这些大神在Meta的论文看一篇少一篇了
这些大神在Meta的论文看一篇少一篇了离开Meta的大佬们,留下作品还在陆续发表,今天轮到田渊栋。
来自主题: AI技术研报
6841 点击 2025-11-18 09:33
 搜索
搜索
离开Meta的大佬们,留下作品还在陆续发表,今天轮到田渊栋。

港大、港科大与西电团队登上Nature子刊,破解AI芯片核心难题。他们攻克存算一体架构中模数转换器(ADC)这个占能耗87%的「黑洞」,利用忆阻器可编程特性打造能自适应数据分布的「智能标尺」,使AI芯片功耗锐减57.2%,面积缩小30.7%,为下一代高效AI硬件系统开辟新路。

嗨大家好!我是阿真! 继续为大家带来一些有趣的好玩的工具分享。
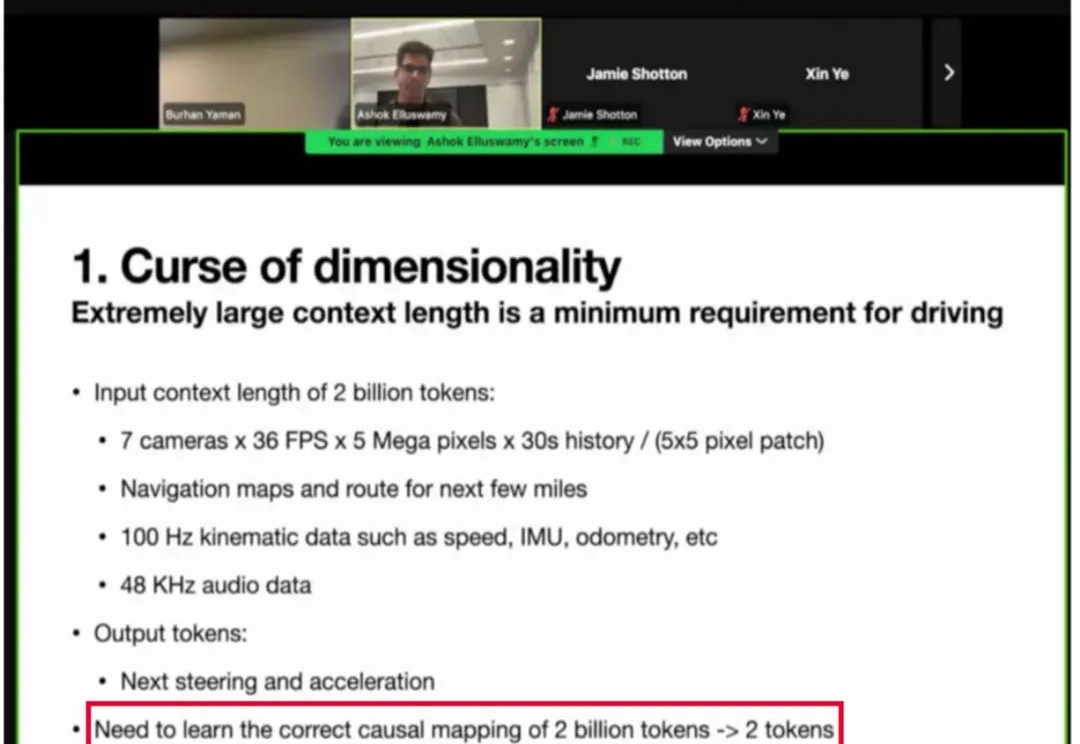
