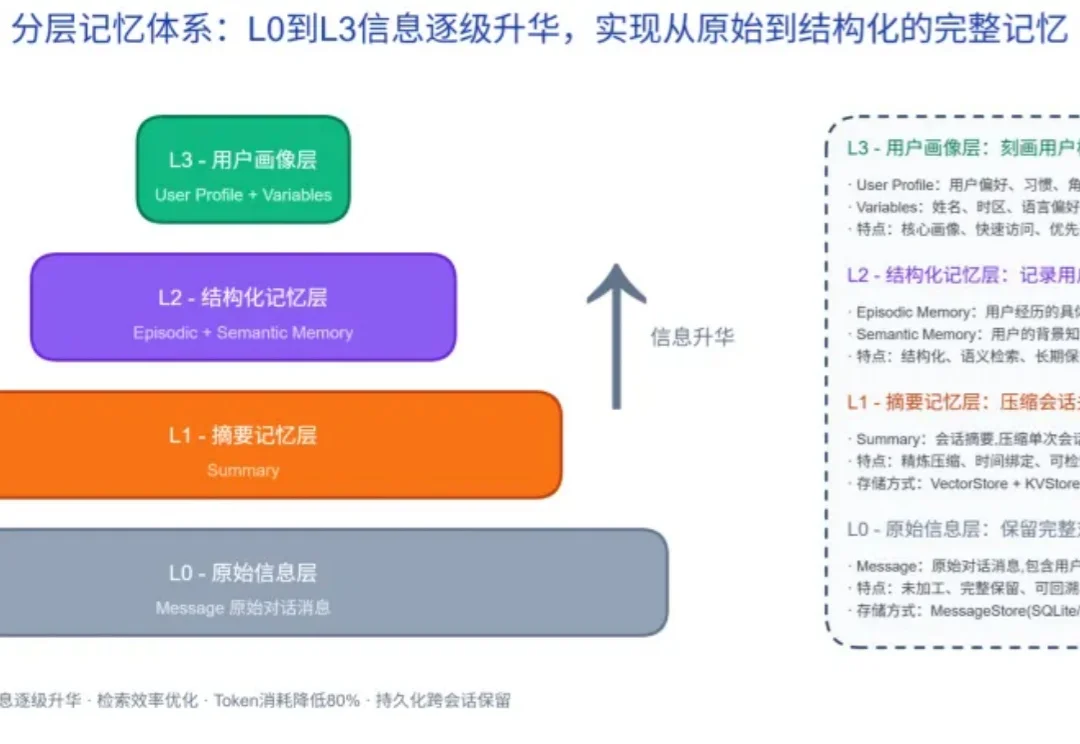
跨会话不再「失忆」:openJiuwen社区开源 AutoGenetic Memory,让Agent记忆自主生长
跨会话不再「失忆」:openJiuwen社区开源 AutoGenetic Memory,让Agent记忆自主生长当大模型应用进入深水区,决定一个 Agent 体验上限的,早已不只是 "答得对不对", 而是 "能不能持续记住同一个人"。
来自主题: AI技术研报
5587 点击 2026-07-02 14:31
 搜索
搜索
当大模型应用进入深水区,决定一个 Agent 体验上限的,早已不只是 "答得对不对", 而是 "能不能持续记住同一个人"。

近日,穗升科技首款产品Memoket在海外正式开启预售。这是一款AI Memory可穿戴硬件,仅11克,分表带款和手环款两种形态,待机超过30天,连续录音续航20小时。它可以将物理世界中所听到的信息结构化,需要时调给Agent,实现跨时间聚合和Context(上下文)串联。

押注 AI 的 Memory Layer。

在做 Agent Memory 工程化探索的这几个月里,我经常有种被概念淹没的窒息。图结构记忆、AutoMemory、做梦机制、各种层出不穷的 Memory 框架……整个技术社区似乎陷入了一种每遇到一个新场景就要发明一套新词汇的群体焦虑中。
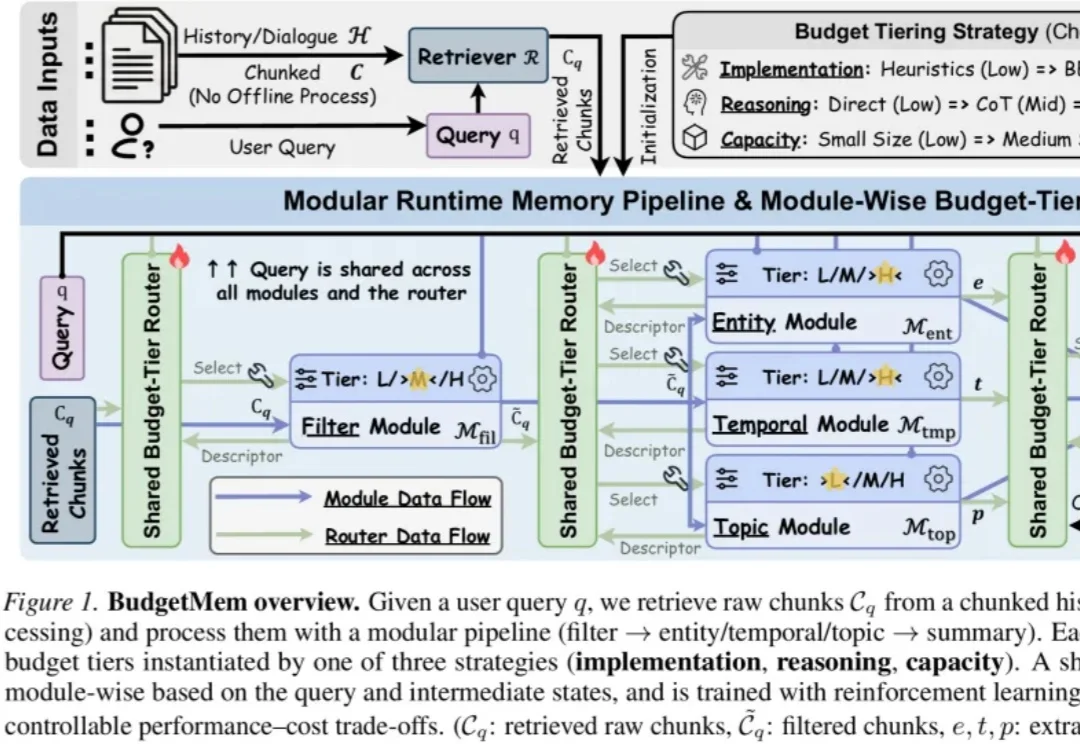
当 LLM Agent 处理长期对话、多轮交互和复杂文档时,Memory 已经成为不可或缺的核心模块。它帮助智能体保存历史、检索信息、维持个性化上下文,并支撑跨时间的推理能力。
某天,老板让你用 Agent 手搓个自动化流程的小工具,你袖子一撸,信心满满地开干。

2026年的AI行业,正在出现一种微妙的变化。

多模态Agent最容易制造的一种错觉是:它看过图片,所以它记住了图片。
TencentDB Agent Memory 全球正式开源

EverMind 想做点不一样的。这家由盛大集团孵化的公司,定位是为所有AI Agent提供一个通用的"记忆层"(Memory Layer)。它的核心产品EverOS是一套开源的长期记忆系统,开发者可以把它接入自己的Agent,让AI不仅能记住用户的历史对话和偏好,还能像人一样对记忆进行整理、更新,甚至从过去的经验中学习和进化。