DAG革新时间序列预测,代码、数据、排行榜全开源 | ICML'26
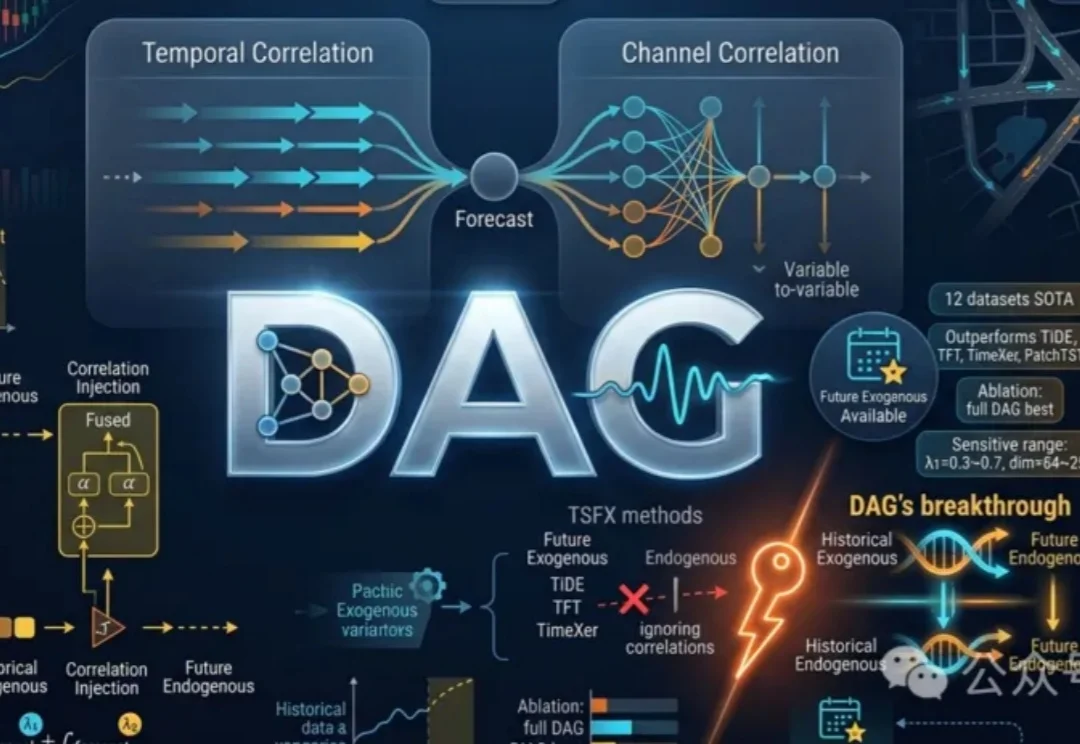
DAG革新时间序列预测,代码、数据、排行榜全开源 | ICML'26DAG框架利用时间与通道双重相关网络,有效整合历史与未来外生变量信息,提升时间序列预测准确性。通过发现并注入相关关系,充分利用未来协变量,显著优于现有方法。
来自主题: AI技术研报
7751 点击 2026-05-18 15:28
 搜索
搜索
DAG框架利用时间与通道双重相关网络,有效整合历史与未来外生变量信息,提升时间序列预测准确性。通过发现并注入相关关系,充分利用未来协变量,显著优于现有方法。
近期,专为Diffusion模型设计的插件框架——Diffusion Templates正式开源发布。这个框架能大幅降低可控生成技术的训练和使用难度,让开发者能够通过丰富的Templates来精准控制模型的生成结果。

为了解决这一问题,来自中山大学和美团的研究团队提出了 X2SAM,一个统一的图像与视频分割多模态大模型框架。它希望让模型不仅能「看懂」图像和视频,还能进一步「指出」目标在每个像素上的准确位置。

阿里巴巴 Z-Image 团队联合香港科技大学、加州大学圣地亚哥分校、香港中文大学等机构提出 D-OPSD(On-Policy Self-Distillation),首个针对少步扩散模型的在线策略自蒸馏框架。D-OPSD 无需奖励模型、无需成对偏好数据,