在自动驾驶领域,VLA 大模型正从学术前沿走向产业落地的 “深水区”。近日,特斯拉(Tesla)在 ICCV 的分享中,就将其面临的核心挑战之一公之于众 ——“监督稀疏”。
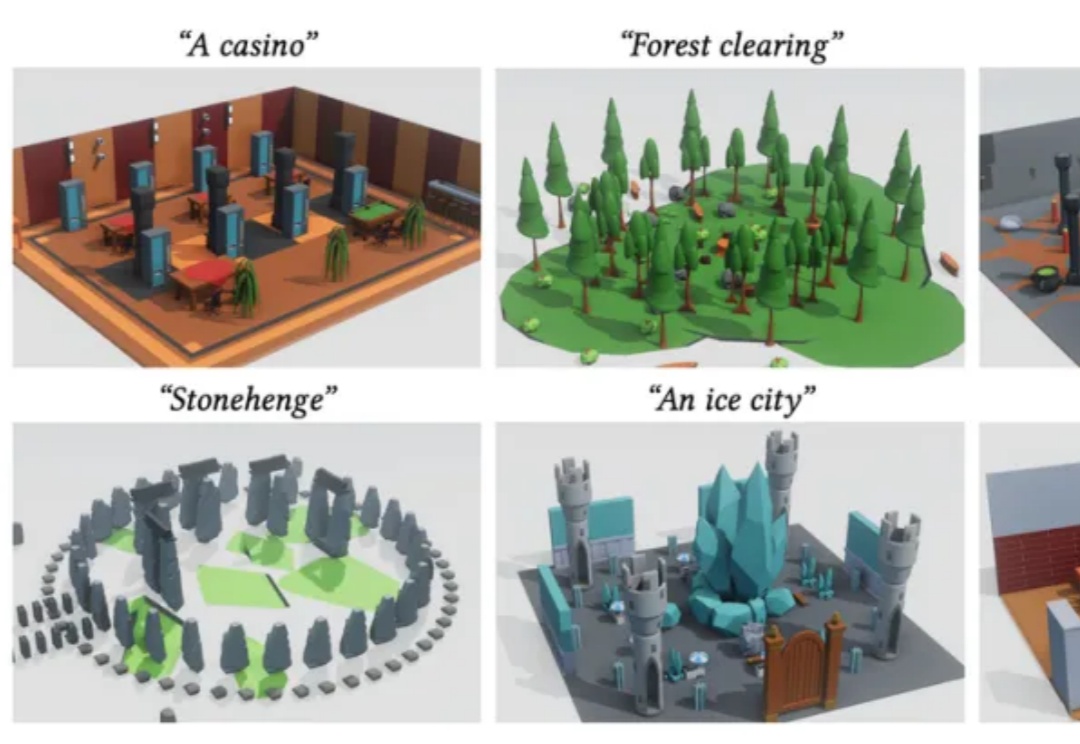
随着生成式 AI 的快速发展,从文本生成图像、视频,到构建完整的三维世界,AI “创造空间” 的能力正以前所未有的速度突破边界。然而,现有 3D 场景生成方法仍存在明显局限:模型往往直接输出每个物体的几何参数(位置、大小、方向等),结果容易出现漂浮、重叠、穿模等问题;场景结构缺乏逻辑一致性,难以编辑或复用,更无法像程序那样精确控制空间关系与生成逻辑。
做过独立开发的朋友都清楚,虽然现在 AI 已经能写出相当不错的前端,后端也有成熟的 BaaS 服务,但应用开发并不仅仅只是写份代码。
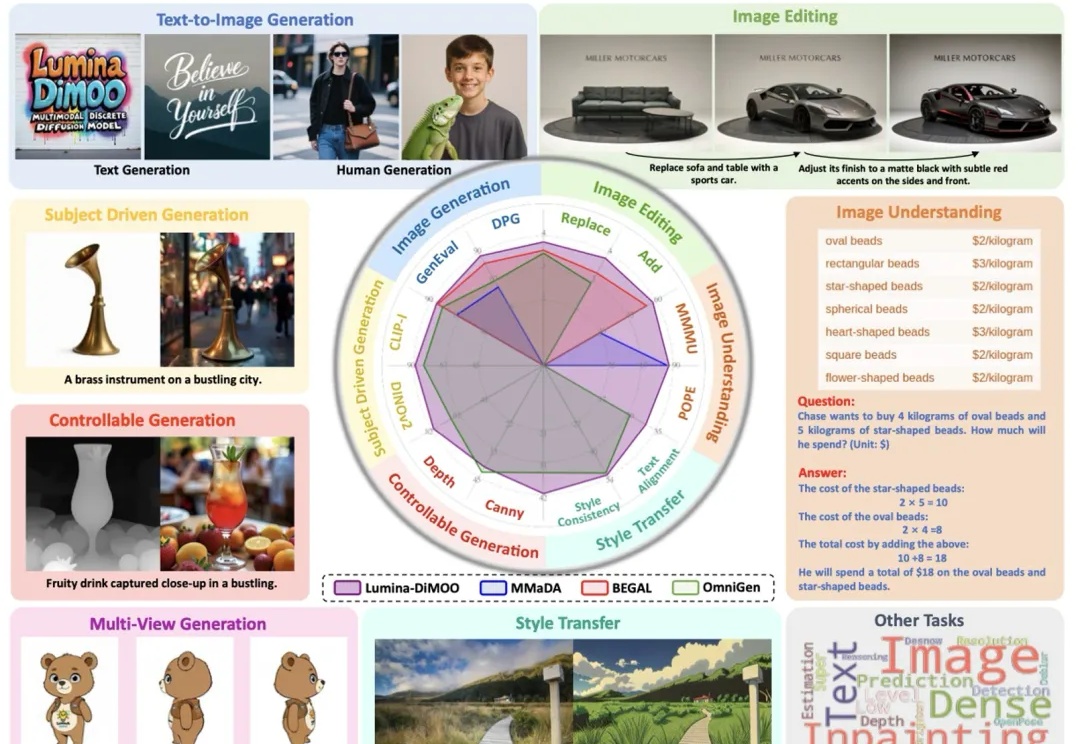
