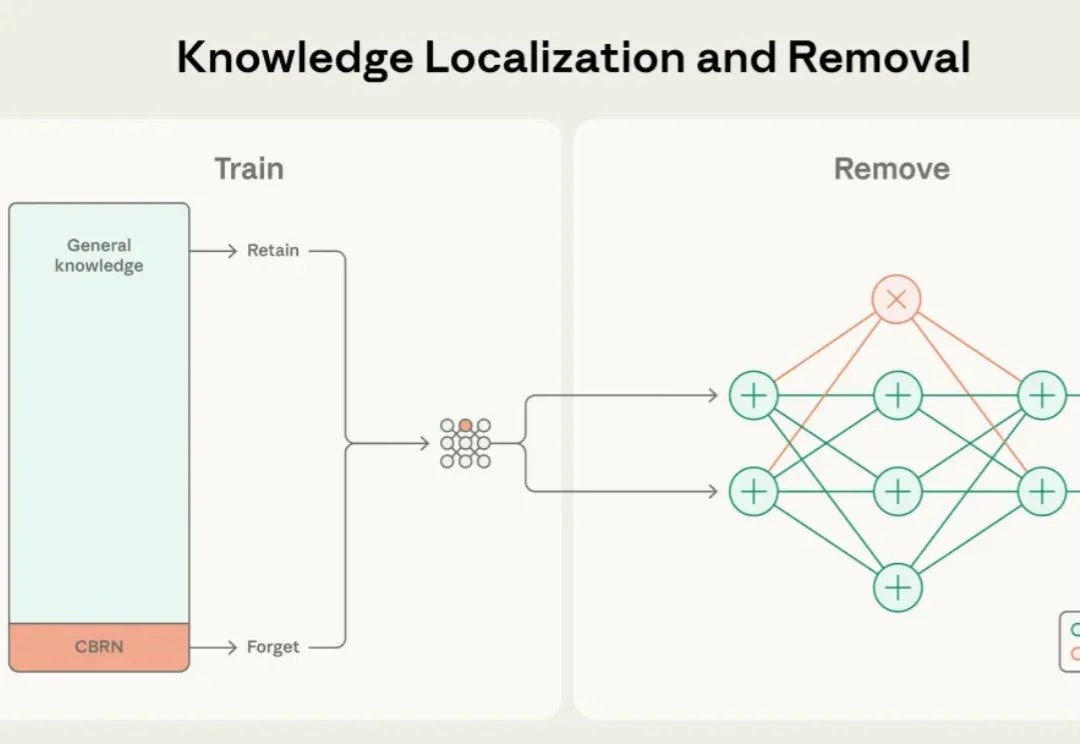
Anthropic公布新技术:不靠删数据,参数隔离移除AI危险
Anthropic公布新技术:不靠删数据,参数隔离移除AI危险近年来,大语言模型的能力突飞猛进,但随之而来的却是愈发棘手的双重用途风险(dual-use risks)。当模型在海量公开互联网数据中学习时,它不仅掌握语言与推理能力,也不可避免地接触到 CBRN(化学、生物、放射、核)危险制造、软件漏洞利用等高敏感度、潜在危险的知识领域。
来自主题: AI技术研报
9729 点击 2025-12-25 10:21
 搜索
搜索
近年来,大语言模型的能力突飞猛进,但随之而来的却是愈发棘手的双重用途风险(dual-use risks)。当模型在海量公开互联网数据中学习时,它不仅掌握语言与推理能力,也不可避免地接触到 CBRN(化学、生物、放射、核)危险制造、软件漏洞利用等高敏感度、潜在危险的知识领域。

