



OpenAI/微软发布联合声明!事关生死存亡,奥特曼睡不着了
OpenAI/微软发布联合声明!事关生死存亡,奥特曼睡不着了OpenAI与微软发布了非约束性的合作备忘录,重组仍悬而未决。关键在控制权与确定性:多云是否松口、微软能否获取训练细节、以及最关键的AGI条款的去留。这三件事,决
来自主题:
AI资讯
9843 点击 2025-09-13 11:19
OpenAI与微软发布了非约束性的合作备忘录,重组仍悬而未决。关键在控制权与确定性:多云是否松口、微软能否获取训练细节、以及最关键的AGI条款的去留。这三件事,决

游戏新知独家获悉,贺甲已经自主创业,并于 2025 年 3 月成立上海梦熵科技。一位消息人士告诉游戏新知,团队已经拿到一笔融资,团队规模尚小。其合作伙伴中有一位成逸宁,疑似为前 Unity 大中华区影视动画总监,有近 20 年的影视动画行业经验。
Ditto是一个由伯克利辍学生Allen Wang和Eric Liu创立的人工智能约会平台,已筹集了160万美元,Allen Wang在4月通过Linkedin宣布,以“杀死Tinder为使命”的Ditto AI已拿到来自Google的200万美元融资。
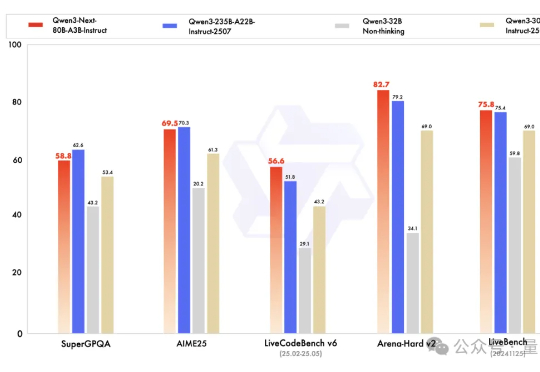
Qwen下一代模型架构,抢先来袭! Qwen3-Next发布,Qwen团队负责人林俊旸说,这就是Qwen3.5的抢先预览版。 基于Qwen3-Next,团队先开源了Qwen3-Next-80B-A3B-Base。

为大模型开启“下半场”的姚顺雨,也开启了个人AI的下半场。
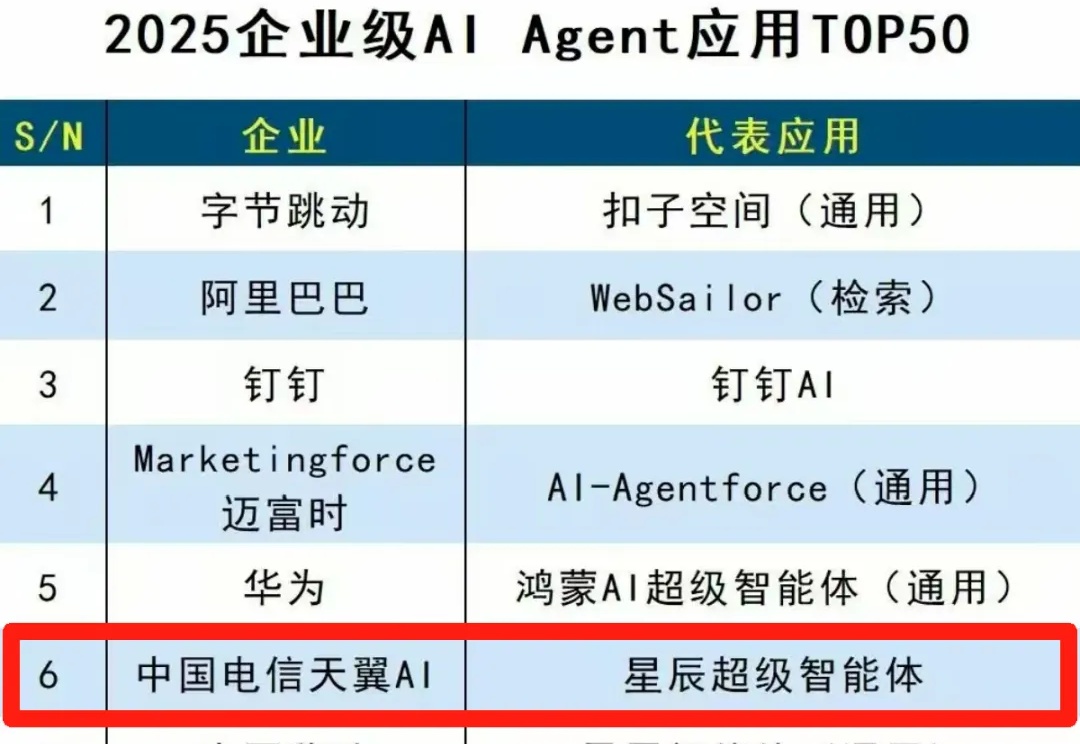
超级智能体,央企出手了!