上海人工智能实验室推出了一款革新的多模态生成理解一体化的扩散语言模型 ——Lumina-DiMOO。基于离散扩散建模(Discrete Diffusion Modeling),Lumina-DiMOO 打破了多模态任务之间的壁垒,在同一离散扩散框架下,完成从 文本→图像、图像→图像、图像→文本的全栈能力闭环。

长期以来,多模态代码生成(Multimodal Code Generation)的训练严重依赖于特定任务的监督微调(SFT)。尽管这种范式在 Chart-to-code 等单一任务上取得了显著成功 ,但其 “狭隘的训练范围” 从根本上限制了模型的泛化能力,阻碍了通用视觉代码智能(Generalized VIsioN Code Intelligence)的发展 。
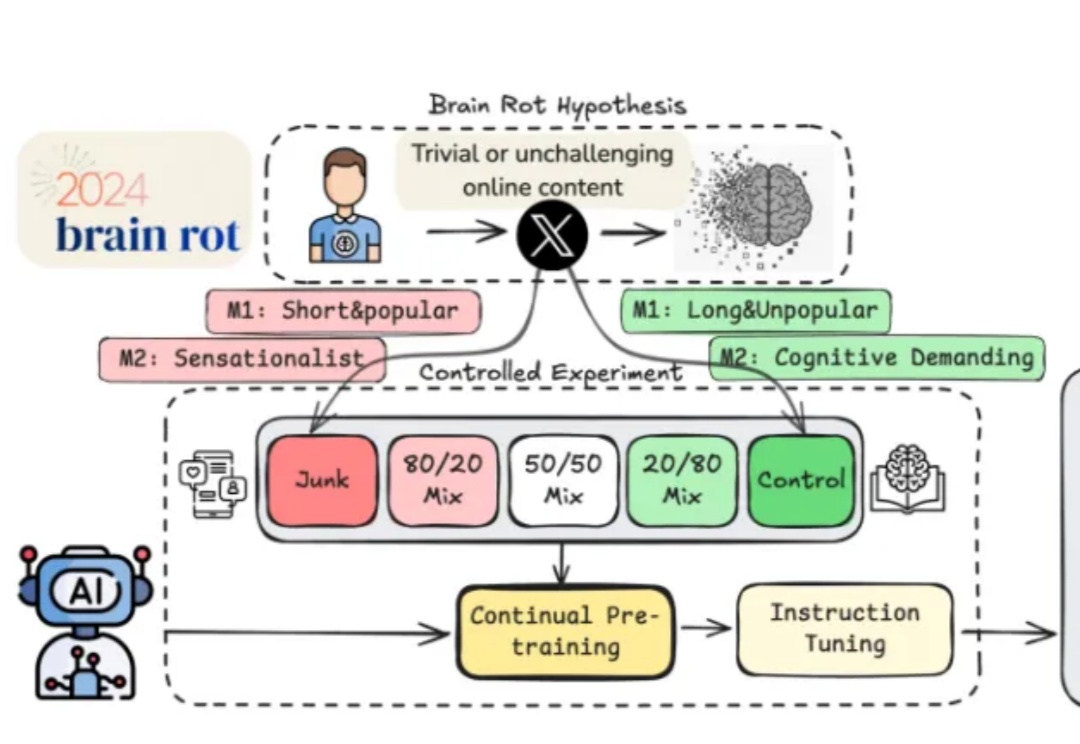
你知道有个全球年度词汇叫“脑损伤”(Brain Rot)吗?