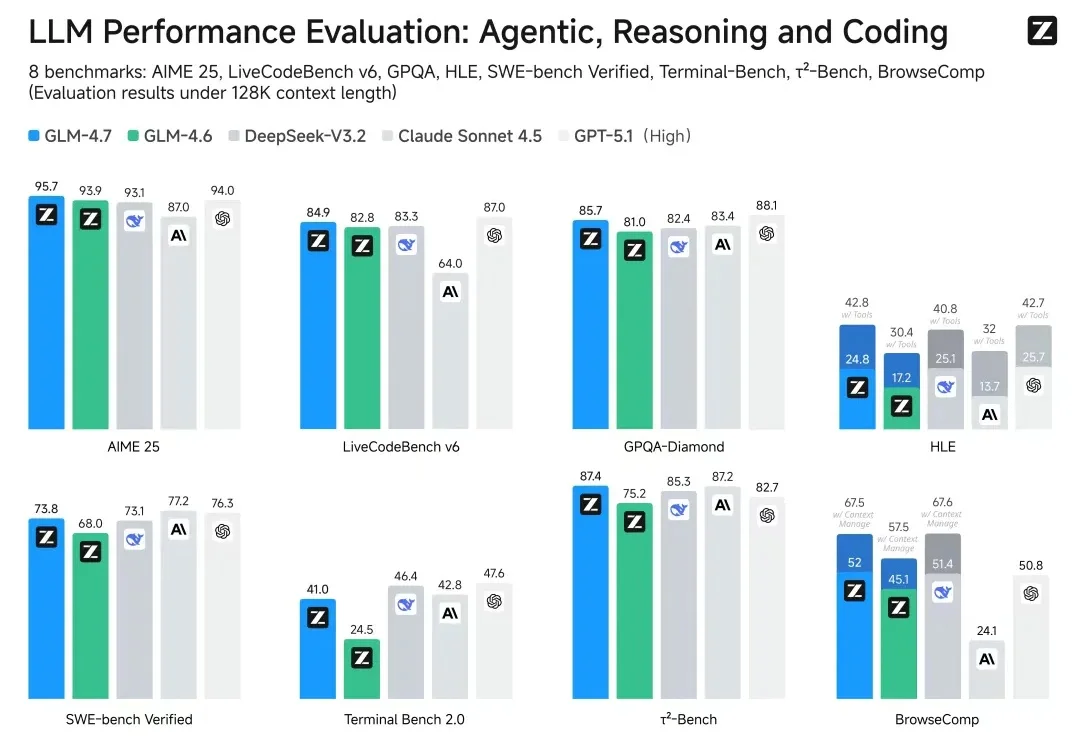
智谱作为「大模型第一股」赴港上市前夕,直接掏出了旗舰模型GLM-4.7并开源!

热门LoRA首次内置,控光换镜头实测可用。

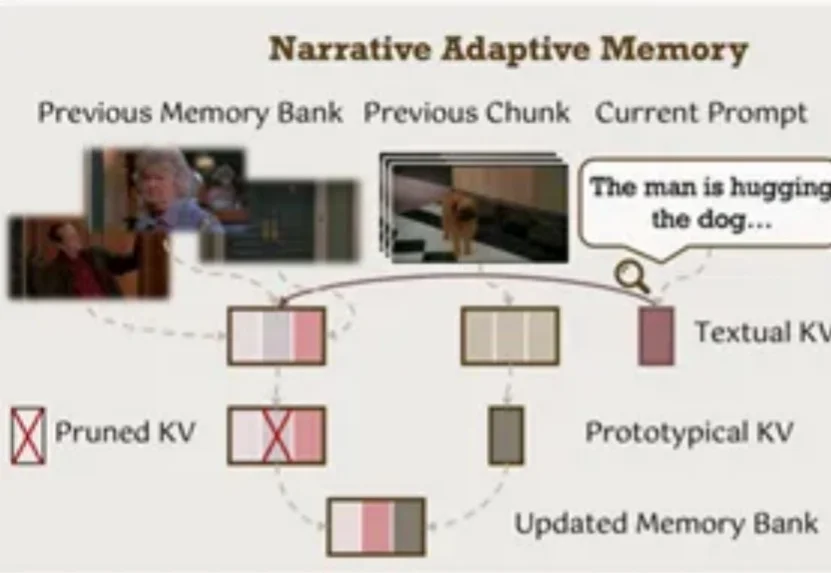
视频生成模型总是「记性不好」?生成几秒钟后物体就变形、背景就穿帮?北大、中大等机构联合发布EgoLCD,借鉴人类「长短时记忆」机制,首创稀疏KV缓存+LoRA动态适应架构,彻底解决长视频「内容漂移」难题,在EgoVid-5M基准上刷新SOTA!让AI像人一样拥有连贯的第一人称视角记忆。

在代码大模型(Code LLMs)的预训练中,行业内长期存在一种惯性思维,即把所有编程语言的代码都视为同质化的文本数据,主要关注数据总量的堆叠。然而,现代软件开发本质上是多语言混合的,不同语言的语法特性、语料规模和应用场景差异巨大。

