,现有方法大多仍受限于固定相机视角,生成结果被动依赖源视频的原始相机轨