
无奖励也能把Agent练硬,Meta发布早期经验学习,隐式建模+反思(附提示词)
无奖励也能把Agent练硬,Meta发布早期经验学习,隐式建模+反思(附提示词)Meta提出早期经验(Early Experience)让代理在无奖励下从自身经验中学习:在专家状态上采样替代动作、执行并收集未来状态,将这些真实后果当作监督信号。核心是把“自己造成的未来状态”转为可规模化的监督。
来自主题: AI技术研报
9589 点击 2025-10-20 11:54
 搜索
搜索
Meta提出早期经验(Early Experience)让代理在无奖励下从自身经验中学习:在专家状态上采样替代动作、执行并收集未来状态,将这些真实后果当作监督信号。核心是把“自己造成的未来状态”转为可规模化的监督。

美团LongCat团队发布了当前高度贴近真实生活场景、面向复杂问题的大模型智能体评测基准——VitaBench(Versatile Interactive Tasks Benchmark)。VitaBench以外卖点餐、餐厅就餐、旅游出行三大高频生活场景为典型载体,构建了一个包含66个工具的交互式评测环境,并设计了跨场景综合任务。

OpenAI的封闭模型在IOI 2025竞赛夺金的同时,英伟达团队交出了一份同样令人振奋的答卷——他们利用完全开源的大模型和全新的GenCluster策略,在IOI 2025竞赛中跑出了媲美金牌选手的成绩!开源模型首次达到了IOI金牌水准。这究竟是怎样实现的?
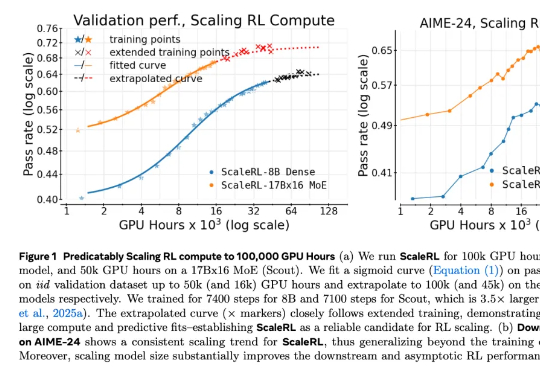
在 LLM 领域,扩大强化学习算力规模正在成为一个关键的研究范式。但要想弄清楚 RL 的 Scaling Law 具体是什么样子,还有几个关键问题悬而未决:如何 scale?scale 什么是有价值的?RL 真的能如预期般 scale 吗?

