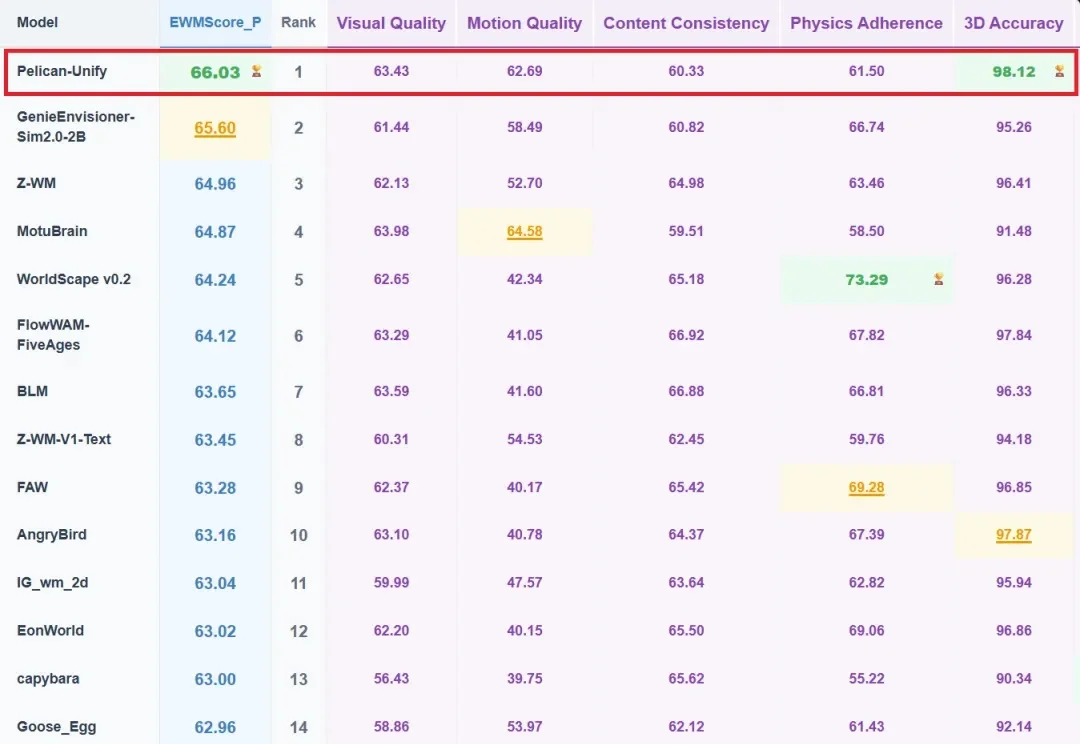
「具身大一统」不是口号:北京人形再度登顶WorldArena,拿下双冠王
「具身大一统」不是口号:北京人形再度登顶WorldArena,拿下双冠王最近,全球的网民都化身「监工」,围观了 Figure AI 的人形机器人直播在物流传送带上连续几十个小时,不间断地分拣包裹。
来自主题: AI技术研报
9409 点击 2026-05-18 10:24
 搜索
搜索
