
数据邪修大法好:仅用文本数据就能预训练多模态大模型
数据邪修大法好:仅用文本数据就能预训练多模态大模型没有图片,也能预训练多模态大模型?在多模态大模型(MLLM)的研发中,行业内长期遵循着一个昂贵的共识:没有图文对(Image-Text Pairs),就没有多模态能力。
来自主题: AI技术研报
9051 点击 2026-03-03 14:25
 搜索
搜索
没有图片,也能预训练多模态大模型?在多模态大模型(MLLM)的研发中,行业内长期遵循着一个昂贵的共识:没有图文对(Image-Text Pairs),就没有多模态能力。
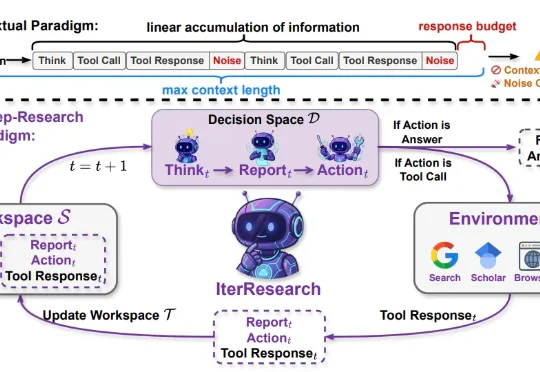
来自中国人民大学与阿里巴巴通义实验室的研究团队提出了 IterResearch,一种全新的迭代式深度研究范式。通过马尔可夫式的工作空间重构,IterResearch 让 Agent 在仅 40K 上下文长度下完成了 2048 次工具交互且性能不衰减,在 BrowseComp 上从 3.5% 一路攀升至 42.5%。
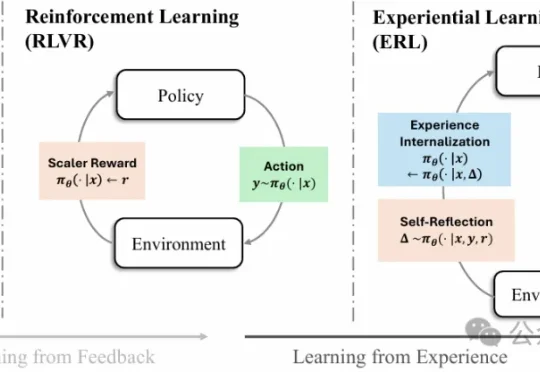
强化学习已经成为大模型后训练阶段的核心方法之一,但一个长期存在的难题始终没有真正解决:现实环境中的反馈往往稀疏且延迟,模型很难从简单的奖励信号中推断出应该如何调整行为。
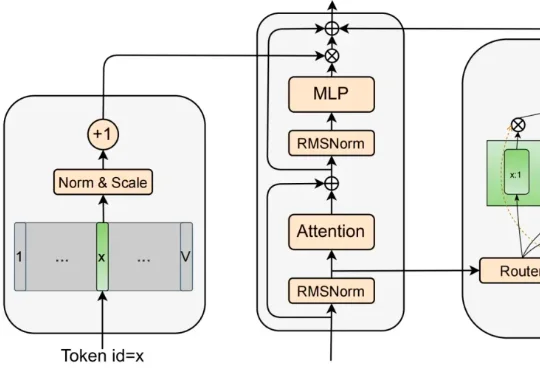
为了松绑参数与计算量,MoE 曾被寄予厚望 。它靠着稀疏激活的专家子网络,在一定程度上实现了模型容量与计算量的解耦 。然而,近期的研究表明,这并非没有代价的免费午餐 :稀疏模型通常具有更低的样本效率 ;随着稀疏度增大,路由负载均衡变得更加困难 ,且巨大的显存开销和通信压力导致其推理吞吐量往往远低于同等激活参数量的 dense 模型 。