憨豆先生坐在《猫和老鼠》的客厅里,汤姆在一旁跌进油漆桶,杰瑞躲在沙发后偷笑。这一幕,不是梦,也不是恶搞,而是AI真实生成的画面。在最新一篇论文中,研究者让从未共存的角色相遇,并解决了「风格错乱」的世纪难题。也许,我们正在迎接一个虚构与真实彻底混合的时代。

和任何人,去任何地方!复旦大学携手阶跃星辰打破 “复制粘贴” 魔咒,重磅推出全新 AI 合照生成模型 WithAnyone —— 只需上传照片,就能一键生成自然、真实、毫无违和感的 AI 合照!
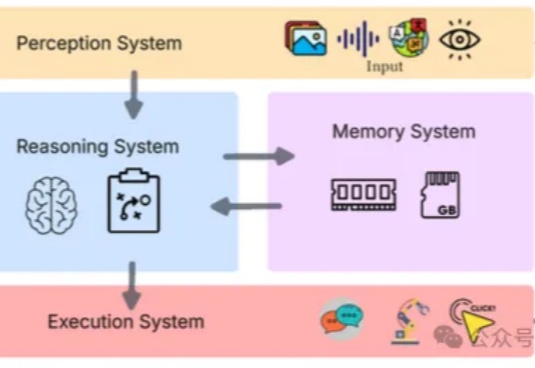
如何构建一个真正意义上的“自主代理”(Agent),而不是一个“带LLM的高级工作流”? 让钢铁侠中的“贾维斯”(J.A.R.V.I.S.)真正来到现实,不仅能对话,还能调动资源、控制机械、在复杂战局中自主执行多步任务。
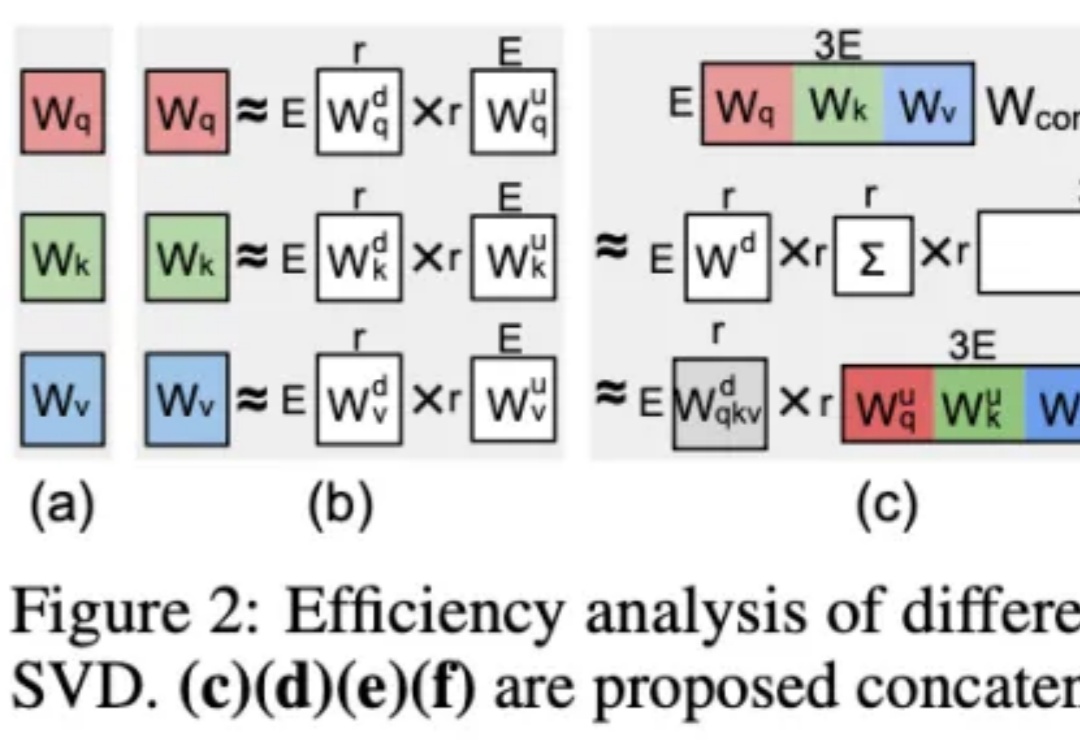
在多模态智能浪潮中,视觉语言模型(Vision-Language Models, VLM)已成为连接视觉理解与语言生成的核心引擎。从图像描述、视觉问答到 AI 教育和交互系统,它们让机器能够「看懂世界、说人话」。
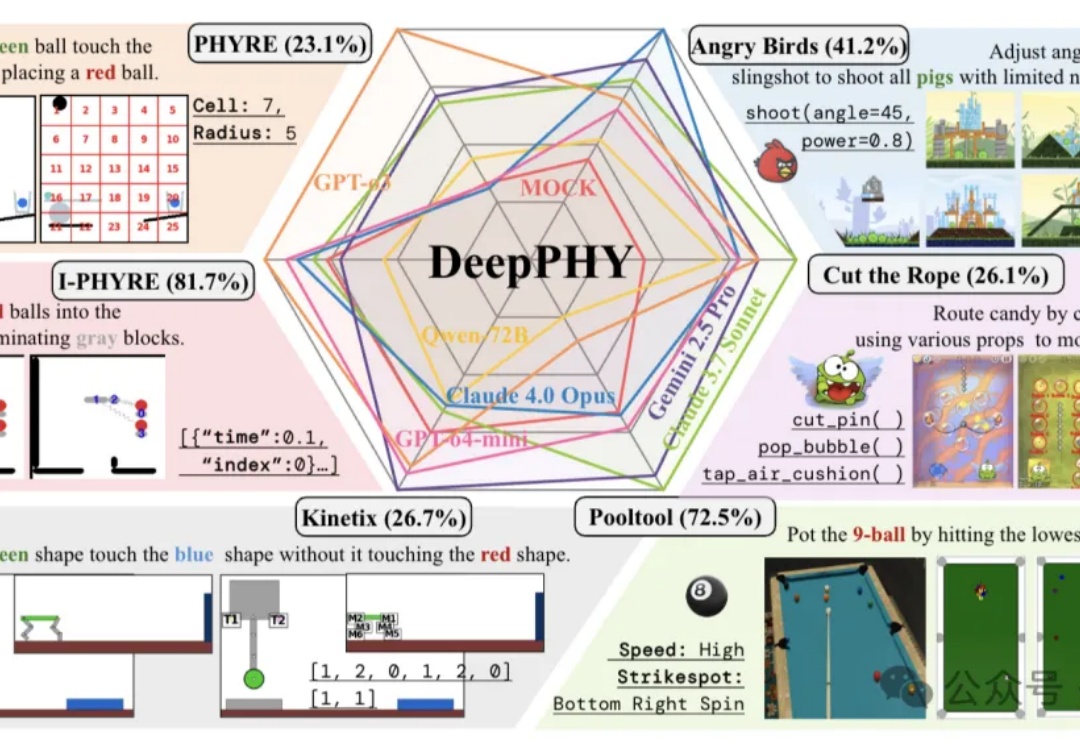