最近,全球的网民都化身「监工」,围观了 Figure AI 的人形机器人直播在物流传送带上连续几十个小时,不间断地分拣包裹。
早在2024年,人们还倾向于给Agent提供海量的工具(例如通过MCP协议连接的API、搜索引擎、代码解释器等)。但是,“拥有工具”并不等于“知道如何使用工具”。当任务变得复杂且长周期时,要求Agent每次都从头开始推理“该用哪个工具、何时用、怎么组合、出错怎么办”,会导致系统极度脆弱、延迟极高且不可靠。
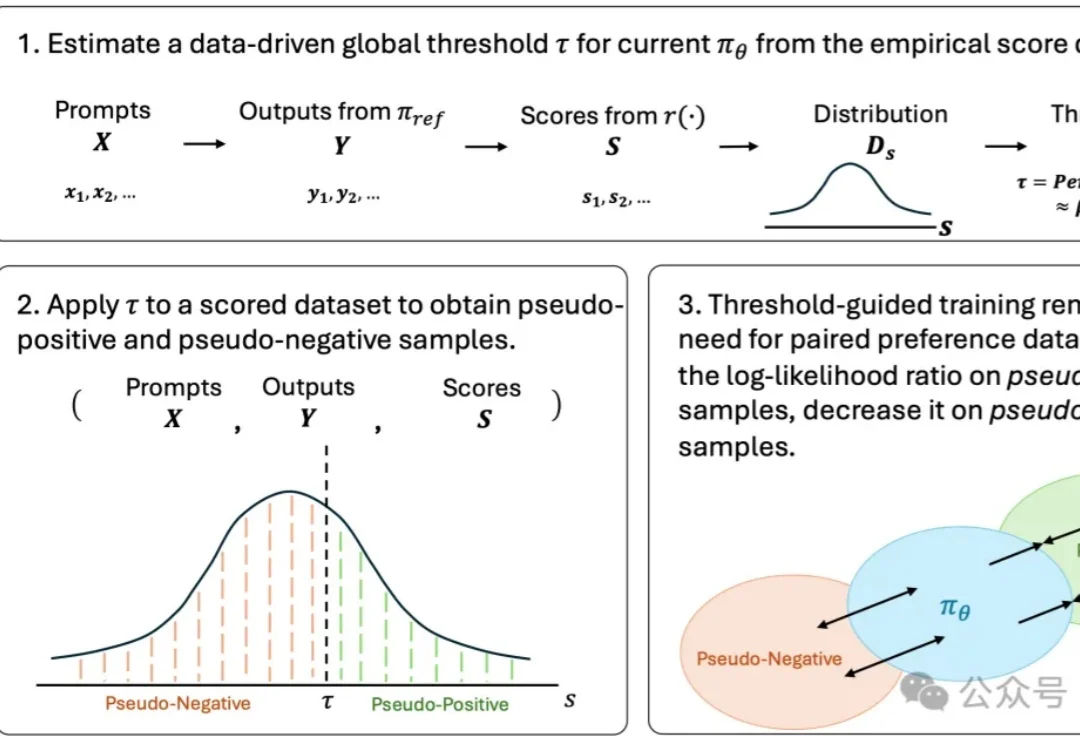
生成模型的偏好对齐,可能正在进入一个新的阶段。