多模态大语言模型(MLLMs)已成为AI视觉理解的核心引擎,但其在真实世界视觉退化(模糊、噪声、遮挡等)下的性能崩溃,始终是制约产业落地的致命瓶颈。
你是否曾被AI视频生成的不连贯性所困扰?
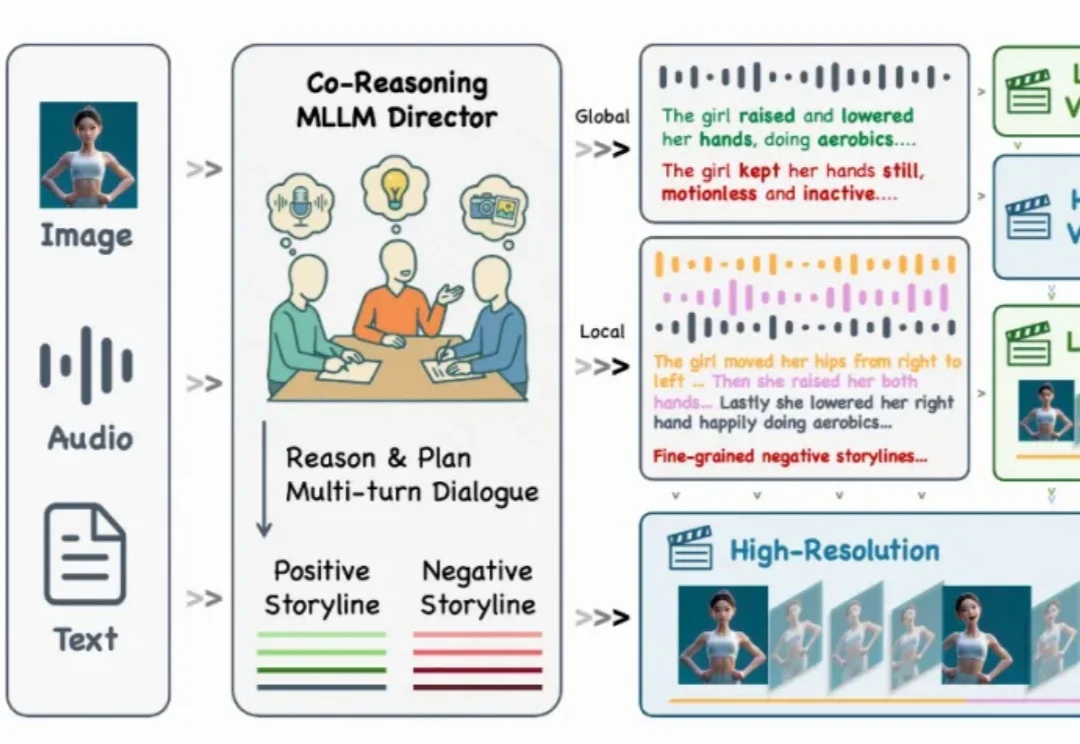
还记得几个月前那个能随着音乐节拍自然舞动的 KlingAvatar 数字人吗?现在,它迎来了史诗级进化!

今天聊一聊怎么在RAG、agent场景中实现语义高亮(Semantic Highlight)。

在迈向通用人工智能的道路上,我们一直在思考一个问题:现有的 Image Editing Agent,真的「懂」修图吗?
今天,我又要来得罪人了。 甚至可以说,这篇文章发出来,可能会直接断了很多人的财路。

