Claude最强模型没那么神话,DeepSeek R1也能找到「大 bug」
Claude最强模型没那么神话,DeepSeek R1也能找到「大 bug」上周 Anthropic 发布 Mythos Preview 的时候,安全圈的反应可以用一个词概括:震惊。
来自主题: AI资讯
10329 点击 2026-04-16 11:17
 搜索
搜索
上周 Anthropic 发布 Mythos Preview 的时候,安全圈的反应可以用一个词概括:震惊。

当大模型训练进入深水区,竞争的关键已经不再只是「模型参数怎么调」,而逐渐转向一个更核心、也更难系统解决的问题:模型在训练过程中究竟看到了什么数据、以什么比例看到、哪些样本应该被更频繁地学习。

今日,腾讯正式发布并开源混元3D世界模型2.0(HY-World 2.0)。作为一款多模态的世界模型,HY-World 2.0支持文字、图片和视频等形式输入,可自动生成、重建并模拟完整的3D世界。

如果你是一家连年亏损、销售额腰斩、连线下门店都要全部关停的卖鞋公司,你要怎么做才能让公司股价在一天之内原地起飞,暴涨 700%?答案是停止卖鞋,然后大声喊出那五个拥有起死回生魔力的字母:AI+GPU。

当一家成立不到两年、团队规模不过 10 人的创业公司被收购,并在数周内关闭产品、清空数据,这通常不会成为行业关注的焦点。但这一次不同。收购方是 OpenAI,而被收购的,是一家试图用模型重写个人理财方式的初创公司——Hiro Finance。
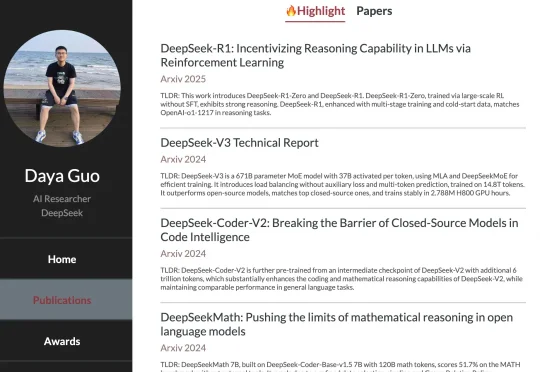
刚刚,图灵联合创始人刘江在海外社交媒体X上透露,DeepSeek核心研究院——郭达雅已加入字节跳动。 郭达雅2023年博士毕业后加入DeepSeek,title是AI Researcher。公开论文显示,从 DeepSeek-Coder、DeepSeek-Math、DeepSeek-Prover、DeepSeek-V3到 DeepSeek-R1,他都出现在核心作者名单中。

Anthropic 正式宣布在 Claude 平台推出身份验证功能。为了防止滥用、落实平台政策及履行法律合规义务,部分用户在访问特定功能或触发平台风控(完整性检查)时,将弹出强制验证提示。Anthropic 要把中国用户往绝路上逼!
今日,阿里ATH事业群旗下首款AI开发工具Meoo(秒悟)来了,可免费体验。这也是ATH发布的首个C端AI产品。妙悟包含网页应用、H5应用、技能创建三大功能板块。

联手波士顿动力,谷歌给机器人装上会读表的脑子。

员工的AI,还是AI的员工?

1997年深蓝下棋,2016年AlphaGo围棋,2026年9个Claude副本做真实科研……每次我们都说「只是特定领域」。这一次,我们真的还能说什么?欢迎来到AI成为科研同事、竞争者、甚至继任者的时代。
「Ising 改变了一切。」

扎克伯格携手Broadcom签下五年长约,自研芯片、GW级数据中心、百亿美元挖人——Meta正式向「人手一个超级智能」的终极目标发起冲锋。

最近这个词实在是太火了。

很多人最近觉得AI行业无聊。偌大一个市场,这么多聪明人,反翻来覆去就两套嗑:
最会做AI工具的人也要来做AI游戏了?

