独家丨世界模型企业知天下完成天使轮融资,要做「中国版World Labs」
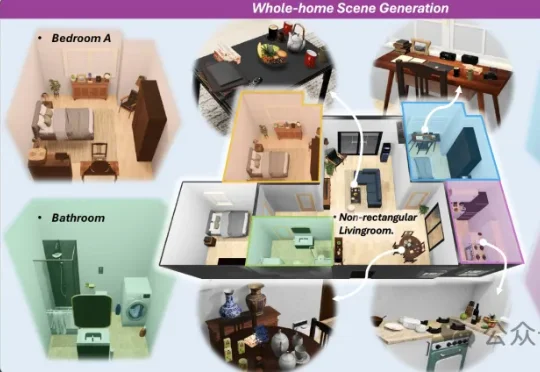
独家丨世界模型企业知天下完成天使轮融资,要做「中国版World Labs」空间智能与世界模型初创公司知天下(苏州)人工智能科技有限公司(以下简称“知天下”)近日已完成天使轮融资。知天下是一家专注于高斯泼溅(3D Gaussian Splatting,简称3DGS)三维重建与生成技术的AI企业,于 2024 年初推出 3DGS 免费重建与发布服务
来自主题: AI资讯
8789 点击 2026-06-08 10:13