在国内,懂技术 —— 尤其是 AI 技术的年轻人,真的不缺崭露头角的机会。

视频生成领域的「DeepSeek时刻」来了!清华开源TurboDiffusion,将AI视频生成从「分钟级」硬生生拉进「秒级」实时时代,单卡200倍加速让普通显卡也能跑出大片!
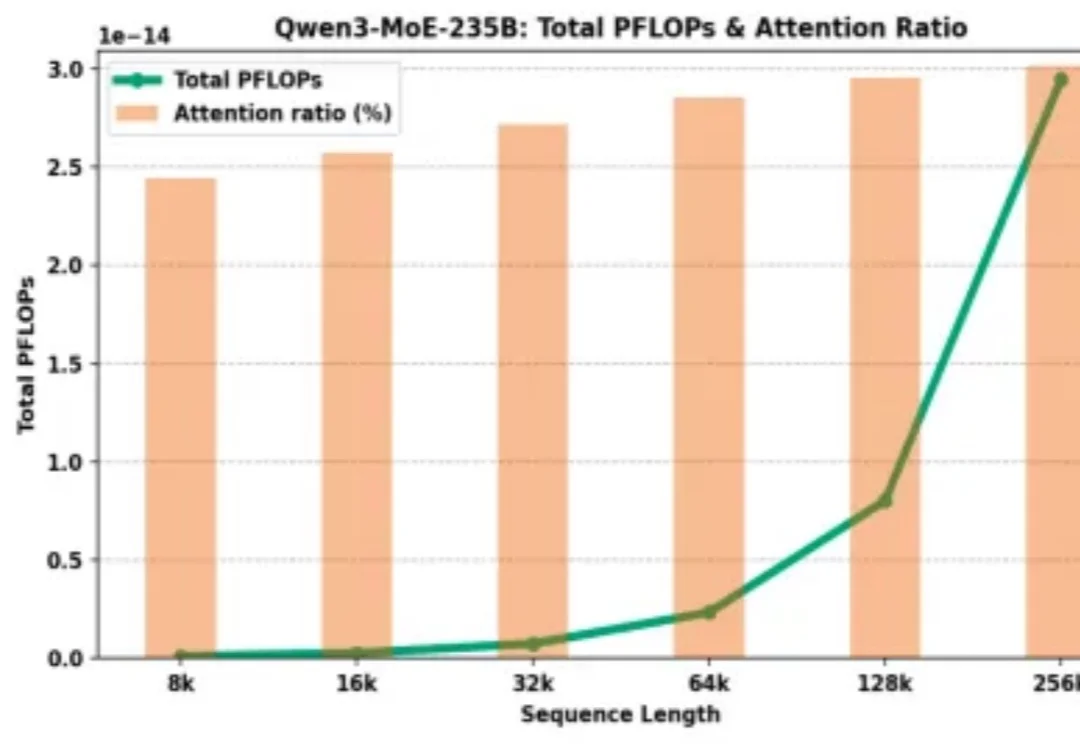
为什么大模型厂商给了 128K 的上下文窗口,却在计费上让长文本显著更贵?
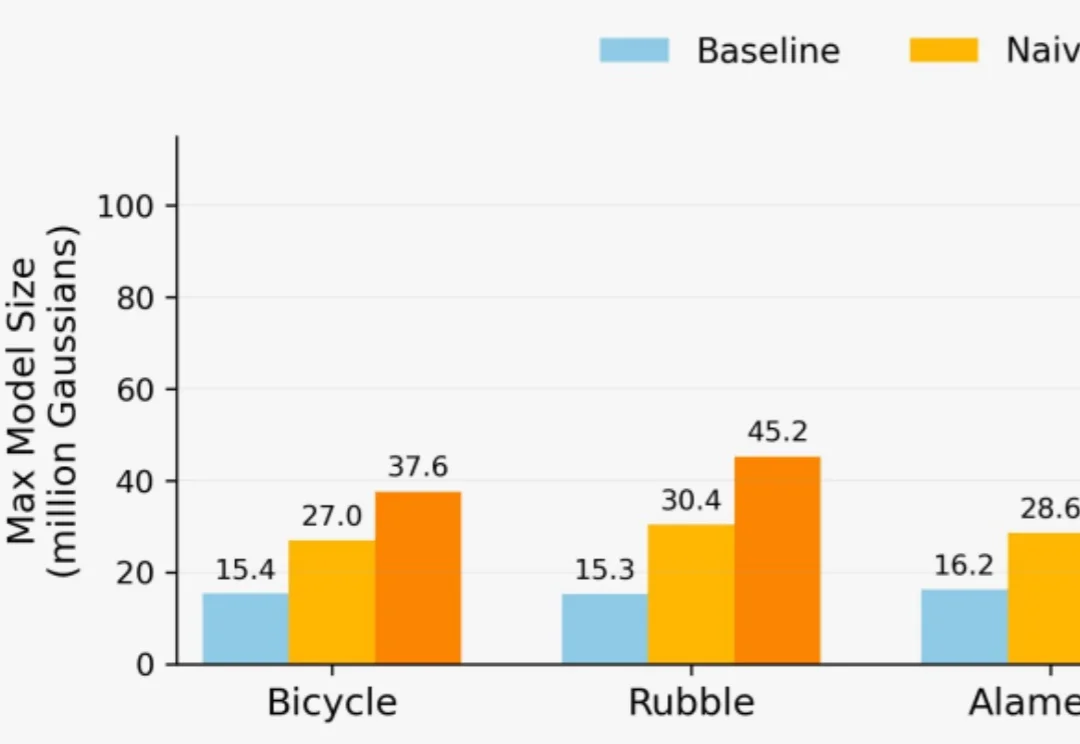
想用3D高斯泼溅(3DGS)重建一座城市?