如果只看这场 Meetup 的嘉宾名单,你大概会先想到海外芯片巨头,或者某家国际 AI 基础设施公司。
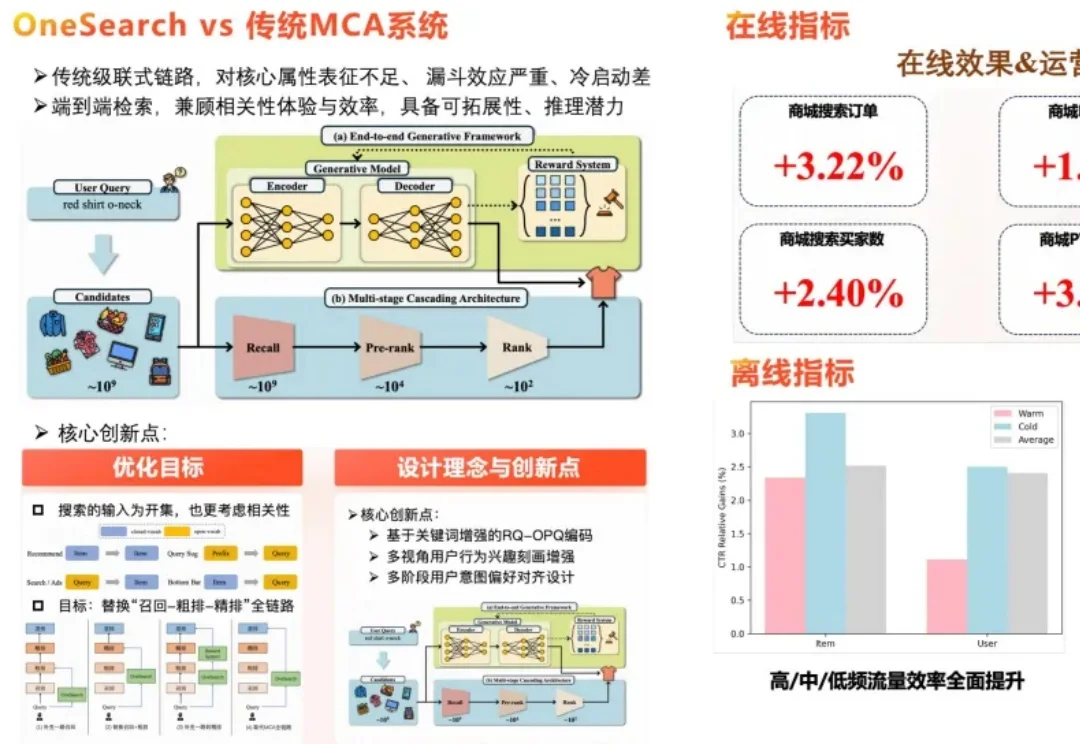
针对生成式检索范式在电商搜索场景下面临的复杂查询理解不足、用户潜在意图挖掘乏力、奖励系统易过拟合历史窄偏好等落地瓶颈,快手技术团队在已规模化部署的工业级生成式搜索框架 OneSearch 基础上,发布了一篇系统性升级的研究论文,正式推出新一代框架 OneSearch-V2。
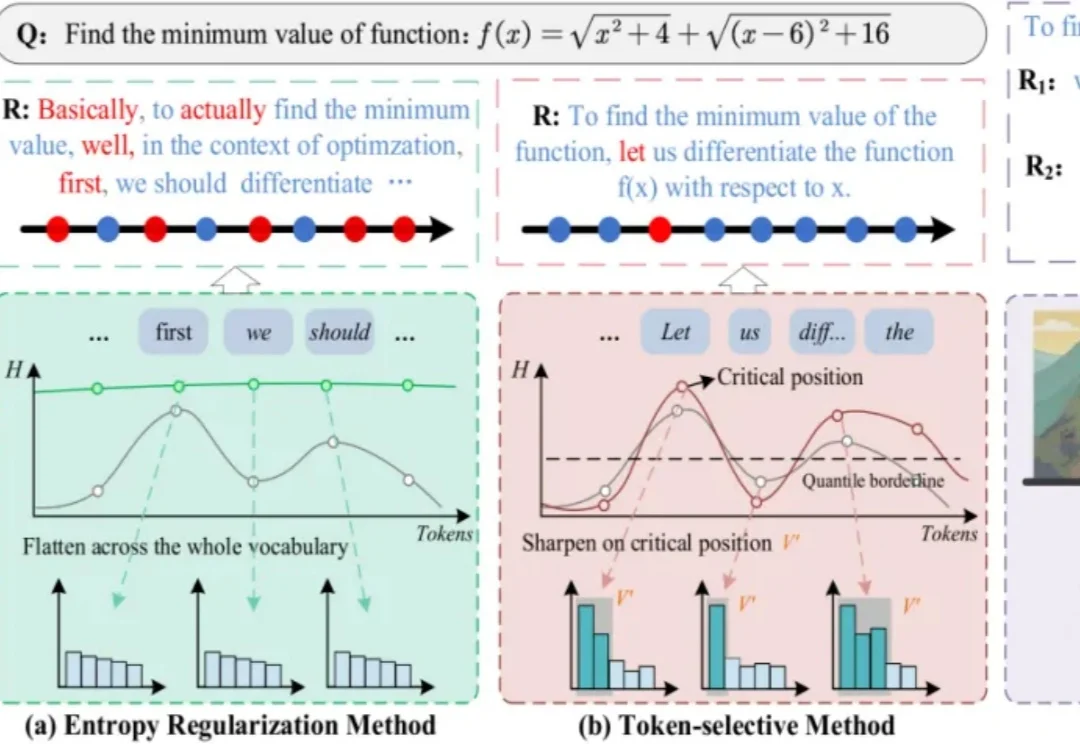
I²B-LPO 是一个面向 RLVR 后训练的探索增强框架,通过改进 rollout 策略引导模型生成更多样化的推理轨迹,将探索行为从 “重复采样” 推进到 “在关键节点生成更具区分度的推理轨迹”,在多个数学基准上同时提升准确率与语义多样性,最高分别达 5.3% 和 7.4%。该工作接收于 ACL 2026 Main,来自阿里达摩院 - 智能决策团队。

一篇让你看懂的AGenUI开源解读

近日,原力灵机开源的具身智能原生框架 Dexbotic 宣布正式支持以 RLinf 作为其分布式强化学习后端。对具身智能开发者而言,这不仅是一次普通的工程适配,更意味着 VLA 模型研发中长期存在的「SFT 与 RL 割裂」问题,正在被真正打通。

近日,由香港科技大学 MMLab 及合作团队完成的研究工作「UniVidX: A Unified Multimodal Framework for Versatile Video Generation via Diffusion Priors」被计算机图形学顶级会议 SIGGRAPH 2026 正式接收。