
C罗刚头球破门,AI解说脱口而出!全模态实时流太狠了
C罗刚头球破门,AI解说脱口而出!全模态实时流太狠了阿里云正式宣布,Apache Flink 3.0全面进入Agentic Streaming For AI时代,并推出全模态数据流处理能力。这是业界第一次,把视频、音频、图像、文本这四类数据,统一放进同一条流式pipeline里调度,让AI能够实时感知、实时理解、实时回应。
来自主题: AI资讯
7755 点击 2026-06-27 12:24
 搜索
搜索
阿里云正式宣布,Apache Flink 3.0全面进入Agentic Streaming For AI时代,并推出全模态数据流处理能力。这是业界第一次,把视频、音频、图像、文本这四类数据,统一放进同一条流式pipeline里调度,让AI能够实时感知、实时理解、实时回应。

当全球具身智能行业还在争论技术路线时,一家中国公司已经率先定义并跑通了自己的答案。深度机智提出的「人类学习」路线——以人类数据为起点、动作建模为中心、机器人为 AI 而生——正在被英伟达、Physical Intelligence 等海外头部机构沿同一方向跟进。
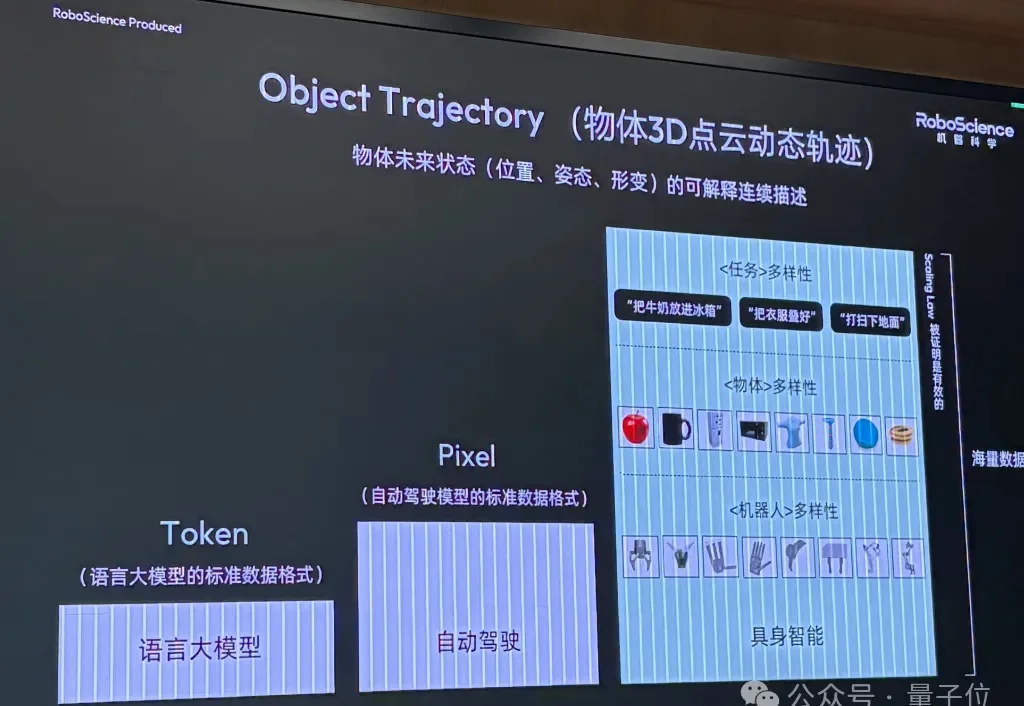
一家刚完成10亿元A轮融资的具身公司,是这么定义具身标准数据格式的: Object Trajectory。

非手机业务目标400亿美元,“飞龙”进入数据中心,高通这次整了个大的。

过去两年,随着 AI 数据中心建设持续加速,光通信开始成为整个 AI 基础设施中增长最快的环节之一。
昨晚,美国开源AI初创公司Reflection AI宣布,已与SpaceXAI签署算力协议,将获得Colossus 2数据中心的额外算力支持,用于训练和迭代更强的开放模型。另据TechCrunch报道,Reflection AI将从2026年7月1日起,每月支付1.5亿美元(约合人民币10.2亿元),

DeNovoSWE是一个用于训练代码智能体从零生成完整仓库的数据集,包含4818个真实任务实例。它通过结构化文档和严格验证机制,帮助智能体掌握复杂系统构建能力,而不仅仅是修复代码。这为代码智能体迈向更高阶的软件工程任务提供了关键支持。
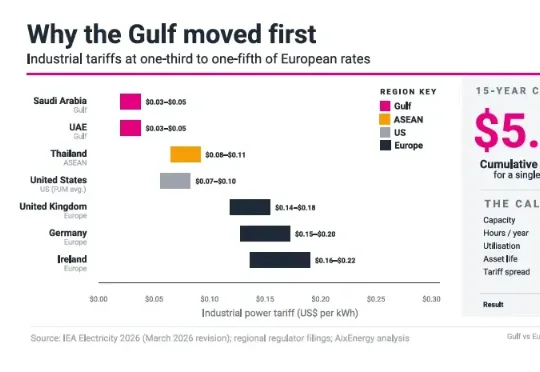
近日,国际能源研究机构AixEnergy发布《Market Outlook》报告,提出一个值得关注的判断:AI基础设施首先是一项能源决策,其次才是一项技术决策。报告认为,决定未来全球AI版图的关键因素,正从芯片、模型和算法,转向稳定、低成本且能够快速接入的能源系统。海湾国家凭借廉价电力迅速崛起,美国受制于电网瓶颈,中国则依托新能源和产业链优势加速布局,东南亚正试图成为新的算力高地。

有这么一组数据,是真真儿地戳到了用Agent这件事的爽点。
依赖于有限机器人数据和大量人类数据,也能让 VLA 模型更稳健吗?