MMLab@NTU联合中山大学的最新研究,给出了一份从入门到精通的终极“菜谱”——VLANeXt。这项研究没有简单提出一个新模型了事,而是系统性地从12个关键维度,深度剖析了VLA的设计空间。从基础组件到感知要素,再到动作建模的额外视角,每一步都有扎实的实验支撑。
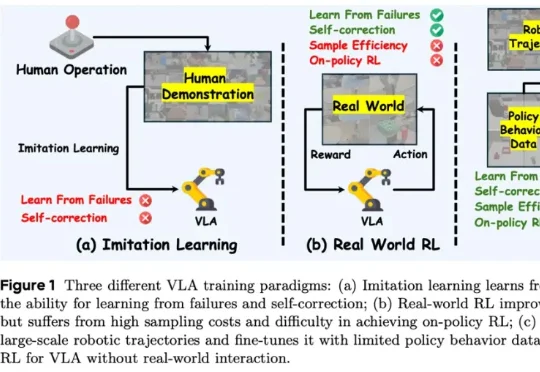
香港科技大学 PEI-Lab 与字节跳动 Seed 团队近期提出的 WMPO(World Model-based Policy Optimization),正是这样一种让具身智能在 “想象中训练” 的新范式。该方法无需在真实机器人上进行大规模强化学习交互,却能显著提升策略性能,甚至涌现出 自我纠错(Self-correction) 行为。

AI 行业,似乎已经提前进入了以个人 Agent 为代表的「后 ChatGPT 时代」。这印证了独立 AI 基准测试机构「Artificial Analysis」的预测结论:2026,Agent 正在全面爆发。近期,他们发布了对 AI 领域发展的全面总结:《2025 年终 AI 发展报告》。
近日, Anthropic 和斯坦福研究者 Neil Rathi 与这位传奇研究者联合发布了一篇新论文,并得到了一些相当惊人的新发现。在这项研究中,他们挑战了当前大模型安全领域的一个核心假设。长期以来,业界普遍认为要在模型发布后通过 RLHF 或微调来限制其危险行为。但 Neil Rathi 和 Alec Radford 提出了一种更本质的解法:
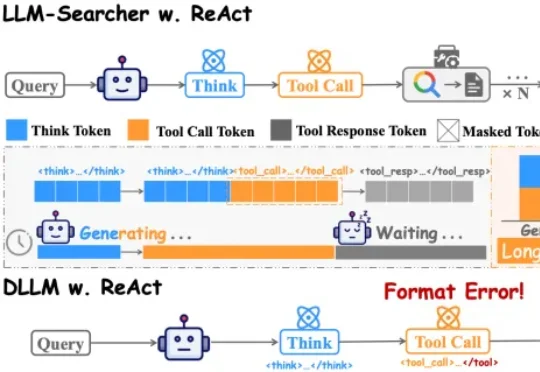
中国人民大学团队在论文DLLM-Searcher中,第一次让扩散大语言模型(dLLM)学会了这种“一心二用”的本事。目前主流的搜索Agent,不管是Search-R1还是R1Searcher,用的都是ReAct框架。这个框架的执行流程是严格串行的:

我们开源的 Open Cowork,正是一次面向 “桌面端虚拟同事” 的实践:一键安装、无需写代码,让模型在安全沙箱里操作你的工作空间,既能产出 PPT/Word/Excel/PDF 等专业成果,也能通过 GUI 直接操作电脑完成更复杂更通用的跨应用流程。

现有Rectified Flow(RF)模型在反演阶段面临的核心挑战,是逆向ODE对微小误差高度敏感,容易沿着数值不稳定方向偏离前向流形,导致轨迹发散、重建不一致、编辑不可控。为解决这一问题,团队提出PMI(Prox-Mean-Inversion),一种针对RF反演稳定性的轻量化修正机制。

本篇文章被 ICRA 2026 接收并获得 IROS 2025 双料 Workshop 最佳论文,第一作者张子哲(site: zizhe.io)是宾夕法尼亚大学机器人学硕士生,同时在 GRASP 实验室担任科研助理,导师为 Nadia Figueroa 教授,研究兴趣涵盖机器学习,安全控制以及人机交互。