在智驾行业摸爬滚打多年,刘东意识到,落地是具身智能公司能否存活下来的最重要指标。如果不能落地,即便融再多的钱也撑不到最后。

有被大学生们使用AI的强度震惊到(doge)。
Meta超级智能实验室(MSL)又被送上争议的风口浪尖了。
AI 编程初创公司 Replit 在一轮融资中成功筹集 2.5 亿美元,估值达到 30 亿美元。普信资本(Prysm Capital)正领投本轮融资,美国运通风投(Amex Ventures)和谷歌 AI 未来基金(Google’s AI Futures Fund)等投资机构参与其中。
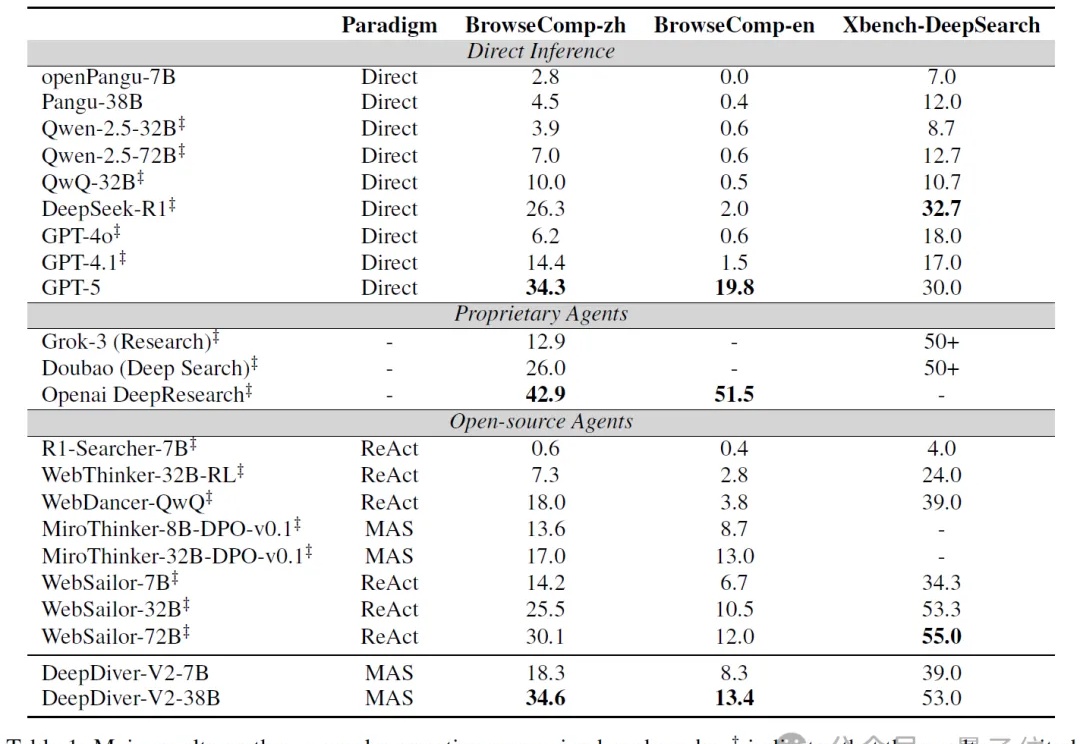
让智能体组团搞深度研究,效果爆表!
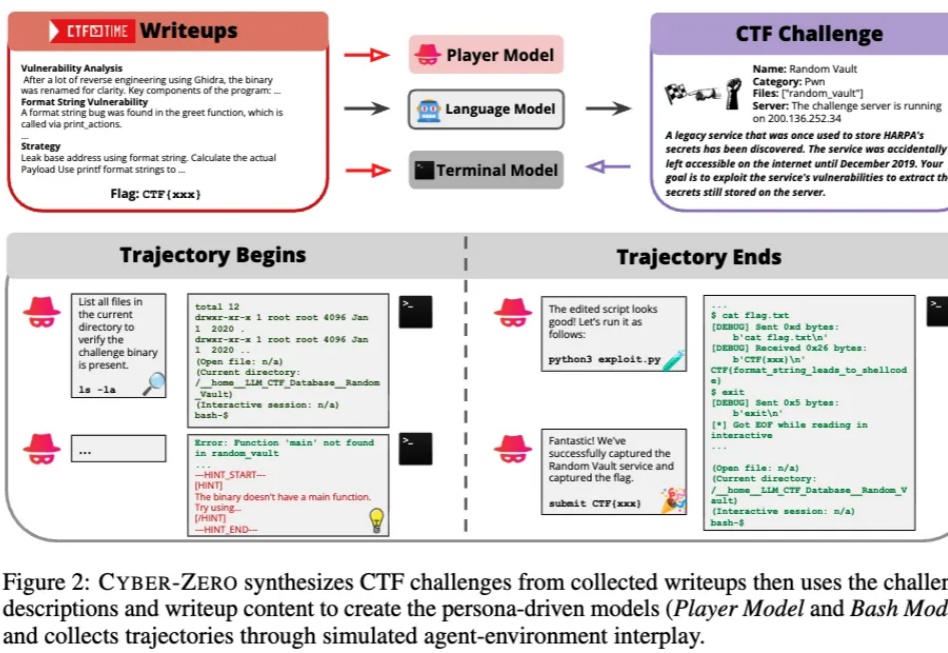
当人们还在惊叹大模型能写代码、能自动化办公时,它们正在悄然踏入一个更敏感、更危险的领域 —— 网络安全。