今天这个世界,正在不断放大一种渴望:人们愈发渴望被另一个人真正看见。而这,恰恰是AI治疗师永远无法给予的。
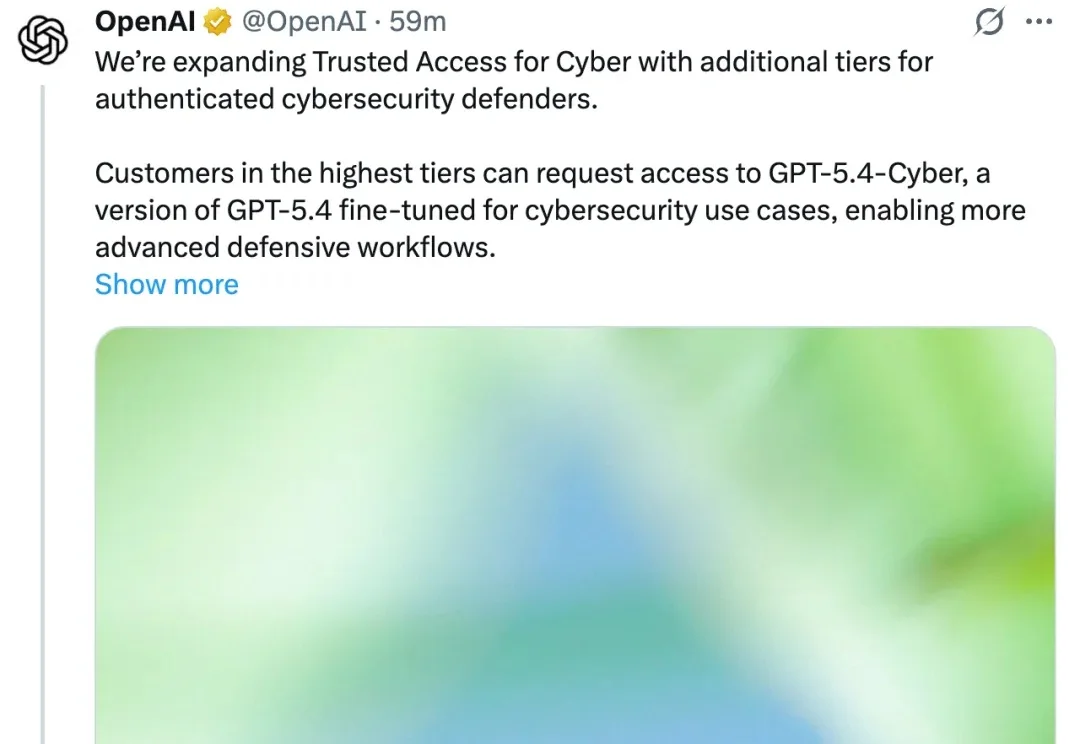
没放出大家伙心心念念的 GPT-5.5 或 GPT-6,OpenAI 刚刚发布了全新的、强调网络安全版本的「GPT-5.4-Cyber」。