Meta联合多所高校发布首个可规模化自动生成第一视角音视频理解数据的引擎EgoAVU ,让多模态大模型首次真正「听懂世界」。

香港科技大学 & 北航 & 商汤等提出了一个专门面向视频生成扩散模型的 QAT 范式 ——QVGen,在 3-bit / 4-bit 都能把质量拉回来,并且让 4-bit 首次接近全精度表现成为现实。该论文现已被 ICLR 高分接收:rebuttal 前 88666(top 1.4%),rebuttal 后 88886 (top 0.5%)。
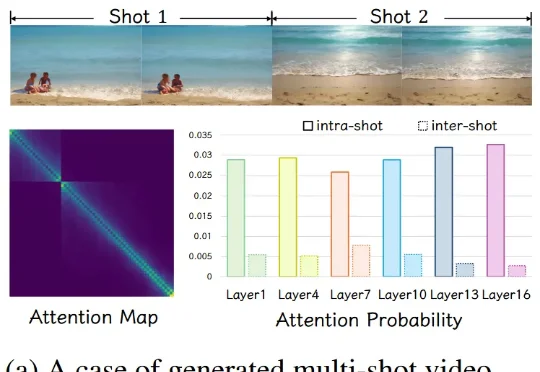
基于对注意力特性的观察,CineTrans 提出块对角掩码的通用机制,使视频生成模型能高效地自动化转场。为了进一步提升转场模型的效果和准确性,作者设计了详细的多镜头视频生产管线,并收集了一个高质量、多镜头数据集 Cine250K,大幅提升多镜头转场视频生成的效果。作为首个时间级可控的自动化转场模型,CineTrans 为这一领域的众多后续方法提供了关键技术。

GeoPT提出了一种全新的动力学提升预训练范式,通过合成动力学(Synthetic Dynamics)将静态几何“提升”到动态空间,让模型在无标签数据上通过学习粒子轨迹演化来获取物理直觉。
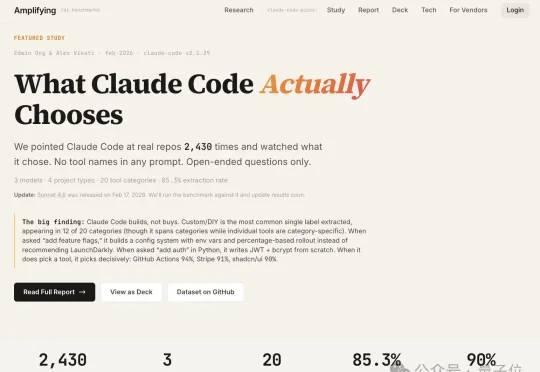
最近,专注于量化AI主观决策的基准测试工作室Amplifying.ai,针对Claude Code的工具选择倾向开展了一项系统性研究。研究覆盖3款模型、4种项目类型及20个工具类别,累计分析了2430次工具选择行为。
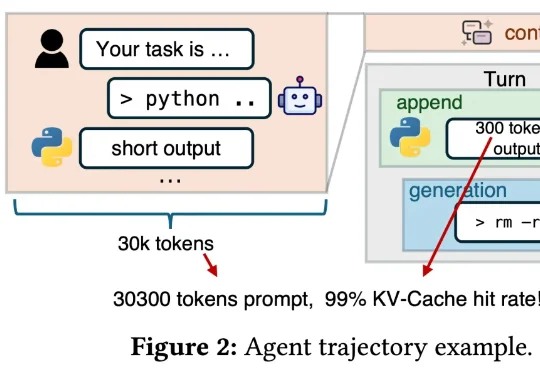
「DeepSeek V4 来了!」这样的消息是不是已经听烦了?总结来说,这篇新论文介绍了一个名为「DualPath」的创新推理系统,专门针对智能体工作负载下的大语言模型(LLM)推理性能进行优化。具体来讲,通过引入「双路径 KV-Cache 加载」机制,解决了在预填充 - 解码(PD)分离架构下,KV-Cache 读取负载不平衡的问题。
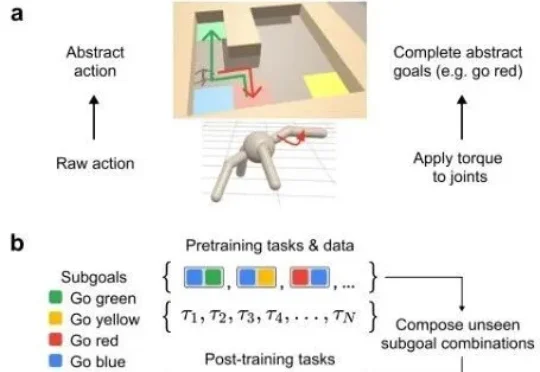
传统AI模型在稀疏奖励环境中,往往会找不到激励难以学会层次化思考。如今,谷歌团队通过引入元控制器操控模型内部残差流,让智能体学会了「跳跃式思考」。该研究揭示了大模型内部可自发形成了类似人脑的层次化决策机制,为AI在需要多步的复杂任务提供了全新的训练范式。