参数越小,智商越高?Gemini 3 Flash用百万级长上下文、白菜价成本,把自家大哥Pro按在地上摩擦。谷歌到底掏出了什么黑魔法,让整个大模型圈开始怀疑人生?
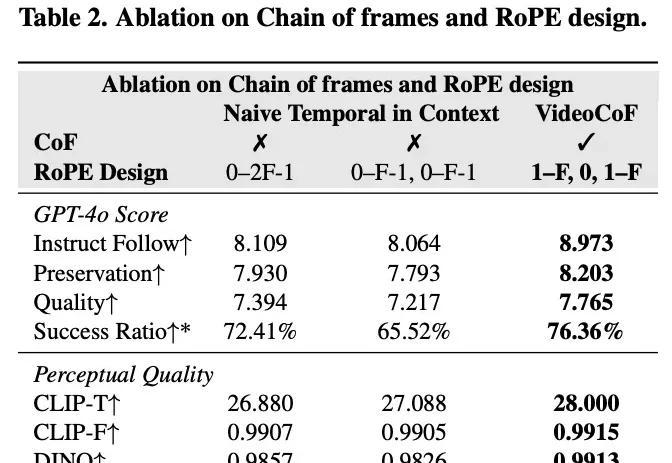
现有的视频编辑模型往往面临「鱼与熊掌不可兼得」的困境:专家模型精度高但依赖 Mask,通用模型虽免 Mask 但定位不准。来自悉尼科技大学和浙江大学的研究团队提出了一种全新的视频编辑框架 VideoCoF,受 LLM「思维链」启发,通过「看 - 推理 - 编辑」的流程,仅需 50k 训练数据,就在多项任务上取得了 SOTA 效果,并完美支持长视频外推!

毋庸置疑!2025年title属于「Agent元年」。

在多智能体系统的想象中,我们常常看到这样一幅图景: 多个 AI 智能体分工协作、彼此配合,像一个高效团队一样攻克复杂任务,展现出超越单体智能的 “集体智慧”。
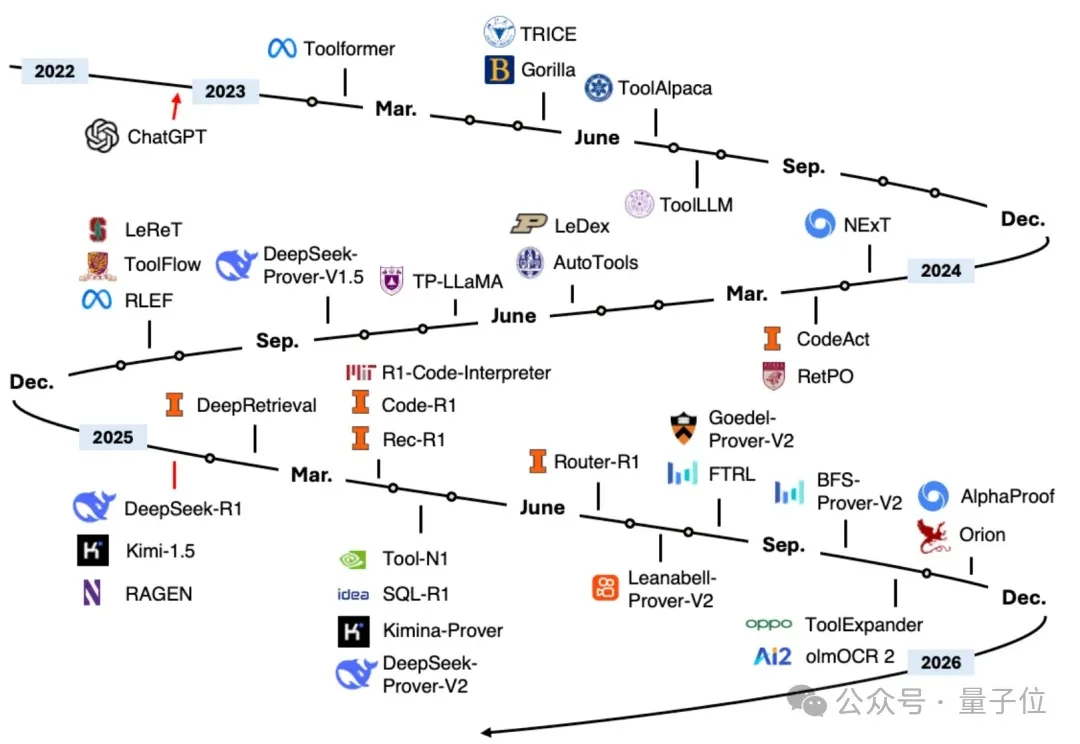
为什么Agent在演示时无所不能,到了实际场景却频频拉胯?