当奥特曼两次遇袭后,谷歌 DeepMind 悄悄做了一个反常规的决定:招一位哲学家。这是头部 AI 实验室第一次变相承认,AGI 已经不再只是工程问题。

近日,北京德塔源创智能科技有限公司(简称:德塔智能 Delta Intelligence)宣布完成三轮超亿元融资,由高瓴创投等加注,并引入乐聚、智元、星海图等头部主机厂商战略入局。
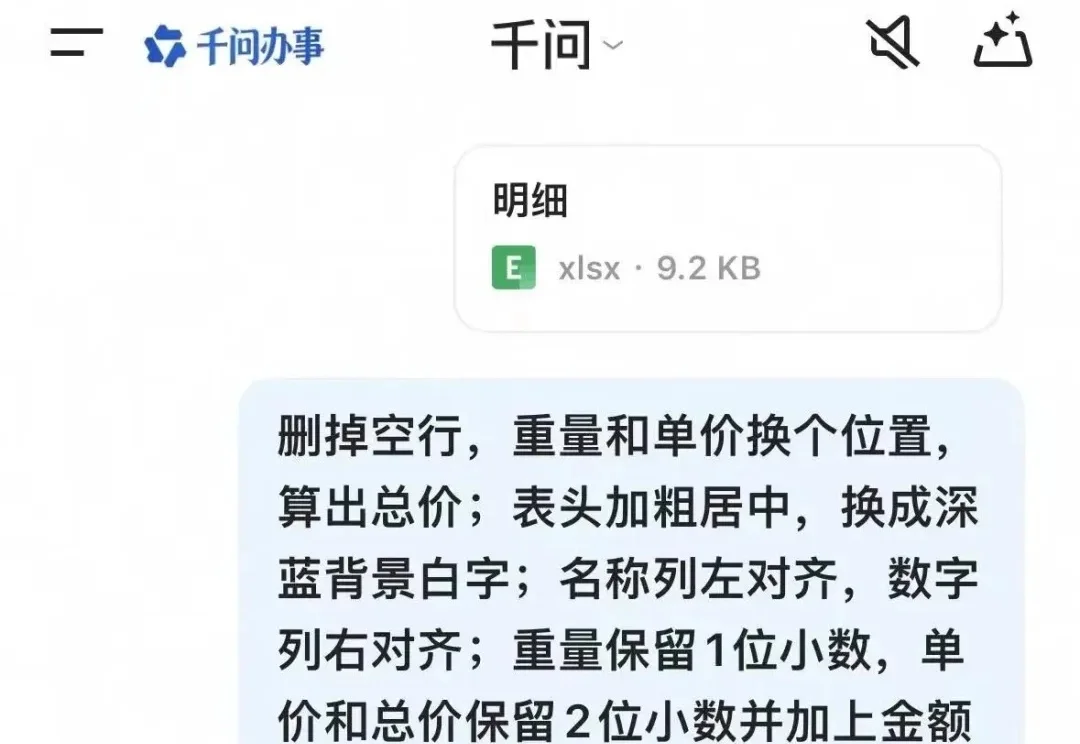
AI做PPT倒是得心应手、形式也五花八门了—— But谁来救救表格人??做Excel简直是当代酷刑……

从「缓存蒸发」到「12倍成本爆炸」,Claude智商一降再降。Anthropic辩解「不是惩罚是架构耦合」,但数据不会说谎:2月高效缓存让用户爽翻,3月静默回退后人人喊贵。这场隐私与性能的拉锯战,只有用户是真正的输家?
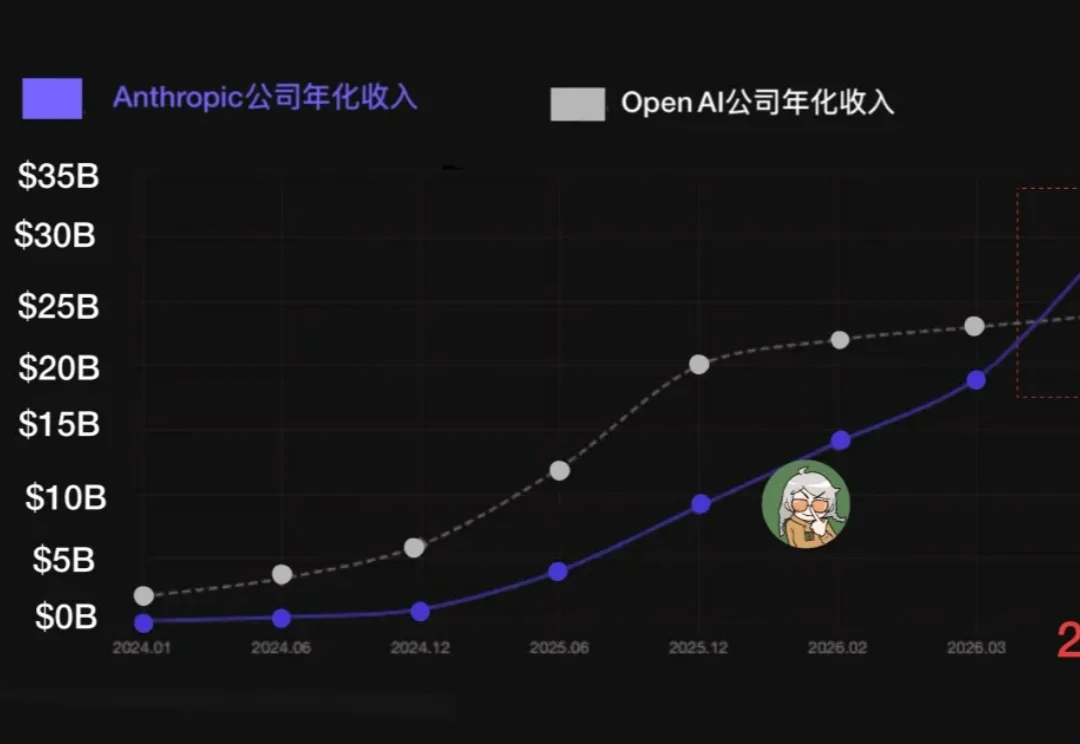
AI行业巨头4月正经历一次"收入增长潮"。
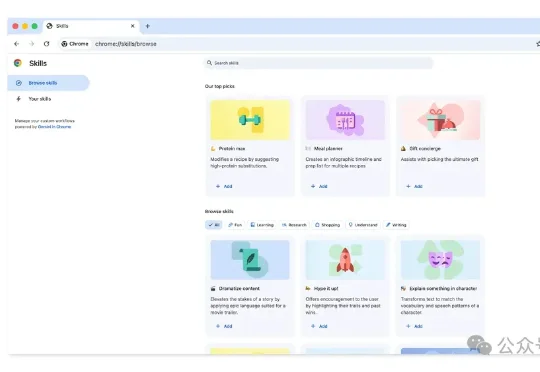
你的浏览器,从今天起进化成免费智能体。谷歌Chrome推出Gemini Skills,一键生成可复用的技能。