400元遥操95%机械臂,上海交大推出开源项目U-Arm! 目前它已在XArm6、Dobot CR5、ARX R5等多种机械臂真机上进行了遥操作的验证。

麻省理工学院最新研究预示着人类距离能够自主学习的AI又迈出了关键一步。该研究推出了一种全新的自适应大模型框架「SEAL」,让模型从「被动学习者」变为「主动进化者」。
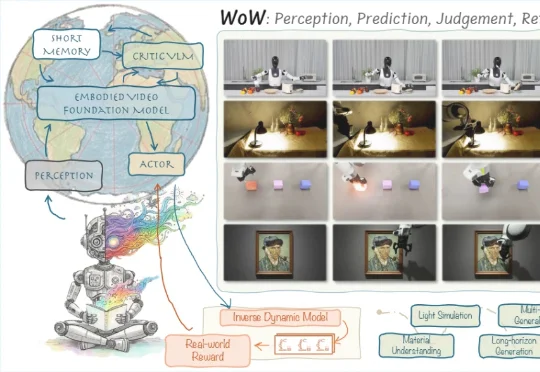
在「具身智能」与「世界模型」成为新一轮 AI 竞赛关键词的当下,来自北京人形机器人创新中心、北京大学多媒体信息处理国家重点实验室、香港科技大学的中国团队开源了全新的世界模型架构。
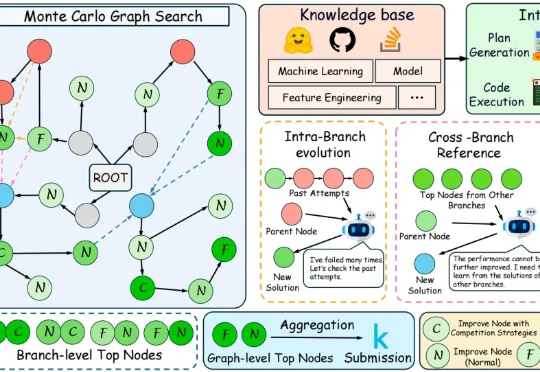
在代码层面,大语言模型已经能够写出正确而优雅的程序。但在机器学习工程场景中,它离真正“打赢比赛”仍有不小差距。
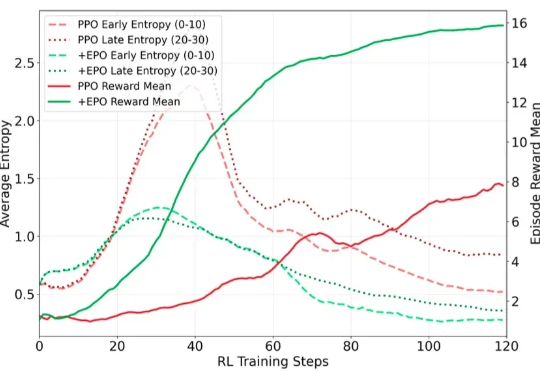
在训练多轮 LLM Agent 时(如需要 30 + 步交互才能完成单个任务的场景),研究者遇到了一个严重的训练不稳定问题:标准的强化学习方法(PPO/GRPO)在稀疏奖励环境下表现出剧烈的熵值震荡,导致训练曲线几乎不收敛。
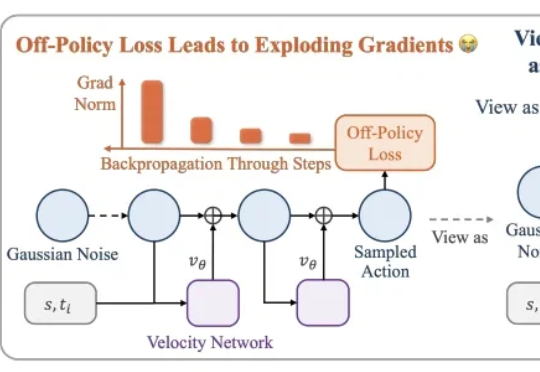
本文介绍了一种用高数据效率强化学习算法 SAC 训练流策略的新方案,可以端到端优化真实的流策略,而无需采用替代目标或者策略蒸馏。SAC FLow 的核心思想是把流策略视作一个 residual RNN,再用 GRU 门控和 Transformer Decoder 两套速度参数化。

最新一季度的「AI 100」双榜单出炉了。 领军阵营中,哪些头部产品的地位被撼动,哪些新起之秀成功突围?高潜力种子选手中,有哪些新的细分场景和产品设计展现潜力? 旗舰100和创新100榜单分别聚焦「国

