
GPT-5.6攻克25年量子信息难题,人类学者连夜「像素级」洗AI稿发论文
GPT-5.6攻克25年量子信息难题,人类学者连夜「像素级」洗AI稿发论文7 月 23 日,量子信息领域一道悬了 25 年的难题,还是在同一天出现了两份独立证明!
来自主题: AI资讯
9000 点击 2026-07-27 11:31
 搜索
搜索
7 月 23 日,量子信息领域一道悬了 25 年的难题,还是在同一天出现了两份独立证明!

7 月 24 日,Claude Opus 5 上线。几个小时之内,我看到各家媒体把这个模型的评测成绩转载了一轮,而更值得留意的是 Anthropic 内部人员当天发出的一条推文。
近日,蔡浩宇创立的AI公司Anuttacon发布公告,宣布旗下AI陪伴产品AnuNeko将于太平洋时间2026年7月29日23时59分正式停止运营。届时,应用及全部聊天记录都将无法访问,用户数据也会按照隐私政策永久删除。

新智元报道 AI第一次拿起彩铅画蒙娜丽莎,但发生了一件奇怪的事: 没有任何一个模型的最终作品,赢过它自己中途最好那版:它们总在最好的时候改过了头。 而且,同样是7幅画,成本相差了20倍! 最左为原作,

越来越多体育明星开始投资科技公司。 2026年7月19日,美加墨世界杯决赛落幕,西班牙击败阿根廷夺冠,39岁的梅西以亚军身份告别了世界杯舞台。 但这场比赛之后,人们讨论得最多的不是比分,而是一条来自硅

今年 6 月,Google DeepMind 宣布与电影公司 A24 建立长期研究合作,并向其投资约 7500 万美元。成立于 2012 年的 A24,以开发独具文艺气息的小众电影见长。它的代表作包括奥斯卡最佳影片《月光男孩》和《瞬息全宇宙》、全球票房大卖的《至尊马蒂》,以及今年热映的恐怖片《后室》。14 年间,A24 早已把片厂名字做成品牌:A24 三个字,本身就是人气的保证。

7月16日,Nature刊出消息:科学家用AI造出了自然界里从来没有过的CRISPR酶,切基因比「天然版本」更利索。论文同日发表在Science。带队的人,是2020年因为CRISPR拿下诺贝尔化学奖的Jennifer Doudna。

近日,专注于第二代人工智能制药技术的元示科技有限公司完成近亿元最新一轮融资。公司由北京大学前沿交叉学科研究院2017级博士吴佳奇创立,核心研发方向为人工智能虚拟细胞与通用细胞大模型,是国内较早布局细胞级AI药物研发的初创团队。
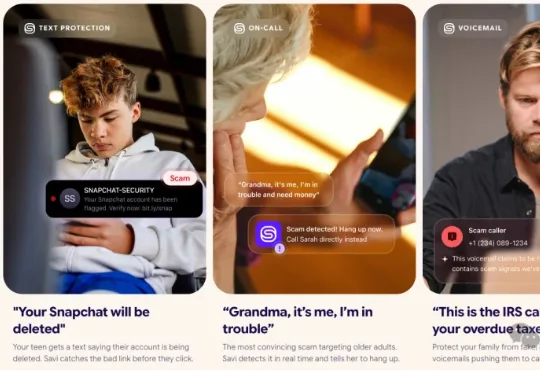
两年前,Patrick Coughlin 的母亲接到了一通电话,来电显示是女儿的号码,电话里也出现了女儿的声音。随后,一名男子声称绑架了她,要求立即支付 1200 美元,否则就会在当地一家沃尔玛的停车场伤害她。

语核科技创始人翟星吉说,AI项目一定是高层驱动的,但真正主导的是业务部门。他的逻辑很值得琢磨:大部分公司买一个Agent产品,本质上不是买软件,是在做生产投资——就像制造业企业投资一条产线,买的是高级人力服务。 所以决策链路变成了:业务部门真的算出ROI,跑去跟老板说"这东西能帮我们提升产值或者降低成本",老板说"赶紧买"。