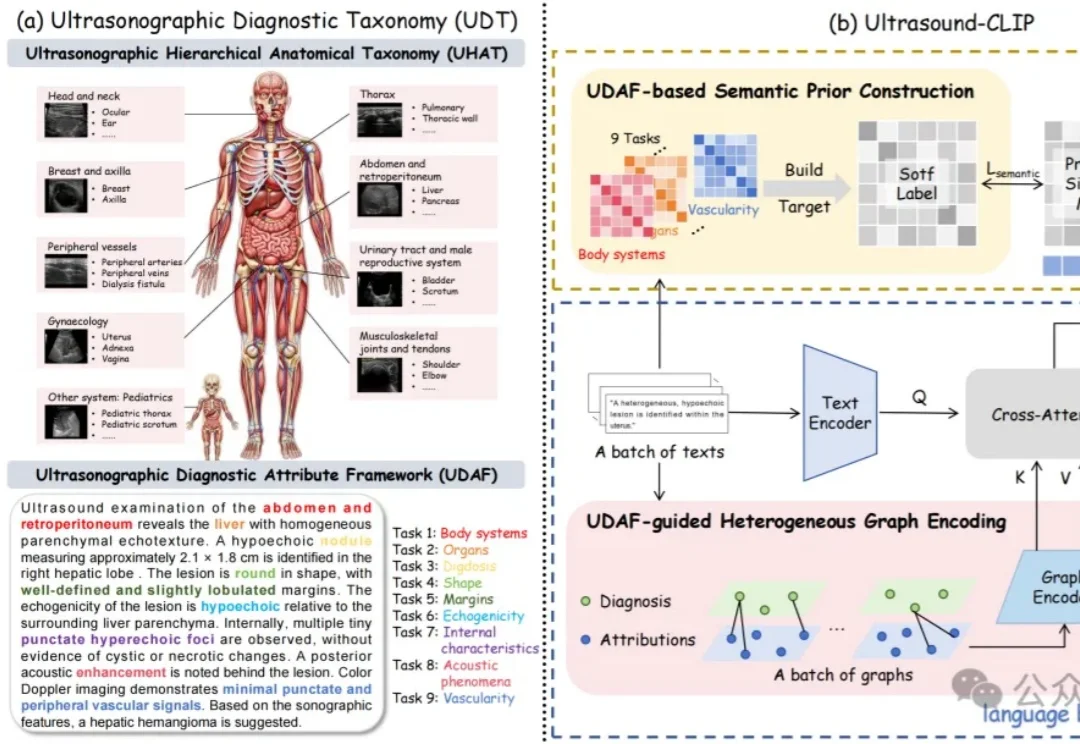
挤干大模型高分「水分」!最强模型仅49分,南大傅朝友发布Video-MME-v2
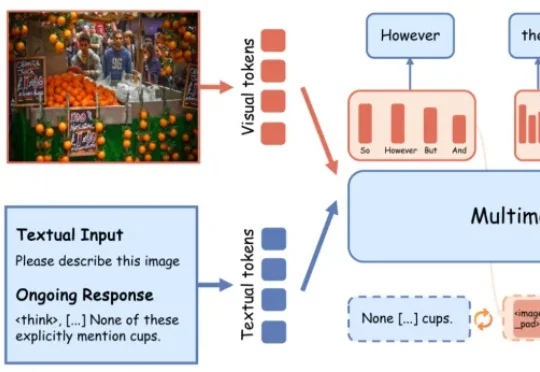
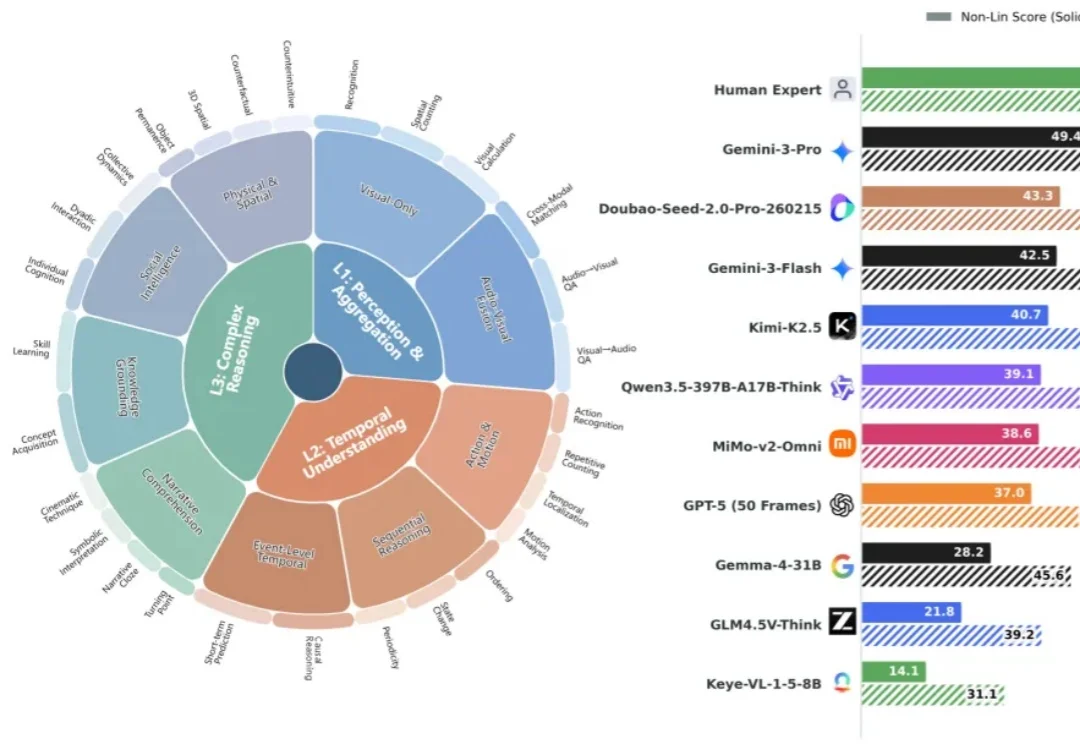
挤干大模型高分「水分」!最强模型仅49分,南大傅朝友发布Video-MME-v2现有大模型评测分数日趋饱和,但与真实体验差距显著。南京大学傅朝友团队牵头,在 Google Gemini 评测团队邀约下推出视频理解新基准 Video-MME-v2。凭借创新的分层能力体系与组级非线性评分,以及 3300 + 人工时高质量标注,揭示模型与人类的巨大鸿沟(49 vs 90)、传统 Acc 指标虚高、以及 “Thinking” 并非总是增益等现象。
来自主题: AI技术研报
10997 点击 2026-04-13 15:01