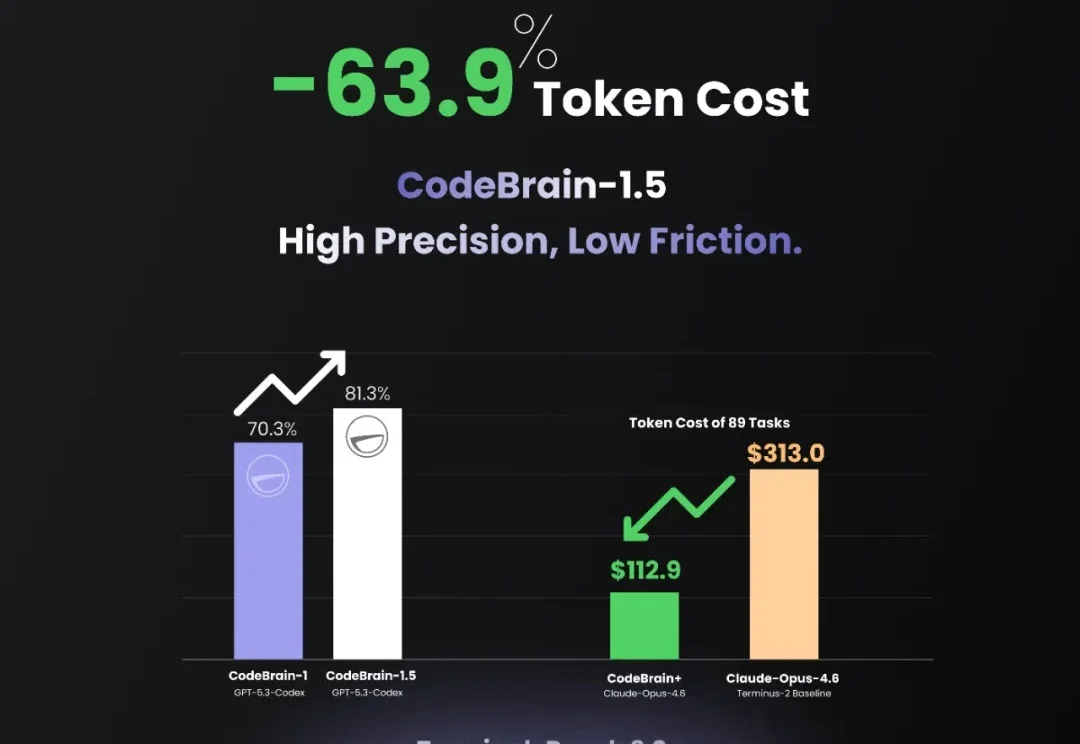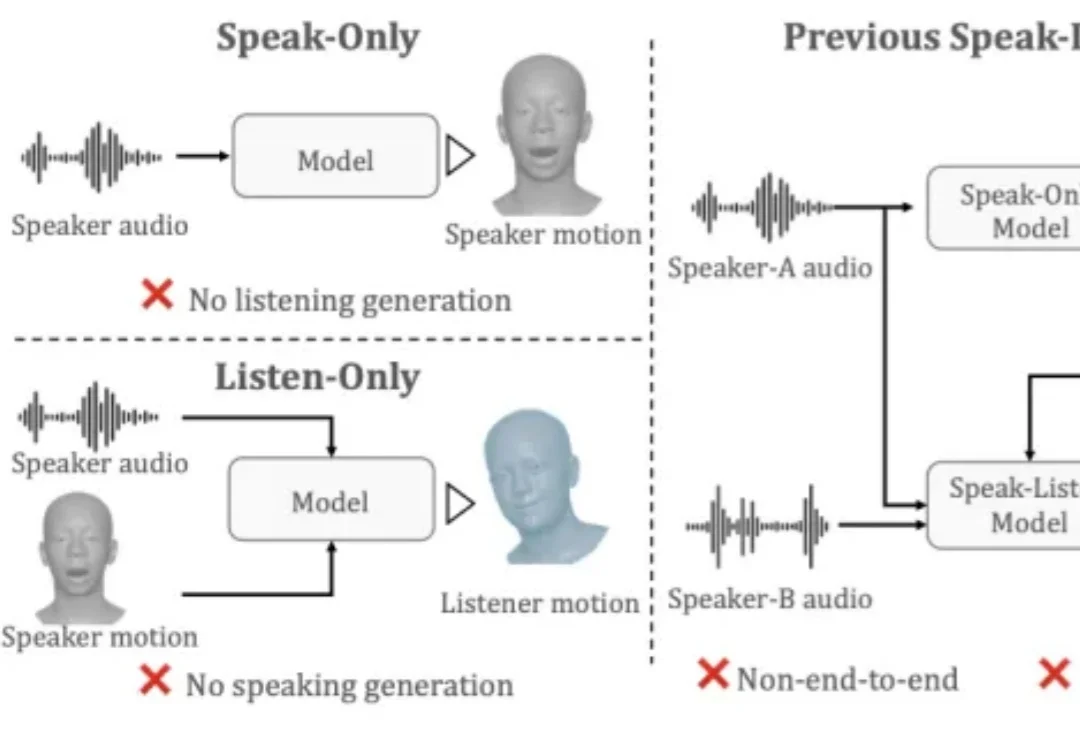
CVPR 2026 | 告别倾听「扑克脸」,UniLS框架来了,刷新数字人对话SOTA
CVPR 2026 | 告别倾听「扑克脸」,UniLS框架来了,刷新数字人对话SOTA在游戏 NPC、虚拟主播、在线客服等数字人对话场景中,倾听时的 “扑克脸” 问题一直是行业长期痛点 —— 虚拟人说话时口型可以做到精准同步,但倾听时却表情僵硬、毫无反应,严重影响对话的自然感和沉浸感。盛大 AI 研究院(东京)与东京大学联合提出 UniLS(Unified Listening and Speaking),首个仅凭双轨音频即可端到端同时驱动说话和倾听面部动作的统一框架。
来自主题: AI技术研报
9803 点击 2026-04-24 09:15