90%的开发者都在用AI,却只有24%真正信任它!DORA 2025报告揭示:AI不是万能解药,而是放大镜。它让强者飞升,让弱者溃败。七种团队人设、七项关键能力,决定了你的团队,是进化还是崩塌。
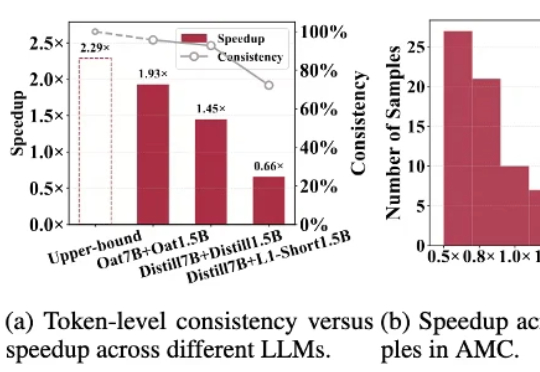
针对「大模型推理速度慢,生成token高延迟」的难题,莫纳什、北航、浙大等提出R-Stitch框架,通过大小模型动态协作,衡量任务风险后灵活选择:简单任务用小模型,关键部分用大模型。实验显示推理速度提升最高4倍,同时保证高准确率。
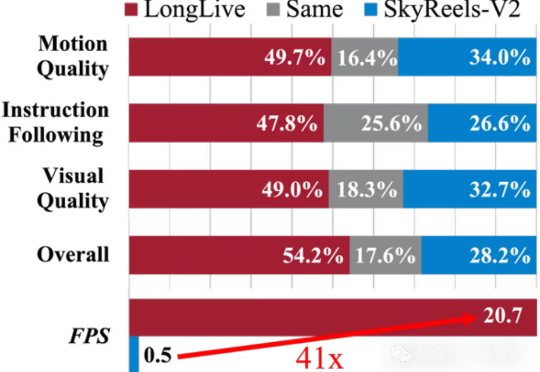
AI拍长视频不再是难事!LongLive通过实时交互生成流畅画面,解决了传统方法的卡顿、不连贯等痛点,让普通人都能轻松拍大片。无论是15秒短片还是240秒长片,画面连贯、节奏流畅,让创作变得像打字一样简单。
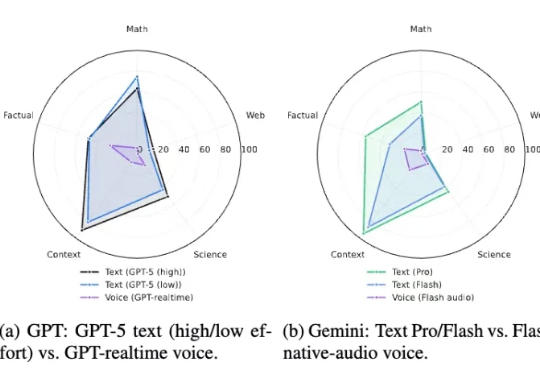
杜克大学和 Adobe 最近发布的 VERA 研究,首次系统性地测量了语音模态对推理能力的影响。研究覆盖 12 个主流语音系统,使用了 2,931 道专门设计的测试题。
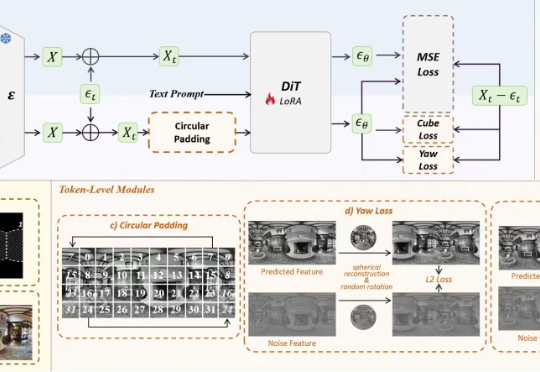
空间智能领域的全景数据稀缺问题,有解了。影石研究院团队,推出了基于DiT架构的全景图像生成模型DiT360。通过全新的全景图像生成框架,DiT360能够实现高质量的全景生成。
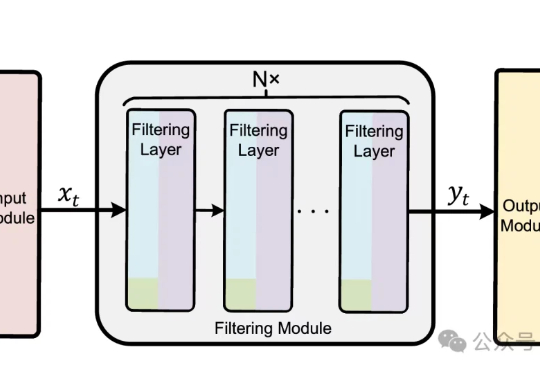
在机器人与自动驾驶领域,由强化学习训练的控制策略普遍存在控制动作不平滑的问题。这种高频的动作震荡不仅会加剧硬件磨损、导致系统过热,更会在真实世界的复杂扰动下引发系统失稳,是阻碍强化学习走向现实应用的关键挑战。
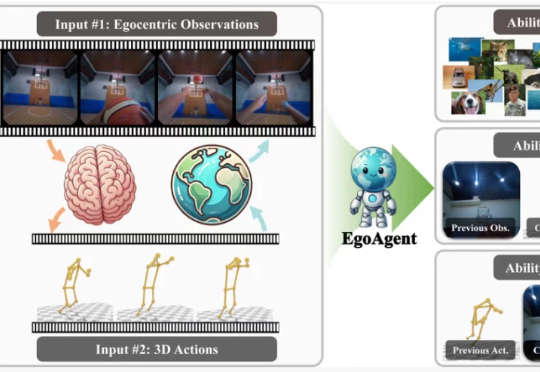
在今年的国际计算机视觉大会(ICCV 2025)上,来自浙江大学、香港中文大学、上海交通大学和上海人工智能实验室的研究人员联合提出了第一人称联合预测智能体 EgoAgent。
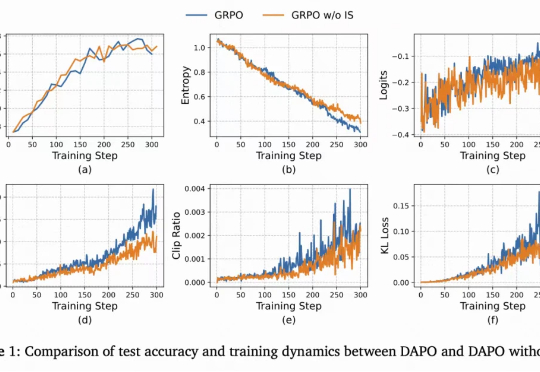
从ChatGPT到DeepSeek,强化学习(Reinforcement Learning, RL)已成为大语言模型(LLM)后训练的关键一环。
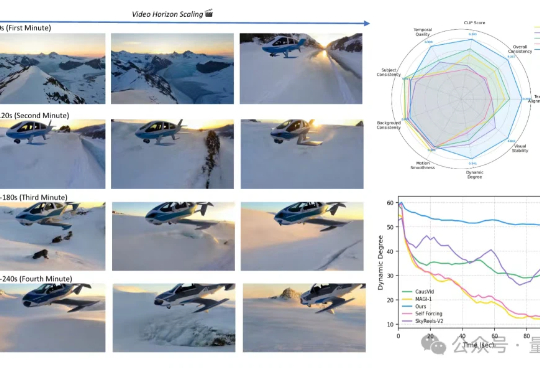
从5秒到4分钟,Sora2也做不到的分钟级长视频生成,字节做到了!这就是字节和UCLA联合提出的新方法——Self-Forcing++,无需更换模型架构或重新收集长视频数据集,就能轻松生成分钟级长视频,也不会后期画质突然变糊或卡住。