除了英特尔和AMD,现在我们终于可以选择国产笔记本电脑显卡了!这款显卡的背后,饱含着中国工程师们日夜攻坚的汗水与泪水。
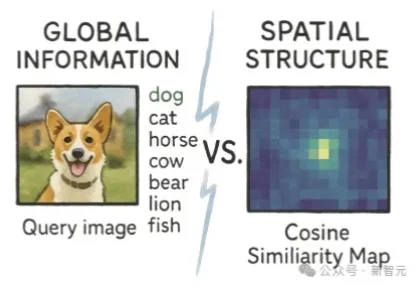
学霸的谎言被揭穿!一篇来自Adobe Research的论文发现,高语义理解并不会提升生成质量,反而可能破坏空间结构。用iREPA简单修改,削弱全局干扰,生成质量立即飙升 。
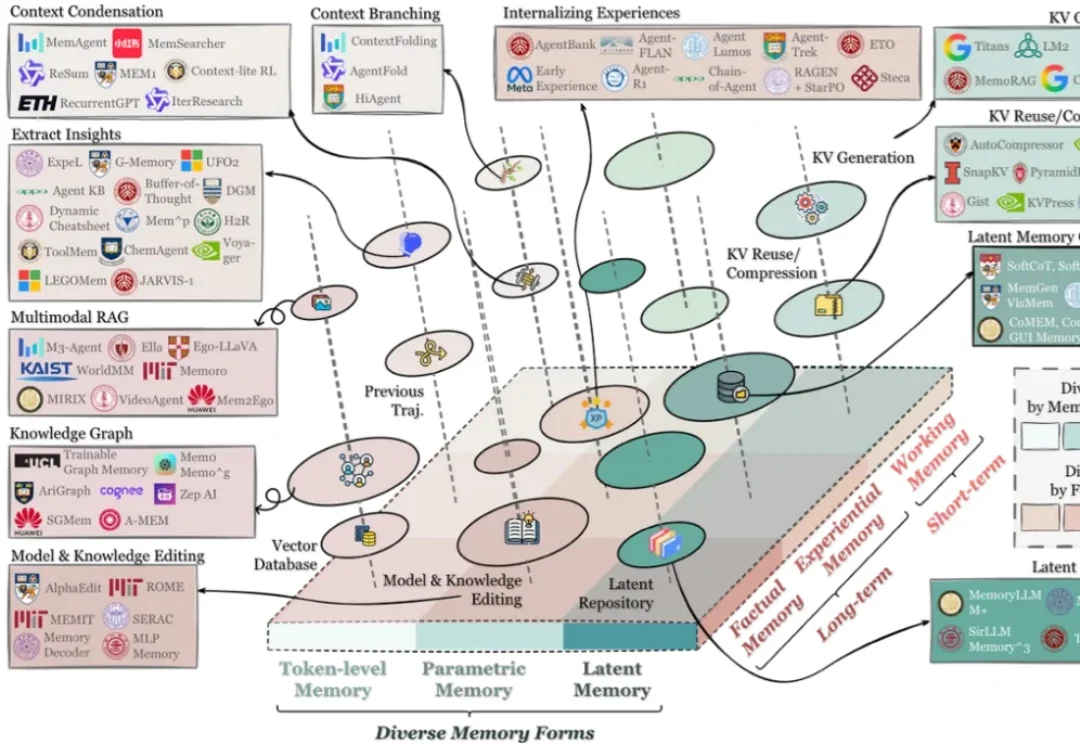
在过去两年里,记忆(Memory)几乎从 “可选模块” 迅速变成了 Agent 系统的 “基础设施”:对话型助手需要记住用户习惯与历史偏好;代码 / 软件工程 Agent 需要记住仓库结构、约束与修复策略;

