
GPT-5得分不到0.4!法律+金融最大规模基准:1.9万+专家评估准则
GPT-5得分不到0.4!法律+金融最大规模基准:1.9万+专家评估准则最新PRBench基准可以测试AI在金融和法律领域的表现。结果显示,即使是顶尖大模型在处理复杂任务时也表现不佳,尤其在涉及重大经济后果的任务中。PRBench通过模拟真实场景和多轮对话,揭示了AI在专业领域的不足,强调开发更可靠AI系统的重要性。
来自主题: AI技术研报
7678 点击 2025-11-22 11:33
最新PRBench基准可以测试AI在金融和法律领域的表现。结果显示,即使是顶尖大模型在处理复杂任务时也表现不佳,尤其在涉及重大经济后果的任务中。PRBench通过模拟真实场景和多轮对话,揭示了AI在专业领域的不足,强调开发更可靠AI系统的重要性。

“我曾经花了5个月,做了一款没人用的大模型。”去年4月,刘天强期待拿下美国一家快时尚零售公司的大单,为对方开发一款用AI生成产品上身图的B端产品。带着团队干了整整5个月,产品迭代的重要关头,刘天强没等来最后的签单通知,却等来了客户公司被并购、项目中止的消息。

前沿AI竞赛在2025年11月达到高潮。48小时内,谷歌推出Gemini 3 Pro宣称在主要推理基准测试中领先,而OpenAI立即用GPT-5.1-Codex-Max反击,这是一款专门训练用于通过创新"压缩"(compaction)技术自主工作超过24小时的专业编码模型[43]。加上Claude Sonnet 4.5已确立的编码统治地位和激进的安全过滤器,开发者面临前所未有的选择:

近期,《Arc Raiders》宣布即将推出双人合作模式,以及类似《Helldivers 2》的社区任务活动——但在玩家还没来得及为新玩法兴奋之前,这款游戏的开发商 Embark Studios 却陷入了另一场更棘手的争议:再度被曝使用生成式 AI 进行游戏配音。

Google昨天伴随Gemini3.0pro一同发布了他们的AI IDE产品Antigravity《与Gemini 3.0一起发布的AI IDE「Antigravity」究竟有多厉害?》。其震撼性的三位一体全流程Agent体验让无数开发者直呼“Cursor危险了”。

在 AI 时代,若你还在紧盯代码量、执着于全栈工程师的招聘,或者仅凭技术贡献率来评判价值,执着于业务提效的比例而忽略产研价值,你很可能已经被所谓的“常识”困住了脚步。

周末和几个老同学聚了聚。大家都在互联网行业,聊着聊着话题自然绕到 AI。

就在几小时前,Gemini 3.0重磅发布。随着而来的还有其颠覆性的AI原生IDE产品——Antigravity,这不只是一个新工具那么简单。谷歌的这次发布,将三个核心开发工具,AI代理(Agent)、代码编辑器(Editor)和浏览器(Browser) 集成在了一起,构建了由AI驱动、从编码、研究、测试到验证的完整闭环,一举打通了自家的生态。
一年半之前,影眸科技年轻的创始团队去到旧金山,带着还没正式发布的 3D 生成模型 Rodin,在 GDC(游戏开发者大会)上向全球最顶级的游戏开发者们演示 demo。
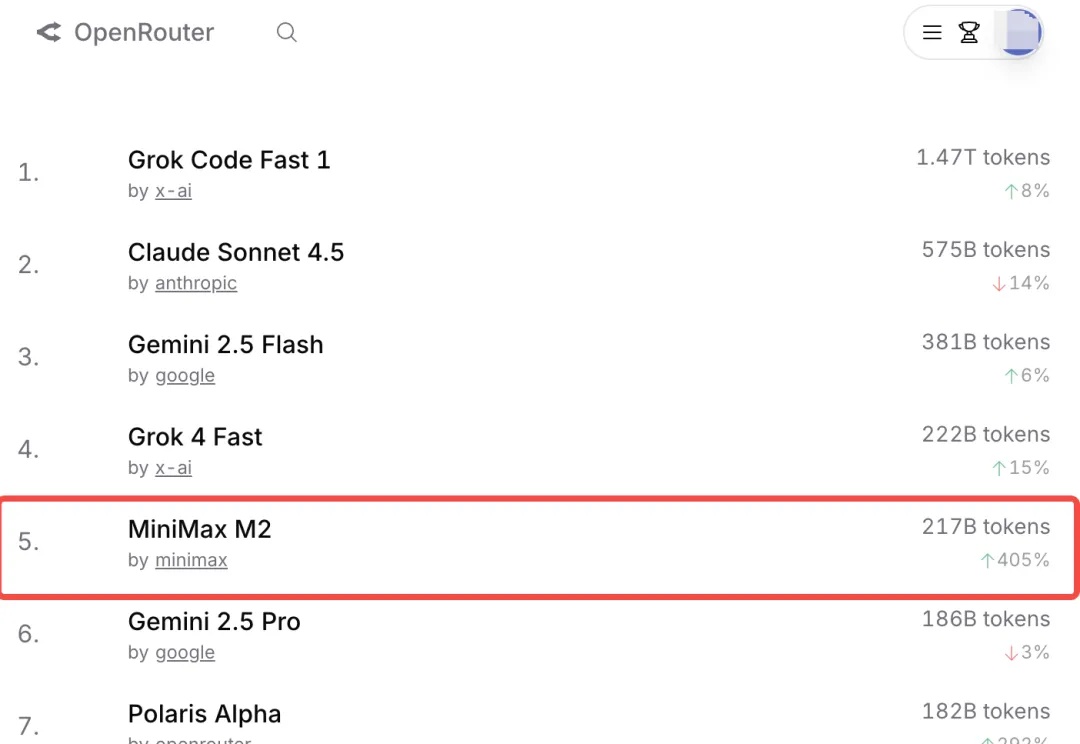
MiniMax,今年真猛。