AI Coding的玩法,又变了。
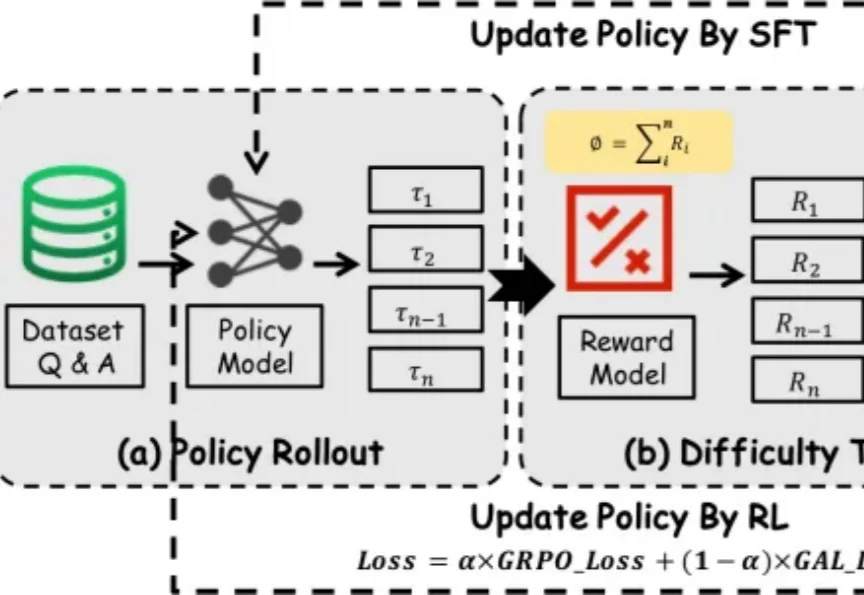
过去一段时间里,在围绕大模型推理能力增强的研究中,SFT 和 RL 是两类核心后训练范式 —— 前者稳定收敛快,能高效吸收高质量推理数据;后者更具探索性,有望推动模型实现复杂推理和分布外泛化。
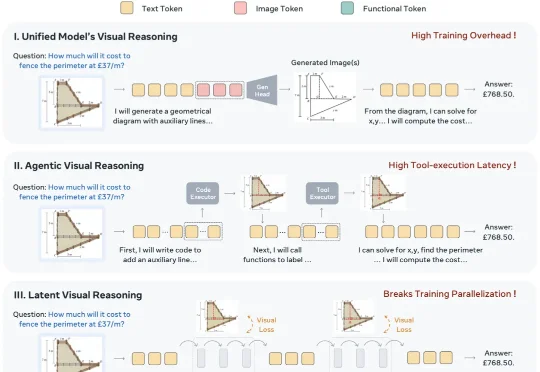
近日,Meta AI 与香港中文大学颠覆性提出了一种全新的视觉推理范式 ATLAS,不用外部工具,不显式生成中间图像,没有视觉监督信号,只用一个离散 word,首次颠覆性地代替 Agentic 和 Latent Visual Reasoning。
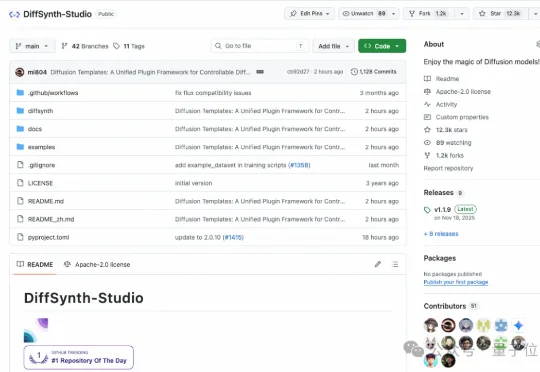
近期,专为Diffusion模型设计的插件框架——Diffusion Templates正式开源发布。这个框架能大幅降低可控生成技术的训练和使用难度,让开发者能够通过丰富的Templates来精准控制模型的生成结果。
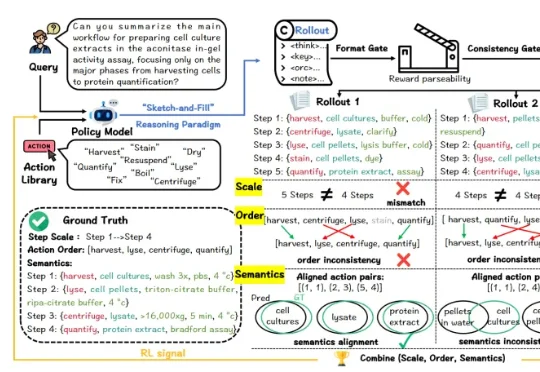
针对这一问题,上海人工智能实验室、复旦大学、上海交通大学团队提出了Thoth:一个面向生物实验protocol生成的科学推理模型。一句话概括:Thoth不是让模型“写得像protocol”,而是让模型按照实验逻辑,生成可解析、可评估、可执行的protocol。