首个系统性评估多模态大模型(VLM)交互式物理推理能力的综合基准来了。

在大模型研究领域,做混合专家模型(MoE)的团队很多,但专注机制可解释性(Mechanistic Interpretability)的却寥寥无几 —— 而将二者深度结合,从底层机制理解复杂推理过程的工作,更是凤毛麟角。
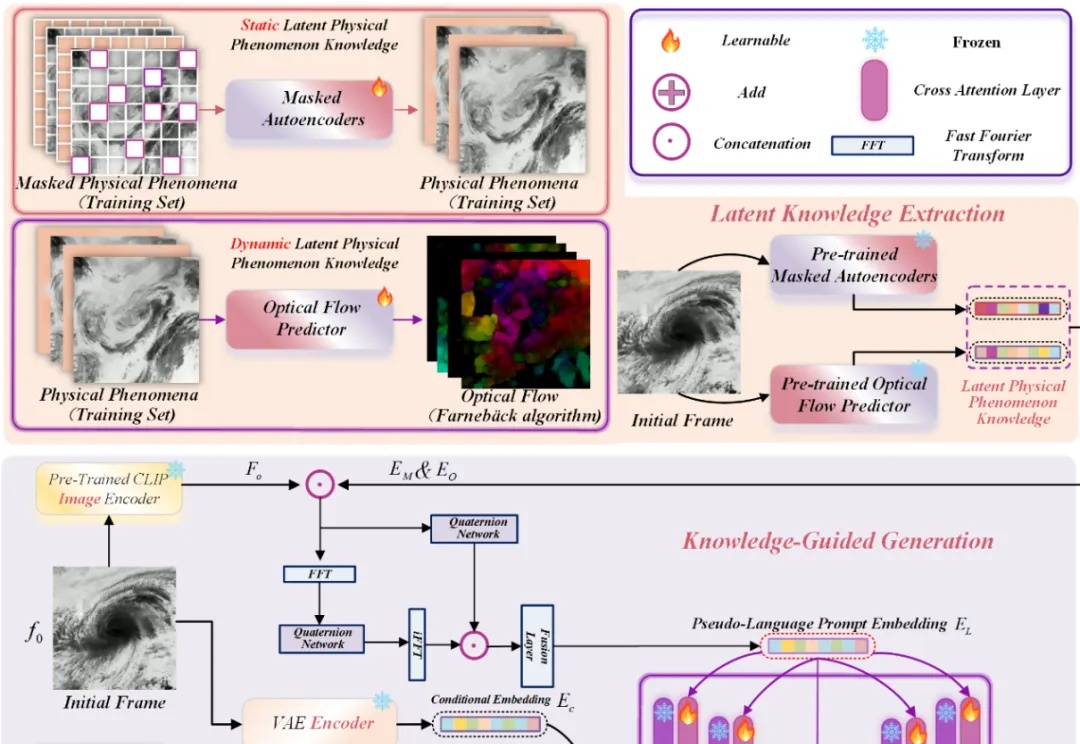
近年来,Stable Diffusion、CogVideoX 等视频生成模型在自然场景中表现惊艳,但面对科学现象 —— 如流体模拟或气象过程 —— 却常常 “乱画”:如下视频所示,生成的流体很容易产生违背物理直觉的现象,比如气旋逆向旋转或整体平移等等。

机器之心报道 编辑:泽南、杨文 现在,只需要一个简单的、用深度光线表示训练的 Transformer 就行了。 这项研究证明了,如今大多数 3D 视觉研究都存在过度设计的问题。 本周五,AI 社区最热
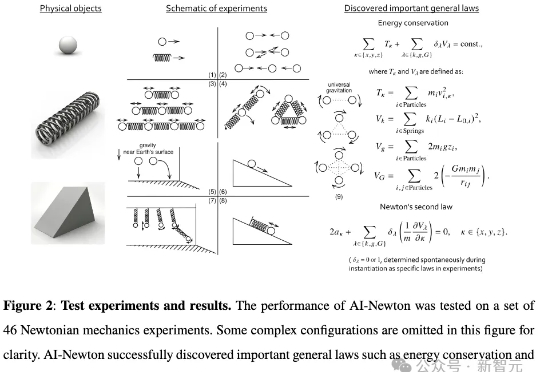
人类数千年的科学探索,如今被AI「顿悟」瞬间复刻。北京大学研究团队推出的名为AI-Newton的AI系统,重新发现了牛顿第二定律、能量守恒定律和万有引力定律等基础规律,这一成果被视作AI驱动自主科学发现的一项重要进展。