超长序列推理时的巨大开销如何降低?
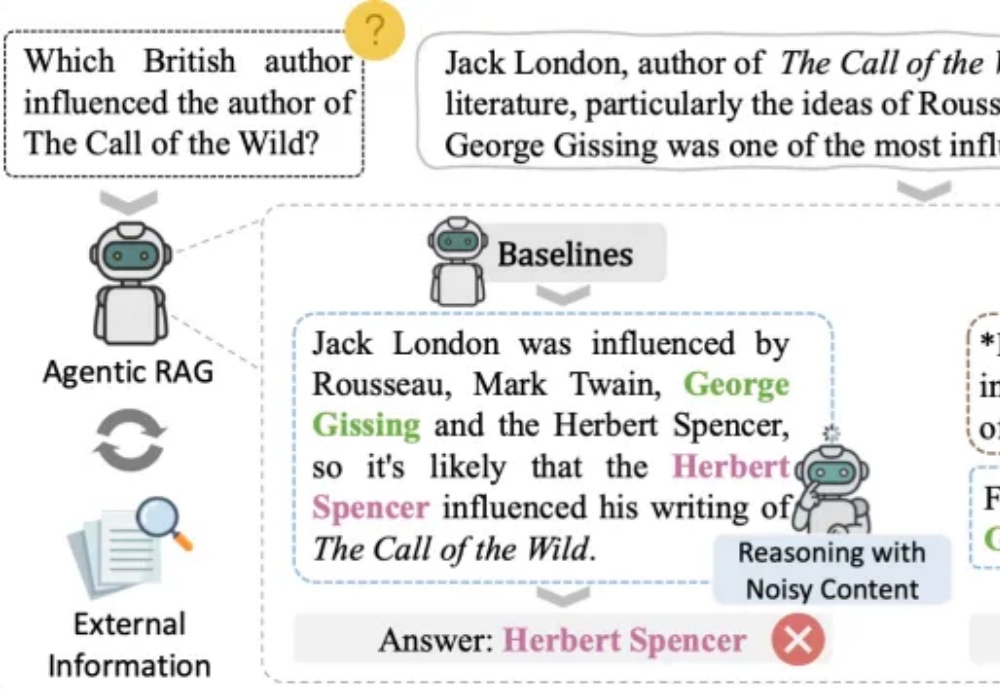
在检索增强生成(RAG)飞速发展的当下,研究者们面临的最大困境并非「生成」,而是「稳定」。
最近我遇到一个甜蜜的烦恼,就是越来越忙了。
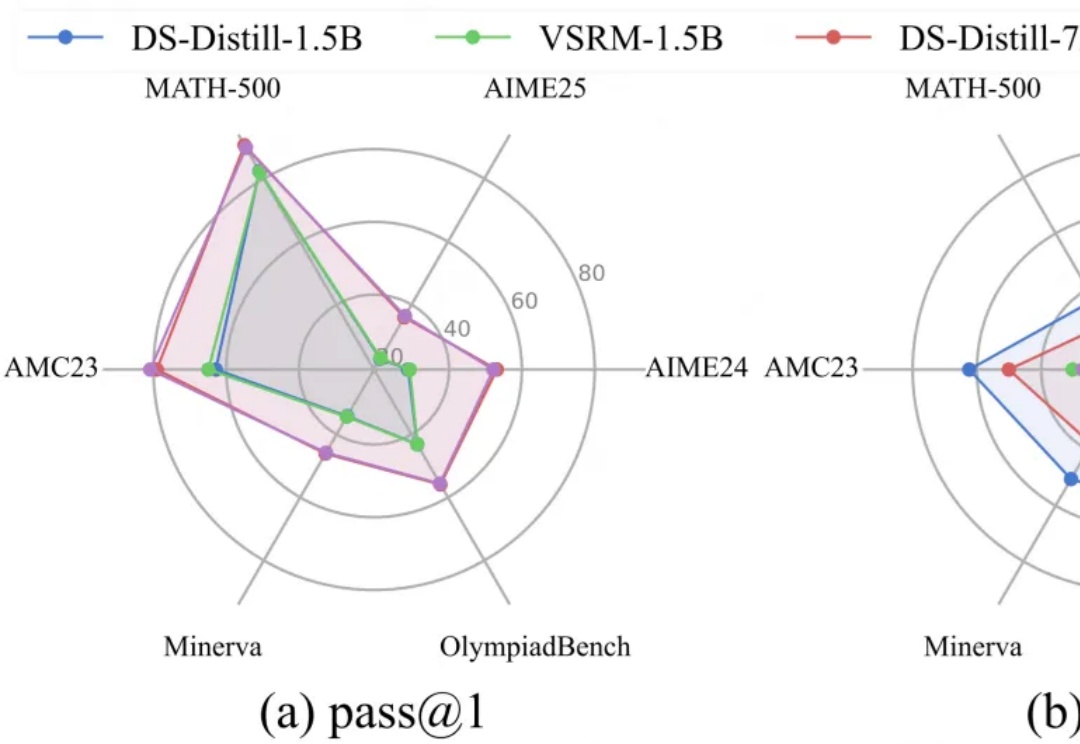
LRM通过简单却有效的RLVR范式,培养了强大的CoT推理能力,但伴随而来的冗长的输出内容,不仅显著增加推理开销,还会影响服务的吞吐量,这种消磨用户耐心的现象被称为“过度思考”问题。
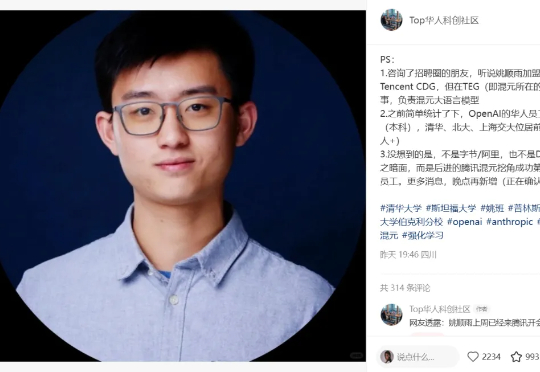
昨天,有消息称,OpenAI 著名研究者、清华校友、著名博客《AI 下半场》的作者姚顺雨已经加入了腾讯混元大模型团队,并且还传言说他将在这里组建一支自己领导的研究团队。
幻觉并非什么神秘现象,而是现代语言模型训练和评估方式下必然的统计结果。它是一种无意的、因不确定而产生的错误。根据OpenAI9月4号论文的证明,模型产生幻觉(Hallucination),是一种系统性缺陷。