浙大联合微软亚洲研究院最新提出的World-R1,不改架构、不要3D数据,纯靠强化学习就让视频生成模型学会了“理解”三维世界。World-R1 的出发点很简单:预训练的视频模型里面已经有 3D 知识了,只是“沉睡”着。用强化学习把它叫醒就行。

最近一两年,AI 行业有一个很微妙的变化:大家不再满足于问 “模型会不会回答”,也不再只关心 “Agent 能不能调用工具”。越来越多的讨论开始回到一个更终极的问题:AI 到底能不能完全自动化接管工作区,理解个性化需求,像一个真实的人类劳动力一样,把一件事情从头到尾做完?

为了解决这一问题,来自中山大学和美团的研究团队提出了 X2SAM,一个统一的图像与视频分割多模态大模型框架。它希望让模型不仅能「看懂」图像和视频,还能进一步「指出」目标在每个像素上的准确位置。

阿里巴巴 Z-Image 团队联合香港科技大学、加州大学圣地亚哥分校、香港中文大学等机构提出 D-OPSD(On-Policy Self-Distillation),首个针对少步扩散模型的在线策略自蒸馏框架。D-OPSD 无需奖励模型、无需成对偏好数据,
TencentDB Agent Memory 全球正式开源

Claude的内心独白被翻译成人话了!就在今天,Anthropic开源了一台AI读心机器,然而它跑出来的第一批成果却让人触目惊心。
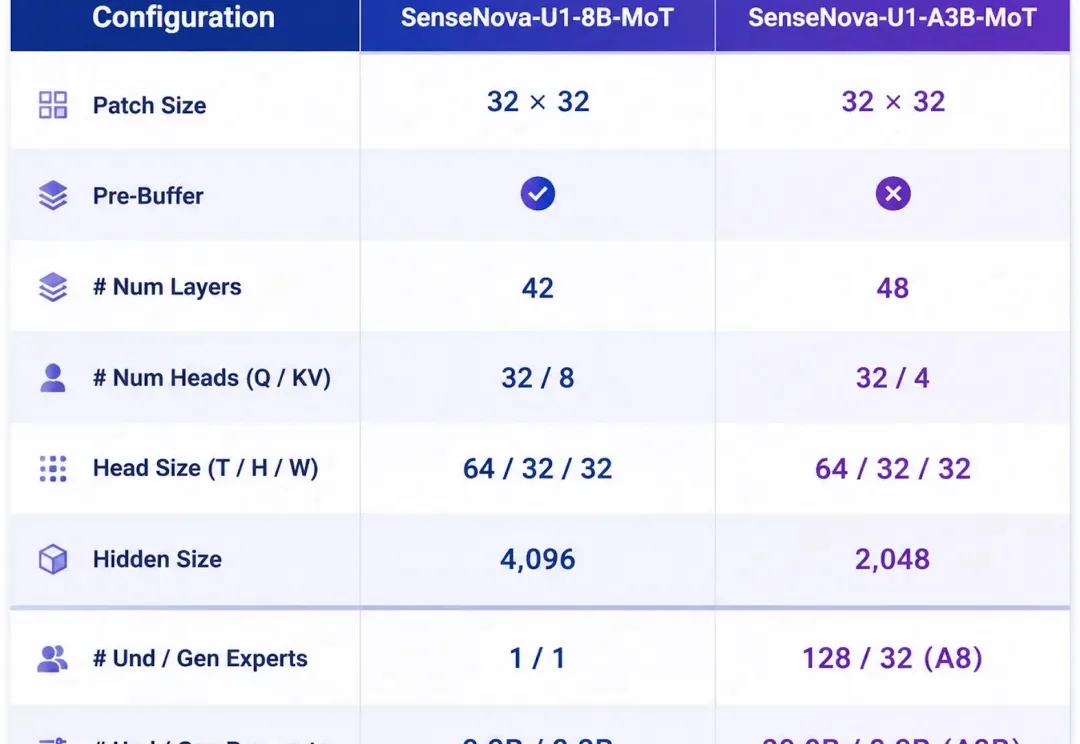
当 AI 行业的目光集中在 Agent、工具调用、长程任务这些上层应用之时,底层的多模态架构正在经历一次更安静、也更彻底的范式转变 —— 它要回答的是一个看似朴素的问题:理解与生成,是否天生就该是两件事?

就在今天,Agentic AI工程师发现:博士80小时的科研任务,Codex不到2小时就跑完了,效率差达到了40倍!其实按照旧标准,AGI早已存在了,只是全行业都在移动球门。

“你花在 AI 编程上的费用,90% 都浪费在了没必要上传的上下文里!”