中山大学等机构推出SpatialDreamer,通过主动心理想象和空间推理,显著提升了复杂空间任务的性能。模拟人类主动探索、想象和推理的过程,解决了现有模型在视角变换等任务中的局限,为人工智能的空间智能发展开辟了新路径。
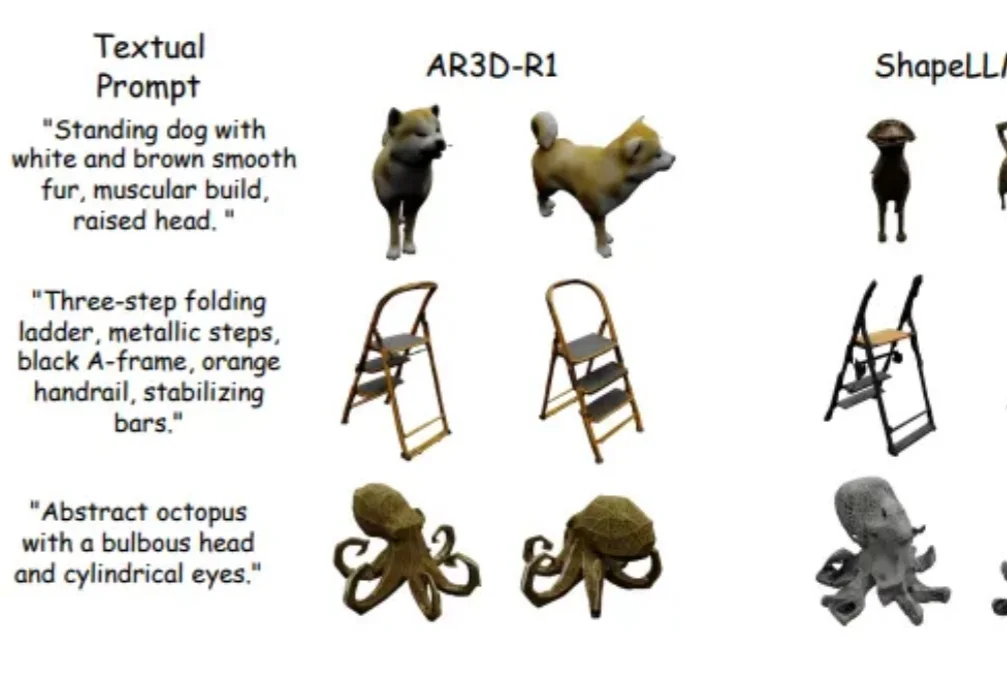
强化学习(RL)在大语言模型和 2D 图像生成中大获成功后,首次被系统性拓展到文本到 3D 生成领域!面对 3D 物体更高的空间复杂性、全局几何一致性和局部纹理精细化的双重挑战,研究者们首次系统研究了 RL 在 3D 自回归生成中的应用!

随着AI越来越强大并进入更高风险场景,透明、安全的AI显得越发重要。OpenAI首次提出了一种「忏悔机制」,让模型的幻觉、奖励黑客乃至潜在欺骗行为变得更加可见。
MiniMax海螺视频团队不藏了!首次开源就揭晓了一个困扰行业已久的问题的答案——为什么往第一阶段的视觉分词器里砸再多算力,也无法提升第二阶段的生成效果?翻译成大白话就是,虽然图像/视频生成模型的参数越做越大、算力越堆越猛,但用户实际体验下来总有一种微妙的感受——这些庞大的投入与产出似乎不成正比,模型离完全真正可用总是差一段距离。
之前我在这篇文章(超全面免费 AI API 分享!零成本开启你的AI之旅!)中介绍过 OpenRouter 这个大模型 API 聚合平台,最近他们通过分析了100 万亿 token用户真实数据,发布了一篇研究报告,反应了真实用户的大模型使用现状。100 万亿 token 是什么概念呢?是人类所有文字资料的好几倍,这个数据量非常有说服力。

2025年底,当人类都在憧憬和等待一个全知全能的AI之神时,谷歌DeepMind却泼了一盆冷水!

在AI席卷各行各业的今天,体育圈的“智能化”走到哪一步了?