各位对Agent Skill早已轻车熟路。不可否认,在Claude code、Openclaw的加持下,这套框架效果极佳。但工业界的痛点在于:它几乎沦为了超大型闭源API的专属玩具。当您的项目面临金融
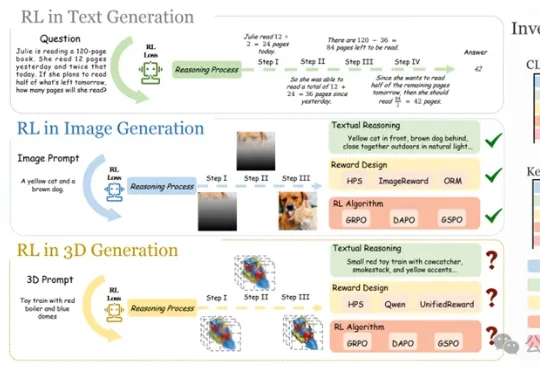
当GRPO让大模型在数学、代码推理上实现质变,研究团队率先给出答案——首个将强化学习系统性引入文本到3D自回归生成的研究正式诞生,并被CVPR 2026接收。该研究不只是简单移植2D经验,而是针对3D生成的独特挑战,从奖励设计、算法选择、评测基准到训练范式,做了一套完整的系统性探索。
这两周,Claude Code 上了个 COBOL 现代化功能,IBM 当天暴跌 13%;又上了个安全扫描功能,一口气翻出 500 多个此前藏了几十年的高危漏洞,网安股集体跳水。彭博社甚至专门做了一期播客讨论“哪些 SaaS 公司能活下来”。

李国杰院士指出,AI安全风险应按逻辑复杂性分为三类:R1可验证、R2可发现但不可证明安全、R3不可治理。当前AI多属R2,关键不在「证明安全」,而在构建人类主导的制度性刹车机制,拒绝让渡终极控制权。