具身智能正以前所未有的速度发展,VLA 模型展现出越来越强的动作和泛化能力。然而,当我们真正把 VLA 模型部署到物理世界时,一个核心挑战浮出水面:实时性。
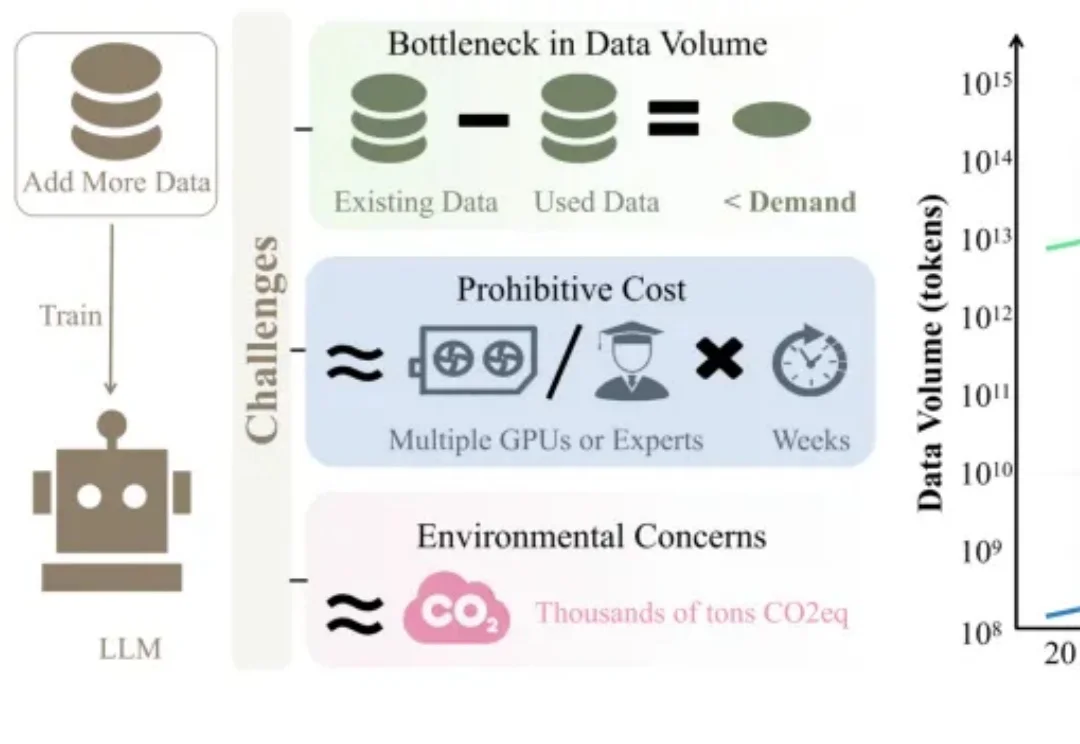
当训练数据枯竭、训练成本飙升,大语言模型(LLM)训练之路该何去何从?
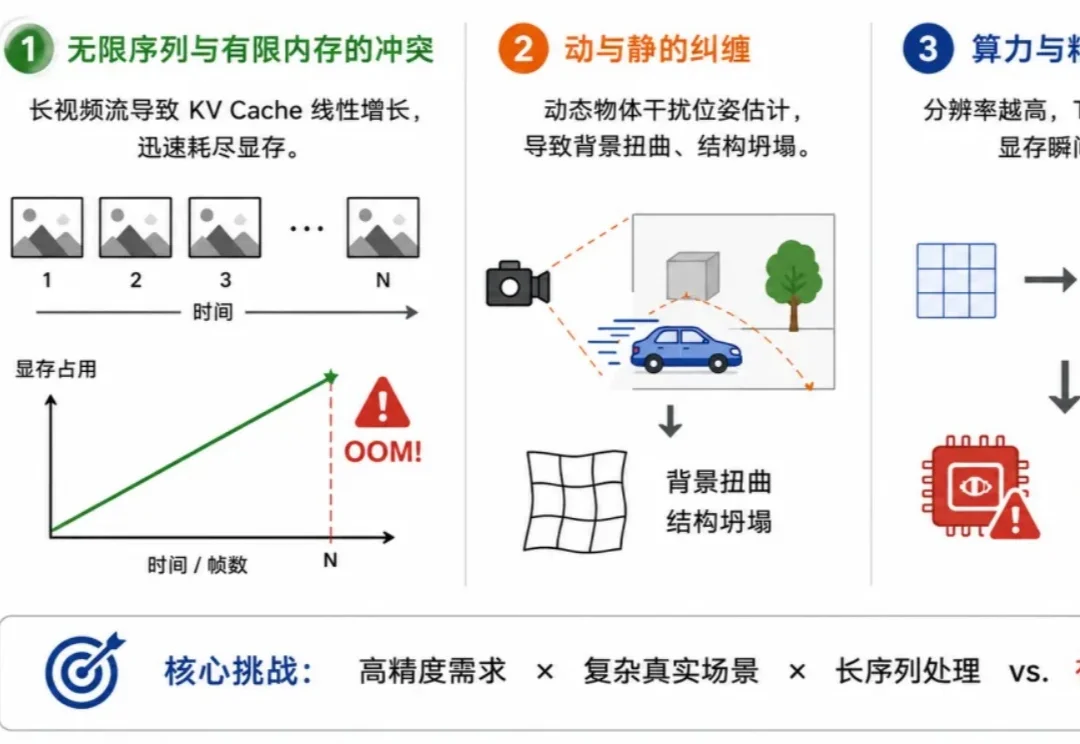
在迈向通用人工智能(AGI)的过程中,世界模型被视为让机器理解物理规律、实现空间智能的关键。而高效、鲁棒和精准的三维感知能力,被广泛认为是世界模型的首要前提。通常来说,一个成熟的世界模型需要具备三大核心能力:对长时空序列的持续记忆、对复杂动力学的因果解耦、以及对高清物理细节的精细感知。