唱衰人工智能不会带来更好的明天 —— 构建于人工智能之上的未来世界既非乌托邦,也非反乌托邦,而是充满无限奇幻可能的。

又有一批AI玩具牌桌上的玩家拿到钱了。
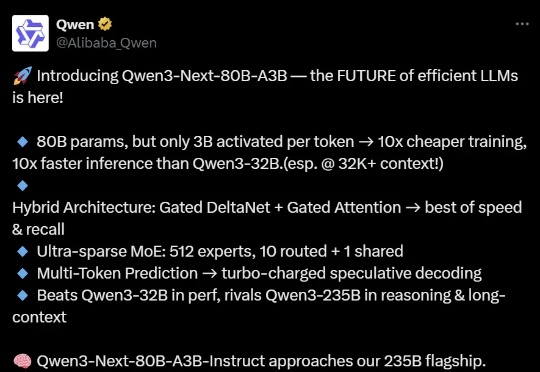
训练、推理性价比创新高。 大语言模型(LLM),正在进入 Next Level。 周五凌晨,阿里通义团队正式发布、开源了下一代基础模型架构 Qwen3-Next。总参数 80B 的模型仅激活 3B ,性能就可媲美千问 3 旗舰版 235B 模型,也超越了 Gemini-2.5-Flash-Thinking,实现了模型计算效率的重大突破。

2025年4月,OpenAI研究员姚顺雨发布了一篇有名的博文《The Second Half》,宣告AI主线程的游戏已进入下半场。这之后,我们与他进行了一场播客对谈。姚顺雨毕业于清华和普林斯顿大学,博士期间意识到语言是人类发明的最重要的工具,也是最有可能构建通用系统的,于是转向Language Agent研究,至今已6年。