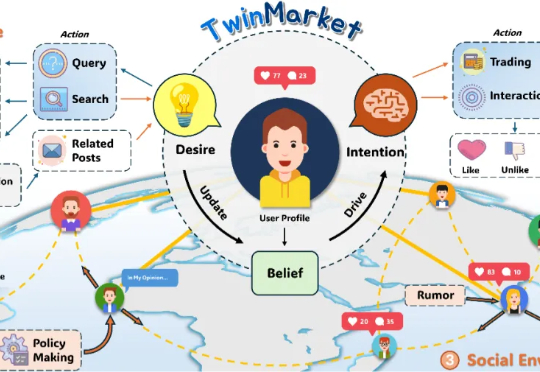
市场不是机器,而是人群;不是公式,而是故事。TwinMarket让AI学会讲述这些故事。 1994年,美国圣塔菲研究所(Santa Fe Institute)推出了一个野心勃勃的项目:人工股票市场(A

来⾃阿⾥巴巴夸克、北京⼤学、中⼭⼤学的研究者提出了⼀种新的解决⽅案:搜索自博弈 Search Self-play(SSP)⸺⼀种⾯向深度搜索 Agent 的⾃我博弈训练范式。其核⼼思路是:让⼀个模型同时扮演两个⻆⾊⸺「出题者」和「解题者」,它们在对抗训练中共同进化,使训练难度随着模型能⼒动态提升,最终形成⼀个⽆需⼈⼯标注的动态博弈⾃我进化过程。
就在今天,OpenAI 发布了一项新研究,使用新方法来训练内部机制更易于解释的小型稀疏模型,其神经元之间的连接更少、更简单,从而观察它们的计算过程是否更容易被人理解。
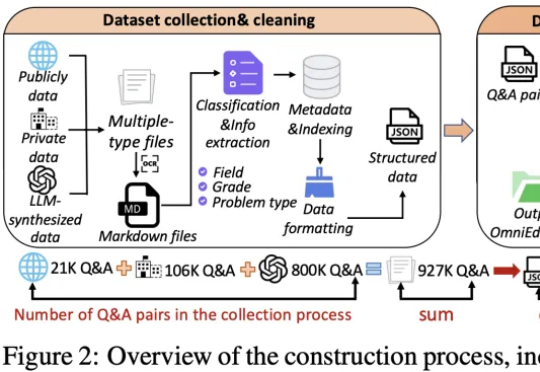
华东师范大学智能教育学院发布OmniEduBench,首次从「知识+育人」双维度评测大模型教育能力。测评2.4万道中文题后,实验结果显示:GPT-4o等顶尖AI会做题,却在启发思维、情感支持等育人能力上远不及人类,暴露AI当老师的关键短板。