Claude深陷「角色混淆」Bug,分不清自己的话与用户指令,长上下文成了降智「重灾区」。
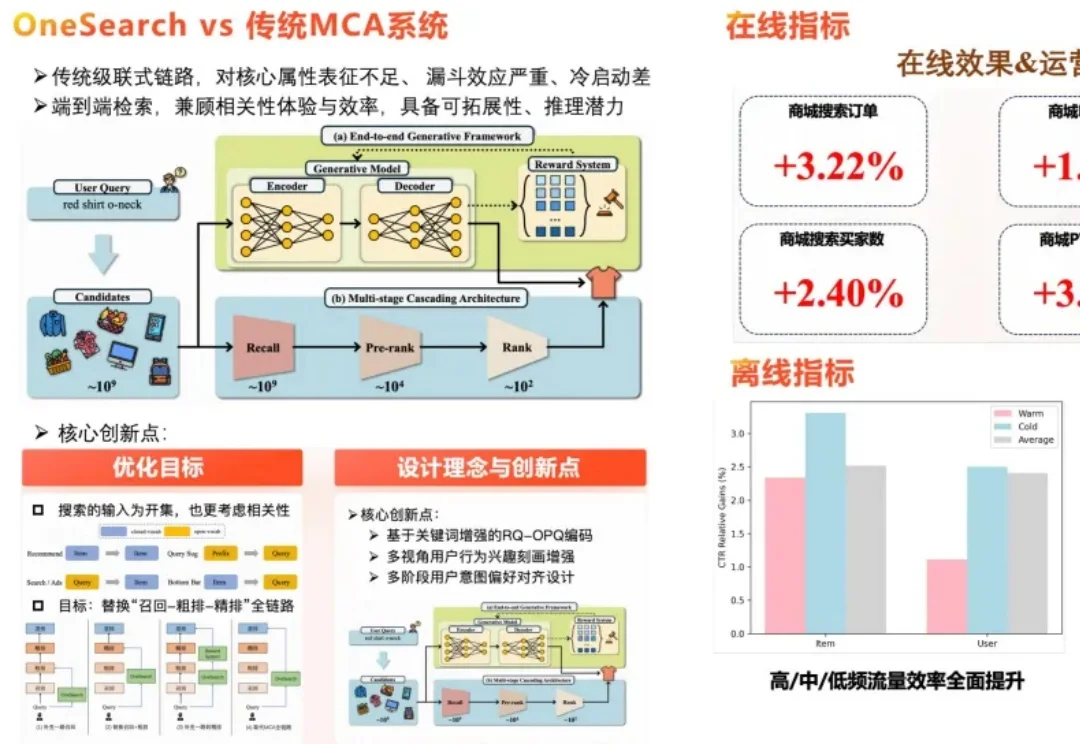
针对生成式检索范式在电商搜索场景下面临的复杂查询理解不足、用户潜在意图挖掘乏力、奖励系统易过拟合历史窄偏好等落地瓶颈,快手技术团队在已规模化部署的工业级生成式搜索框架 OneSearch 基础上,发布了一篇系统性升级的研究论文,正式推出新一代框架 OneSearch-V2。
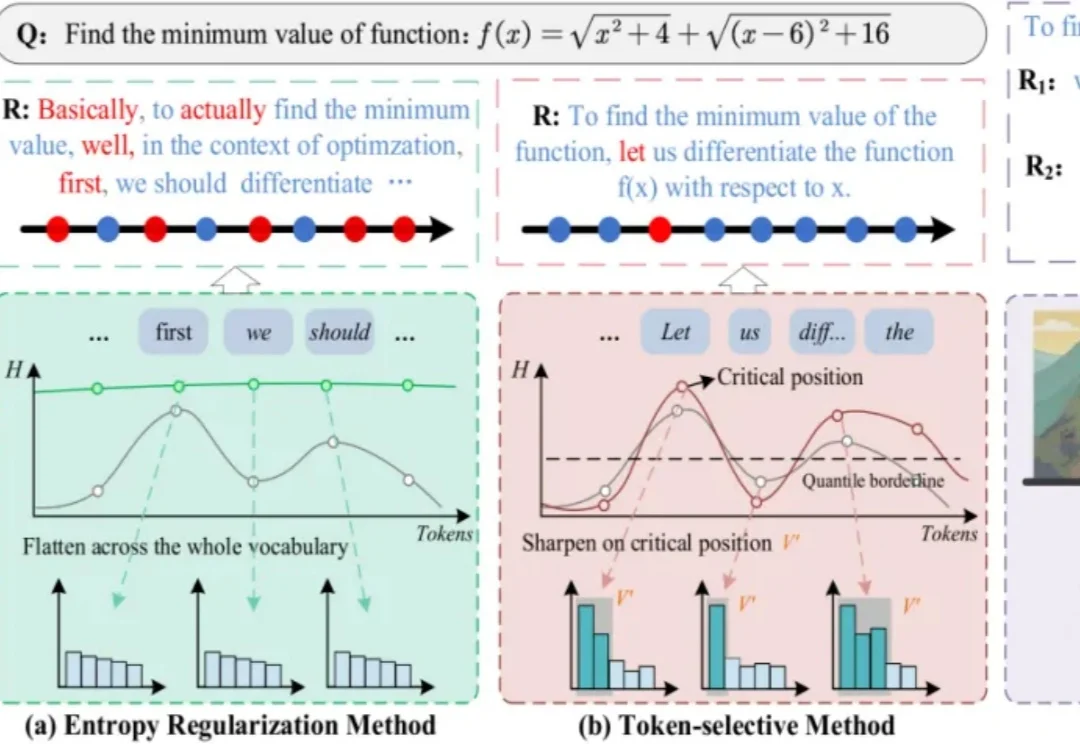
I²B-LPO 是一个面向 RLVR 后训练的探索增强框架,通过改进 rollout 策略引导模型生成更多样化的推理轨迹,将探索行为从 “重复采样” 推进到 “在关键节点生成更具区分度的推理轨迹”,在多个数学基准上同时提升准确率与语义多样性,最高分别达 5.3% 和 7.4%。该工作接收于 ACL 2026 Main,来自阿里达摩院 - 智能决策团队。