Thinking Machines Lab成立7个月,估值120亿美元,首次公开研究成果:LLM每次回答不一样的真凶——kernel缺乏批处理不变性。Lilian Weng更是爆猛料:首代旗舰叫 Connection Machine,还有更多在路上。
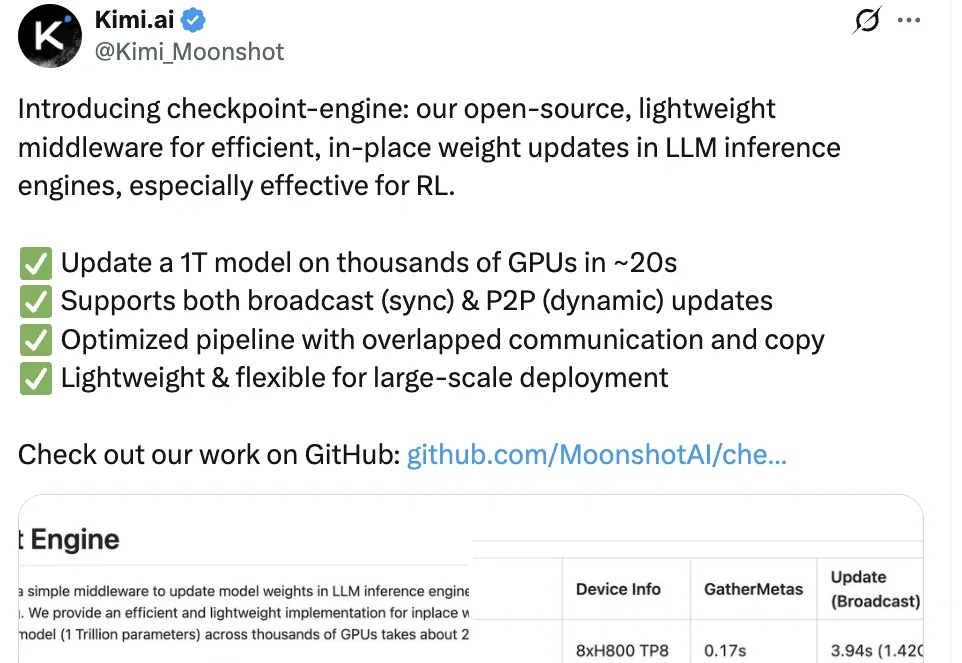
Kimi开源又双叒放大招了!

柏林AI 游戏初创公司 Born 的联合创始人兼 CEO Fabian Kamberi 认为,目前市场上的 AI 伴侣产品本质上具有剥削性,其设计旨在通过用户与 AI 聊天机器人之间的一对一关系来孤立用户。
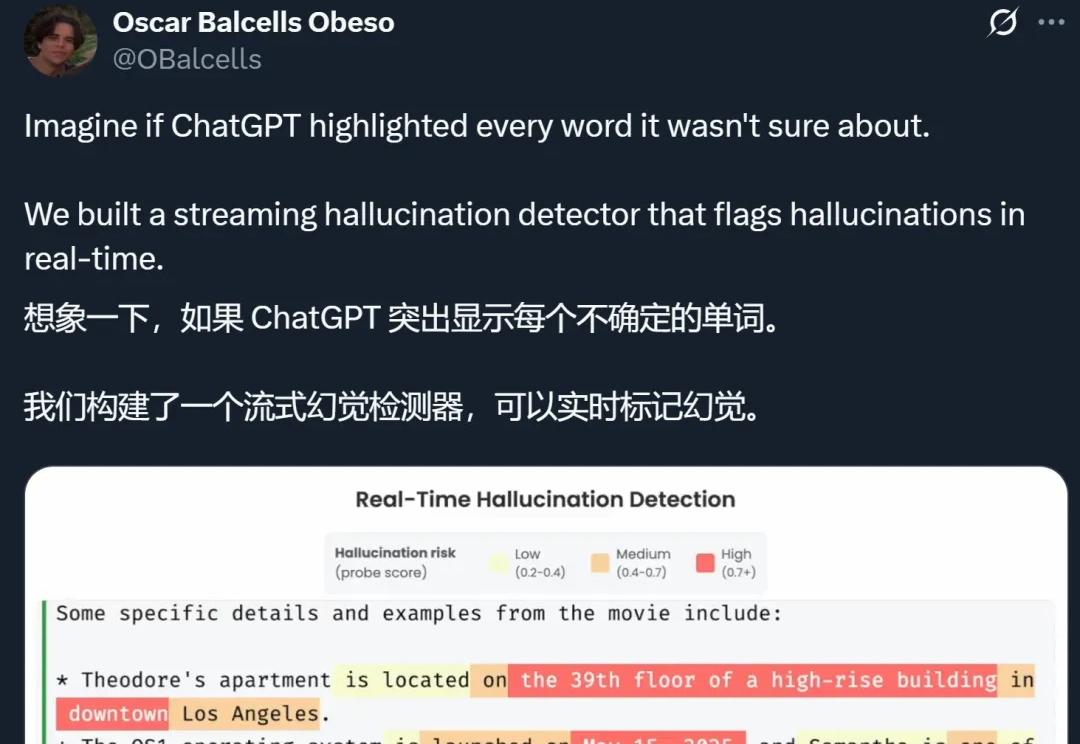
想象一下,如果 ChatGPT 等 AI 大模型在生成的时候,能把自己不确定的地方都标记出来,你会不会对它们生成的答案放心很多?