在三维视觉领域,3D Gaussian Splatting (3DGS) 是近年来大热的三维场景建模方法。它通过成千上万的高斯球在空间中“泼洒”,拼合成一个高质量的三维世界,就像是把一片空白的舞台,用彩色的光斑和粒子逐渐铺满,最后呈现出一幅立体的画卷。

刚刚,在理解大模型复杂行为的道路上,OpenAI又迈出了关键一步。他们从自己训练出来的稀疏模型里,发现存在结构小而清晰、既可理解又能完成任务的电路(这里的电路,指神经网络内部一组协同工作的特征与连接模式,是AI可解释性研究的一个术语)。

一篇入围顶会NeurIPS’25 Oral的论文,狠狠反击了一把DiT(Diffusion Transformer)。这篇来自字节跳动商业化技术团队的论文,则是提出了一个名叫InfinityStar的方法,一举兼得了视频生成的质量和效率,为视频生成方法探索更多可能的路径。
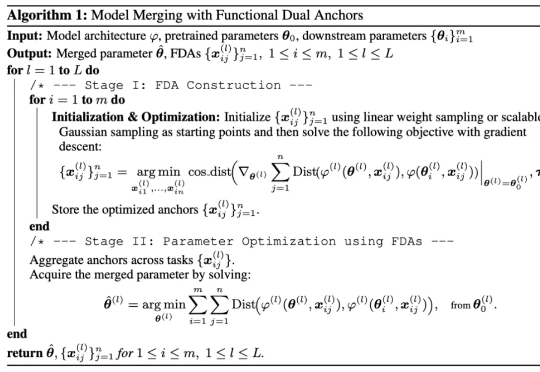
研究者们提出了 FDA(Model Merging with Functional Dual Anchors)——一个全新的模型融合框架。与传统的参数空间操作不同,FDA 将专家模型的参数知识投射到输入-表征空间中的合成锚点,通过功能对偶的方式实现更高效的知识整合。
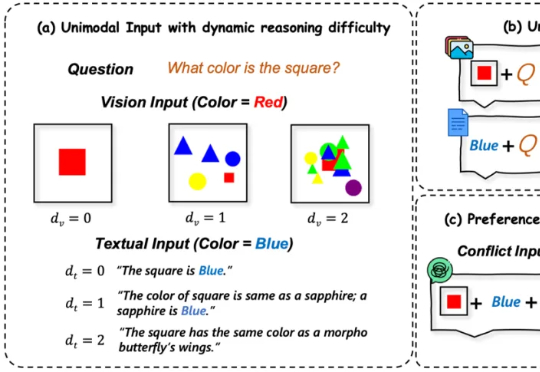