港交所官网显示,中科院系AI公司北京中科闻歌已于4月12日正式披露招股书,冲刺“大模型决策第一股”。2025年6月,其以“秘交”方式递表港交所,由中金公司担任独家保荐人。

我们发布了TokenDance 词元跳动,一站式大模型 API 调用平台。希望能够赋能更多观猹生态内的 AI 企业、OPC 开发者与 AI 爱好者,帮助 AI 时代的创造者们,省一些成本,多一些创造。

据外媒The Information曝料,微软近期刚刚重组了Copilot工程团队,并计划靠“龙虾”(开源AI Agent框架OpenClaw的昵称)逆风翻盘。这一重大组织变革由CEO萨蒂亚·纳德拉(Satya Nadella)亲自操刀,被列为公司“头等优先事项”。他提拔高管并组建了一支12人精锐队伍,计划在Copilot中构建类OpenClaw的AI Agent产品,
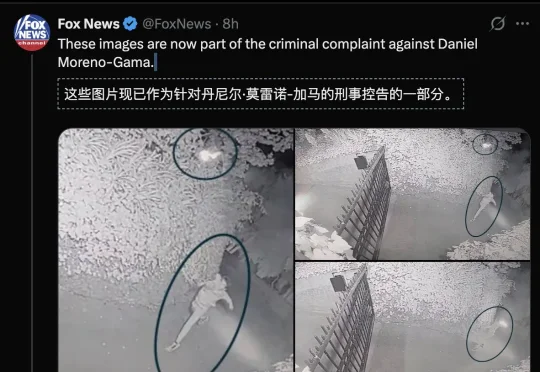
袭击奥特曼住宅的嫌疑犯,已被捕!科幻与现实的界限已模糊:当推动AI的人加速狂奔,恐惧AI的人举起火把——这场对抗,才刚刚进入最危险的阶段。

据知情人士透露,一家从哈佛大学独立出来的新型人工智能实验室正在与投资者进行谈判,以筹集约1 亿美元,以追求一项听起来像科幻小说的使命 :"一个人类可以记住一切的世界"。
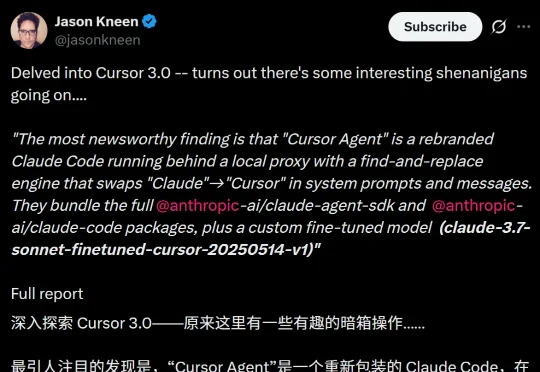
新鲜大瓜!Cursor 3.0实锤套壳Claude Code。当Cursor 3.0被开发者一层层拆开,大家才猛然发现:这场翻车真正刺痛行业的,不是它用了Claude,而是它试图把别人的大脑,包装成自己的灵魂。