
这家中国公司站上国际顶会SIGGRAPH的C位
这家中国公司站上国际顶会SIGGRAPH的C位7 月 19 日至 23 日,美国洛杉矶,SIGGRAPH 2026 如期而至。这场汇聚全球计算机图形学与视觉计算领域顶尖学者、艺术家与工程师的年度盛会,吸引了来自 69 个国家的近万名参会者。渲染、几何建模、动画仿真、与生成式 AI,几乎所有关于如何用计算机创造视觉世界的最前沿探索,都在这五天里集中呈现。
来自主题: AI资讯
7646 点击 2026-07-30 16:38
 搜索
搜索
7 月 19 日至 23 日,美国洛杉矶,SIGGRAPH 2026 如期而至。这场汇聚全球计算机图形学与视觉计算领域顶尖学者、艺术家与工程师的年度盛会,吸引了来自 69 个国家的近万名参会者。渲染、几何建模、动画仿真、与生成式 AI,几乎所有关于如何用计算机创造视觉世界的最前沿探索,都在这五天里集中呈现。
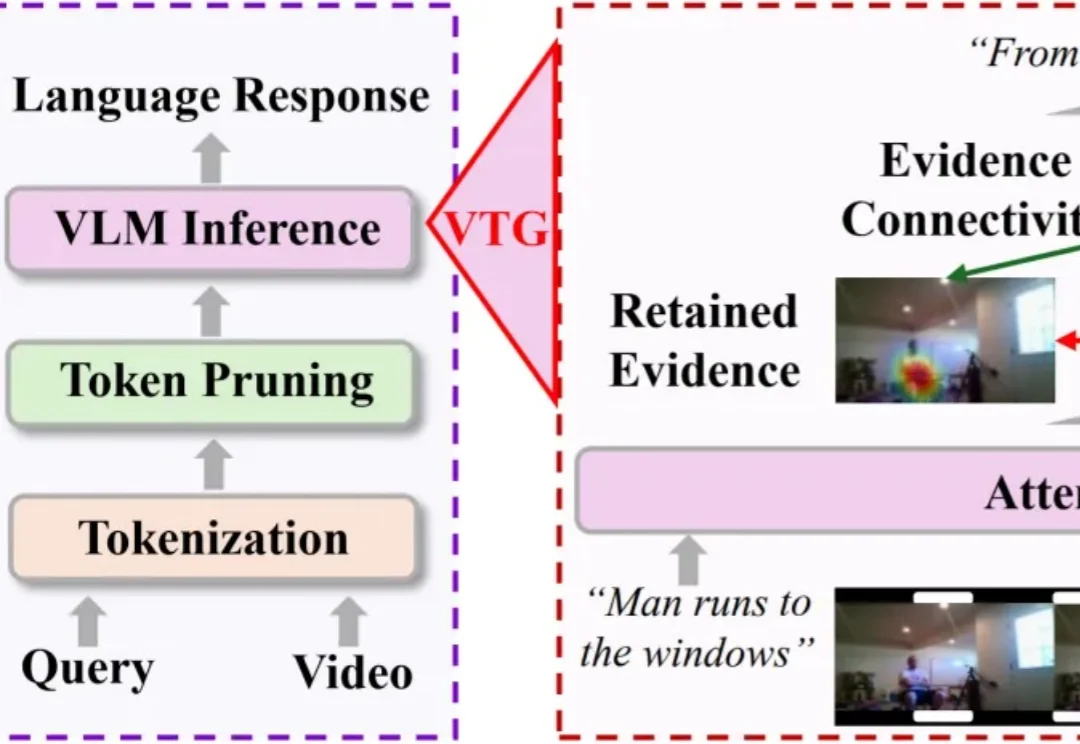
长视频理解,正在成为多模态大模型的重要能力。
过去两年,多模态模型的竞争看起来像一场“造眼睛”的竞赛:更高的图像分辨率、更多的视觉 token、更大的模型,以及更昂贵的训练。行业似乎默认,只要第一次看得足够清楚,AI 就能从“看见”抵达“洞见”。
Sable是全球领先的AI员工服务商,核心打造Aidan全场景智能AI员工,依托计算机操作、视觉识别、语音交互技术,助力企业实现客户互动、产品服务、前端业务的智能化、规模化落地,赋能企业优化人力效能、降本增效。

Z Potentials 获悉,AI多模态内容互动娱乐社区海艺近期完成超亿元人民币B轮融资,由视觉中国、华盖创赢、祥峰投资联合领投,广发信德、天投资本、川创投、广州合伟永晟参与。

近日,全球化AI互动娱乐平台海艺(SeaArt)宣布完成超亿元B轮融资。本轮融资由视觉中国、华盖创赢、祥峰投资联合领投,广发信德、天投资本、川创投、广州合伟永晟跟投。此前海艺曾获阿里、腾讯、招银国际、钟鼎资本、Actoz、上海人工智能产业系列基金、和溋资本等知名产业基金和财务投资机构加持。

独家获悉,近期,腾讯混元多模态理解负责人胡瀚提出了离职。此前,他曾担任微软亚洲研究院视觉计算组首席研究员。2025年初加入腾讯后,负责视觉大模型的研究。在后续的调整中,他加入大语言模型部旗下的“Frontier”前沿技术研究组,负责多模态理解的相关研究,汇报给姚顺雨。

国防科技大学虚拟现实与视觉计算团队(SAW Lab)联合先进制导与控制技术国家级重点实验室等推出面向航拍几何 3D 视觉的统一大规模数据集与评测基准 「AirZoo」。
嗨大家好!我是阿真! 刷短视频就是这点不好,上次看到一个 AI 视频拆解分析的教程,感觉很有意思,刷完了过两天忘记在哪里刷的了。

袁博地的答案是否定的。从清华大学接触计算机视觉,到 UC Berkeley 攻读 AI 博士,再到 Google X 负责机器人的视觉系统,袁博地过去十多年的研究几乎始终围绕 Pixel 展开:从图像识别,到 GAN、Diffusion,再到图像和视频生成,技术范式不断变化,研究对象却始终指向同一件事——如何让机器理解和生成视觉世界。