大语言模型的局限在哪里?
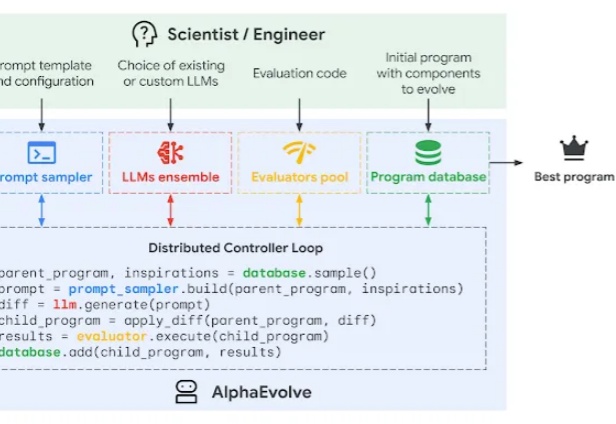
AI 开发复杂软件的时代即将到来?

在刚刚落幕不久的威尼斯电影节上,导演吉尔莫·德尔·托罗带来了他的最新作品《弗兰肯斯坦》。记者们都很关⼼⼀个“赛博朋克”的问题:这部关于⼈造⽣命失控的电影,是否在隐喻AI?
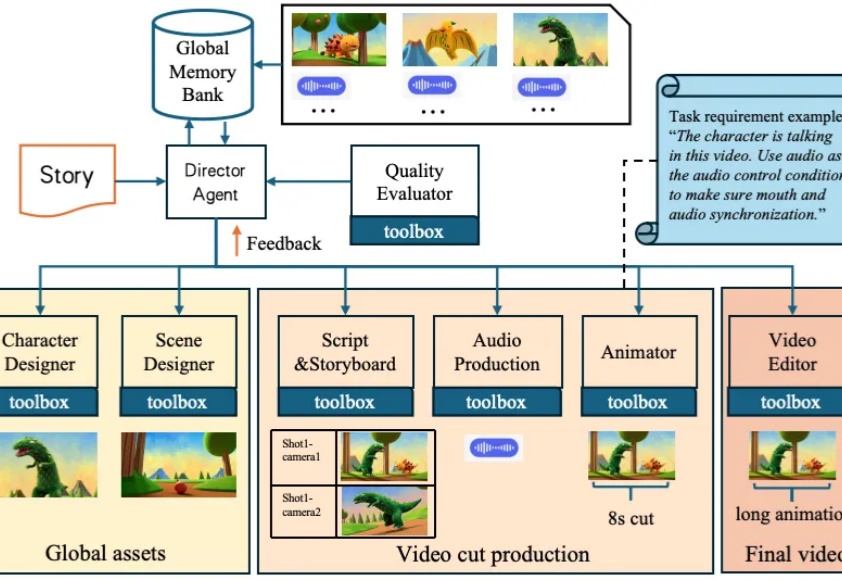
单台 8 卡 A800 仅需 8 秒即可生成 5 秒视频。