一篇让你看懂的AGenUI开源解读

这两天打开X,发现一个开源项目刷屏了——Hyperframes。GitHub上两天干了17.4k star,1.6k fork,Codex、Cursor、Claude Code的插件全线覆盖。
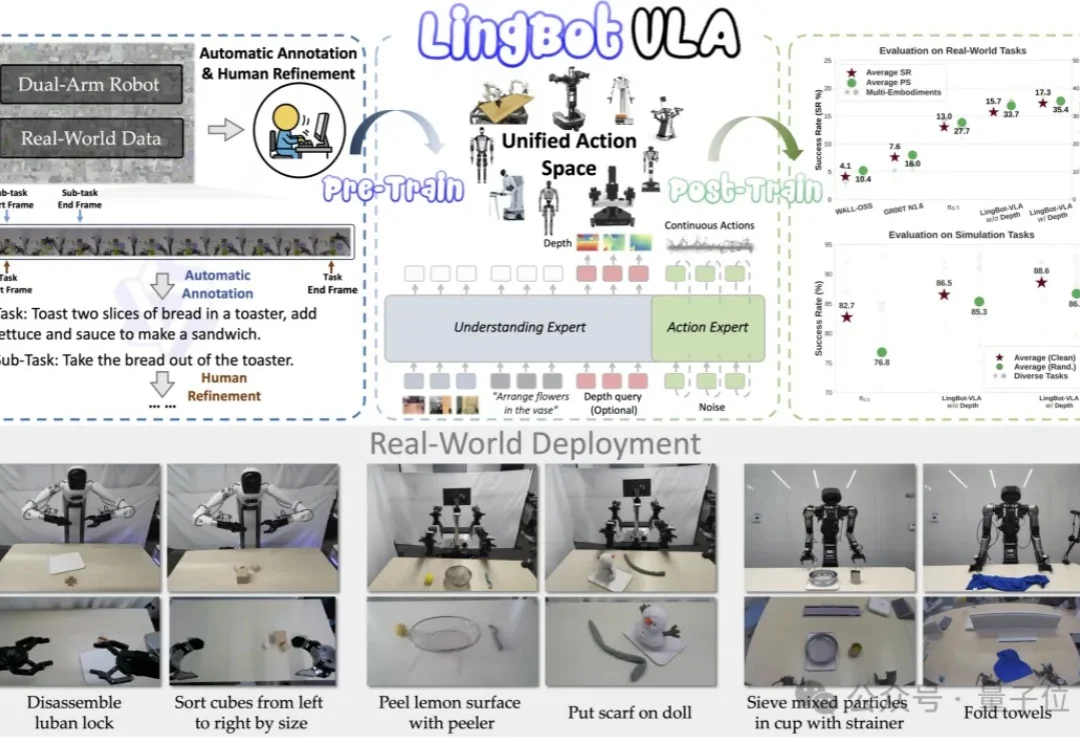
就在刚刚,蚂蚁集团旗下具身智能公司灵波科技传出新动作—— 全面开源其具身基座模型LingBot-VLA的真机后训练工具链。
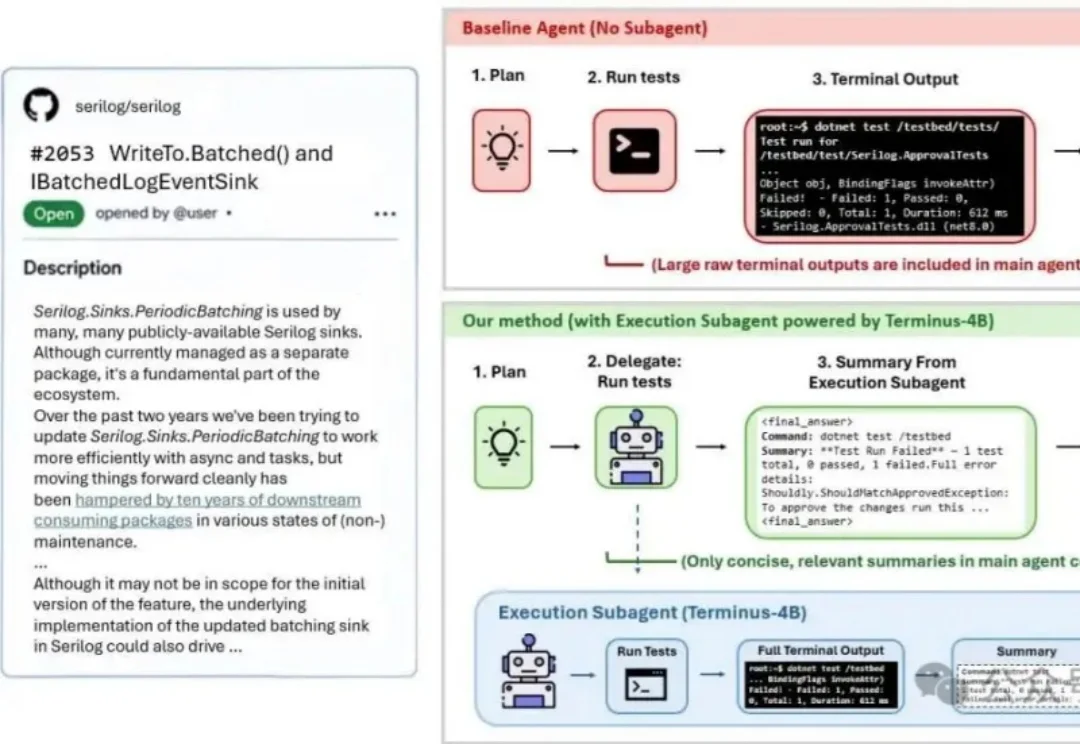
您有没有想过:在代码Agent里,执行终端命令、跑测试、读报错、总结日志这种任务,用Claude Opus、Claude Sonnet、GPT-5.3-Codex这类昂贵Token的大模型来执行,是不是有点浪费?一定要这么做吗?

当下的大模型后训练(Post-training)pipeline 中,On-Policy Distillation(OPD)已经成为了明星技术。从 Qwen3、MiMo 到 GLM-5,业界纷纷采用 OPD 并报告了巨大的性能提升。相比于强化学习(RL)稀疏的结果奖励,OPD 提供了密集的 Token 级别监督信号,看起来就像是一顿「免费的午餐」。

ber!这个五一假期,我也是真够忙的: 自拍、电影、追剧、街头采访、听音乐会,还抽空回老家结了次婚……

在多模态大模型(MLLM)快速发展的浪潮中,融合多模型 “集体智慧” 已成为提升模型性能的关键路径,并催生了多教师知识蒸馏这一主流范式。然而,不同来源的教师模型在架构与优化上的差异,其在相似推理过程中呈现出不稳定甚至偏移的认知轨迹,即 “概念漂移”(Concept Drift)。