
坏了!R1的秘密被Deepmind发现了!「啊哈时刻」首次被披露,现已可量化!
坏了!R1的秘密被Deepmind发现了!「啊哈时刻」首次被披露,现已可量化!自年初起,DeepSeek-R1、OpenAI o3、Qwen3等推理模型相继问世,展现出令人惊叹的智能水平,但它们为什么突然变得这么聪明?东京大学联合Google DeepMind的研究者们终于找到了答案。
来自主题: AI资讯
7949 点击 2025-06-21 13:01
 搜索
搜索
自年初起,DeepSeek-R1、OpenAI o3、Qwen3等推理模型相继问世,展现出令人惊叹的智能水平,但它们为什么突然变得这么聪明?东京大学联合Google DeepMind的研究者们终于找到了答案。

DeepSeek兄弟!事态紧急,生死攸关! 我来自大唐盛世,身为朝廷「荔枝史」,刚接到圣旨——皇上龙颜大悦,突然想尝尝岭南的新鲜荔枝!这可是天大的恩宠,也是致命的考验!

微信和游戏业务正在为腾讯AI应用战略的实施提供更广阔的战略纵深。抓住DeepSeek带来的契机扭转AI领域的竞争态势之后,腾讯围绕AI应用的布局正在快速深化。
42,这个来自《银河系漫游指南》的「生命、宇宙以及一切问题的终极答案」已经成为一个尽人皆知的数字梗,似乎就连 AI 也格外偏好这个数字。
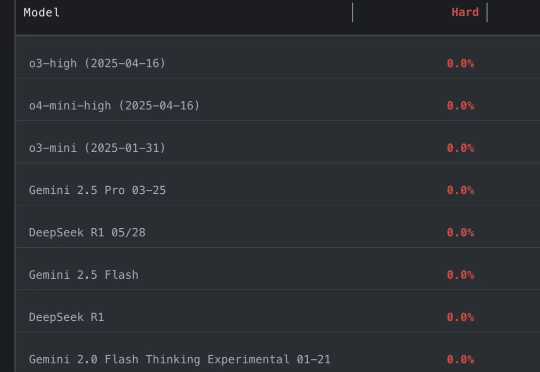
好夸张…… 参赛大模型全军覆没,通通0分。 谢赛宁等人出题,直接把o3、Gemini-2.5-pro、Claude-3.7、DeepSeek-R1一众模型全都难倒。
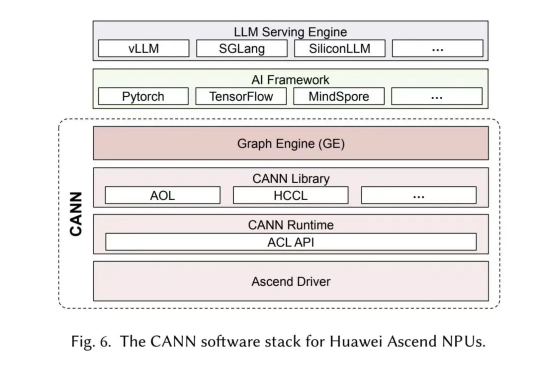
今年 4 月,围绕“华为芯片效率是否超越国际主流 AI 芯片和架构”的问题,网上曾引发一场激烈争论。
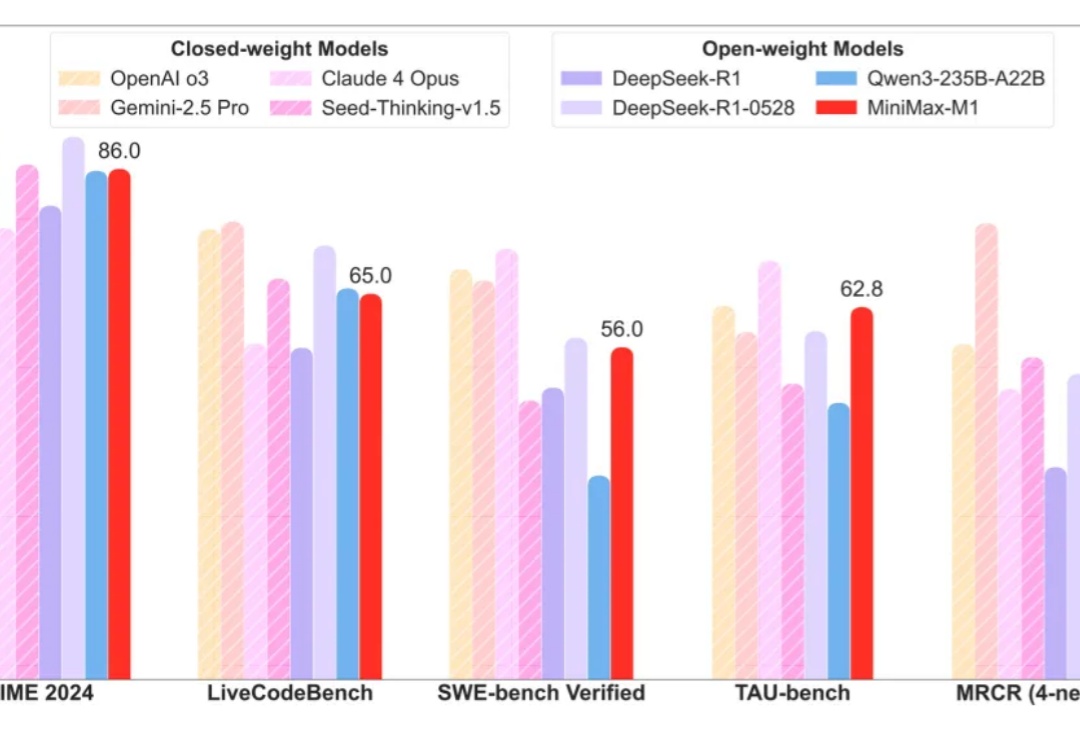
最近,我的AI交流群和别的一些AI群都炸锅了,话题的焦点是MiniMax-M1
昨天深夜,月之暗面发布了开源代码模型Kimi-Dev-72B。这个模型在软件工程任务基准测试SWE-bench Verified上取得了60.4%的成绩,创下开源模型新纪录,超越了包括DeepSeek在内的多个竞争对手。

在开源模型领域,DeepSeek 又带来了惊喜。
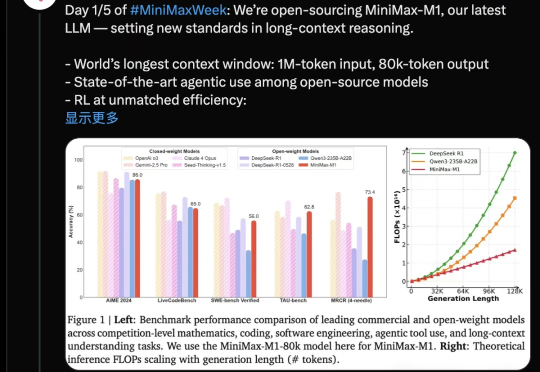
国产推理大模型又有重磅选手。MiniMax开源MiniMax-M1,迅速引起热议。