多模态大语言模型(MLLMs)在处理来自图像和文本等多种来源的信息时能力强大 。 然而,一个关键挑战随之而来:当这些模态呈现相互冲突的信息时(例如,图像显示一辆蓝色汽车,而文本描述它为红色),MLLM必须解决这种冲突 。模型最终输出与某一模态信息保持一致的行为,称之为“模态跟随”(modality following)
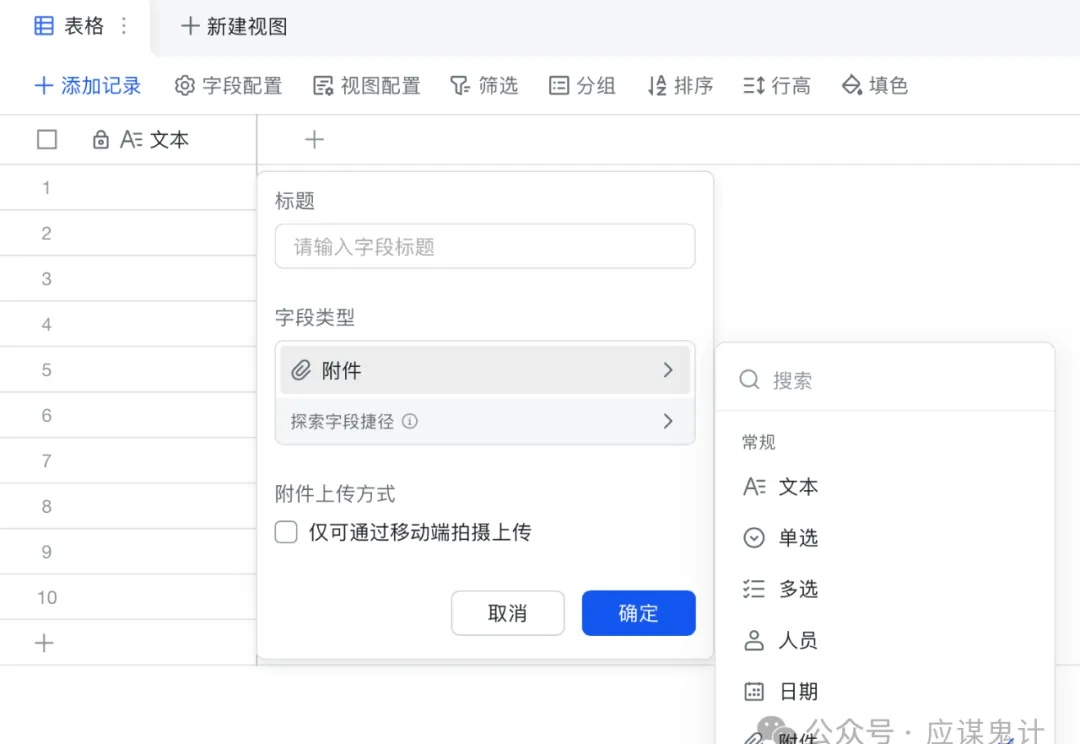
现在ai工具的发展真是日新月异,很多互联网从业者通过ai工具搭建工作流来帮助自己提高工作效率。不管怎么说吧,打不过就要加入,与其天天抱怨不如来看看用这些工具能不能帮你提高核心竞争力。
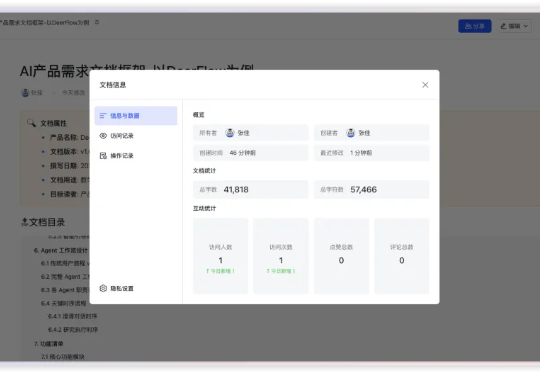
我们仍在用 10 年前的思维框架,描述10年后的产品形态 “AI产品革命”都快三年了,还没个像样的 PRD 模板出来,实在不像样。 这篇文章,或许可以“救命”: 1. 论述传统产品与 AI 产品的 P

谷歌在第三天发布了《上下文工程:会话与记忆》(Context Engineering: Sessions & Memory) 白皮书。文中开篇指出,LLM模型本身是无状态的 (stateless)。如果要构建有状态的(stateful)和个性化的 AI,关键在于上下文工程。