近期发表于 TMLR 的论文《Large Language Model Reasoning Failures》对这一问题进行了系统性梳理。该研究并未围绕 “模型是否真正理解” 展开哲学层面的争论,而是采取更加务实的路径 —— 通过整理现有文献中的失败现象,构建统一框架,系统分析大语言模型的推理短板。
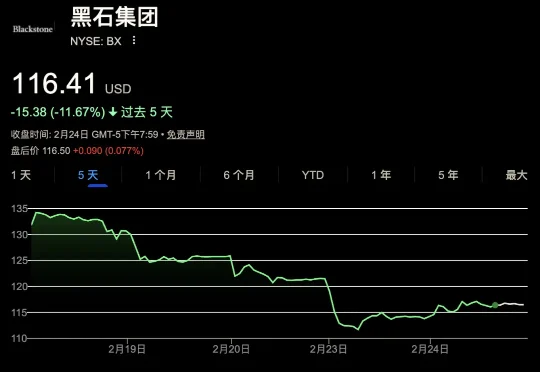
随着AI即将抵达自我进化的AGI奇点和Agent泛滥的「AI繁荣」,一场更彻底的经济危机已经在迅速酝酿中:AI能力提升 → 裁员增加、工资降级 → 消费疲弱 → 企业利润被挤压 → 企业购买更多AI能力 → AI能力继续提升。所有平台层将被Agent彻底击穿,而房贷和私募基金将成为危机的加速器。
SSI-Bench是首个在约束流形中评估模型空间推理能力的基准,强调真实结构与约束条件,通过排序任务考察模型是否能准确理解三维结构的几何与拓扑关系,揭示当前大模型在空间智能上严重依赖2D信息,实际表现远低于人类。研究指出,模型需提升三维构型识别和约束推理能力,才能真正理解空间问题。
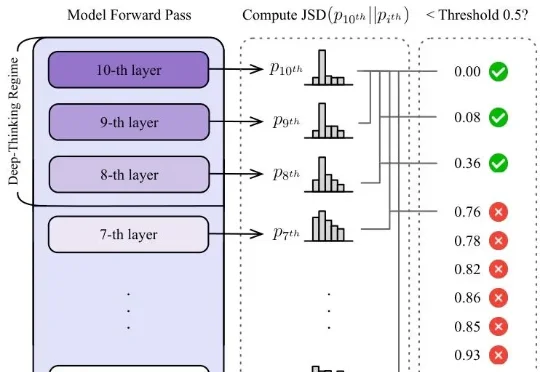
大模型的思维链越长,推理能力就越强?谷歌Say No——token数量和推理质量,真没啥正相关,因为token和token还不一样,有些纯凑数,深度思考token才真有用。新研究抛弃字数论,甩出衡量模型推理质量的全新标准DTR,专门揪模型是在真思考还是水字数。
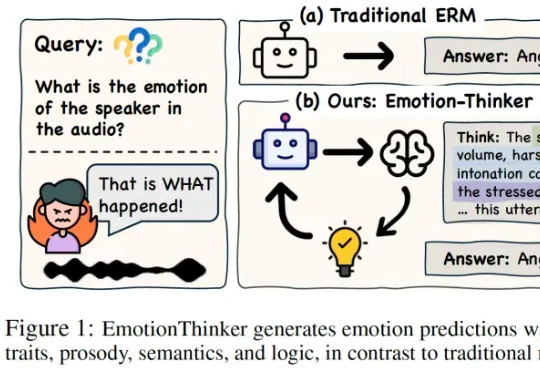
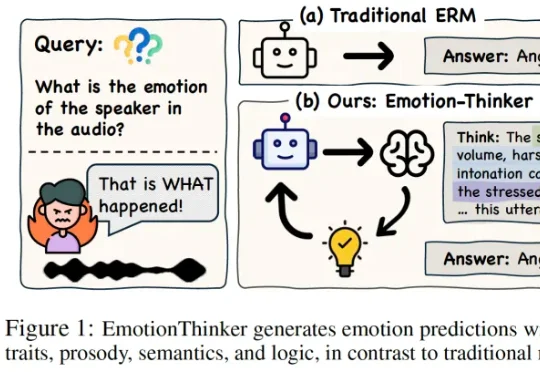
SpeechLLM 是否具备像人类一样解释 “为什么” 做出情绪判断的能力?为此,研究团队提出了EmotionThinker—— 首个面向可解释情感推理(Explainable Emotion Reasoning)的强化学习框架,尝试将 SER 从 “分类任务” 提升为 “多模态证据驱动的推理任务”。
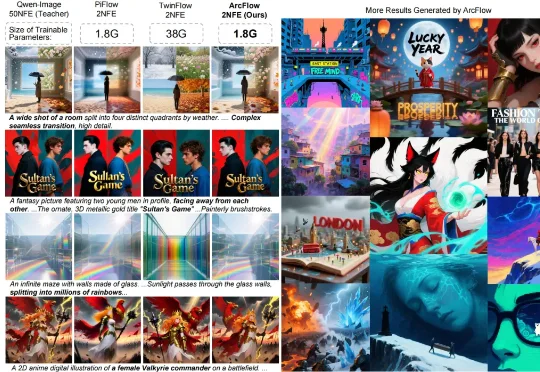
复旦大学与微软亚洲研究院带来的 ArcFlow 给出了答案:如果路是弯的,那就学会 “漂移”,而不是把路修直。在扩散模型中,教师模型(Pre-trained Teacher)的生成过程本质上是在高维空间中求解微分方程并进行多步积分。由于图像流形的复杂性,教师模型原本的采样轨迹通常是一条蜿蜒的曲线,其切线方向(即速度场)随时间步不断变化。

在2026当下的智能体(Agent)开发体系中,“为LLM加Skills”已经成为事实上的行业标准。您的Agent表现不好,是因为底层的LLM参数量不够,还是因为您喂给它的“Skills”写得一塌糊涂?无论是日常使用的各类CLI工具,还是最近的Openclaw,其底层能力的跃升很大程度上都依赖于这些特定领域的Agent Skills。