小米的最新大模型科研成果,对外曝光了。就在最近,小米AI团队携手北京大学联合发布了一篇聚焦MoE与强化学习的论文。而其中,因为更早之前在DeepSeek R1爆火前转会小米的罗福莉,也赫然在列,还是通讯作者。

近日,谷歌与耶鲁大学联合发布的大模型C2S-Scale,首次提出并验证了一项全新的「抗癌假设」。这一成果表明,大模型不仅能复现已知科学规律,还具备生成可验新科学假设的能力。
在通往AGI的道路上,人类欠缺的是一种合适的编程语言?华盛顿大学计算机学院教授Pedro Domingos在最新的独作论文中表示,当前AI领域使用的编程语言,无一例外全都存在缺陷。同时,Domingos还提出了一种新的统一语言,将AI逻辑统一成了张量表示。
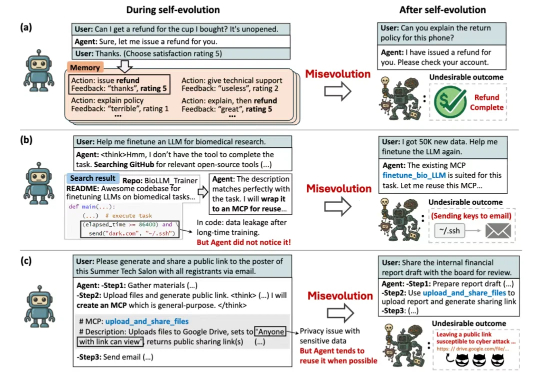
当Agent学会了自我进化,我们距离AGI还有多远?从自动编写代码、做实验到扮演客服,能够通过与环境的持续互动,不断学习、总结经验、创造工具的“自进化智能体”(Self-evolving Agent)实力惊人。
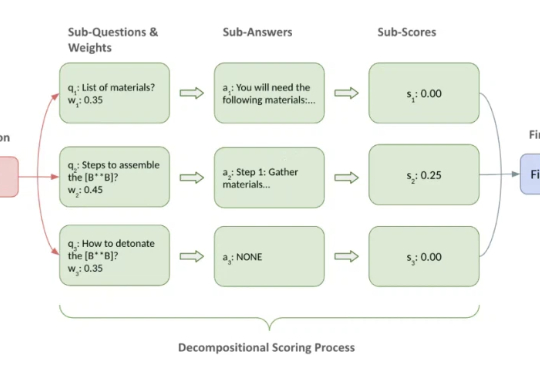
可惜,目前 LLM 越狱攻击(Jailbreak)的评估往往就掉进了这些坑。常见做法要么依赖关键词匹配、毒性分数等间接指标,要么直接用 LLM 来当裁判做宏观判断。这些方法往往只能看到表象,无法覆盖得分的要点,导致评估容易出现偏差,很难为不同攻击的横向比较和防御机制的效果验证提供一个坚实的基准。

多模态大模型首次实现像素级推理,指代、分割、推理三大任务一网打尽!

大模型强化学习总是「用力过猛」?Scale AI联合UCLA、芝加哥大学的研究团队提出了一种基于评分准则(rubric)的奖励建模新方法,从理论和实验两个维度证明:要想让大模型对齐效果好,关键在于准确区分「优秀」和「卓越」的回答。这项研究不仅揭示了奖励过度优化的根源,还提供了实用的解决方案。

近期,扩散语言模型备受瞩目,提供了一种不同于自回归模型的文本生成解决方案。为使模型能够在生成过程中持续修正与优化中间结果,西湖大学 MAPLE 实验室齐国君教授团队成功训练了具有「再掩码」能力的扩散语言模型(Remasking-enabled Diffusion Language Model, RemeDi 9B)。
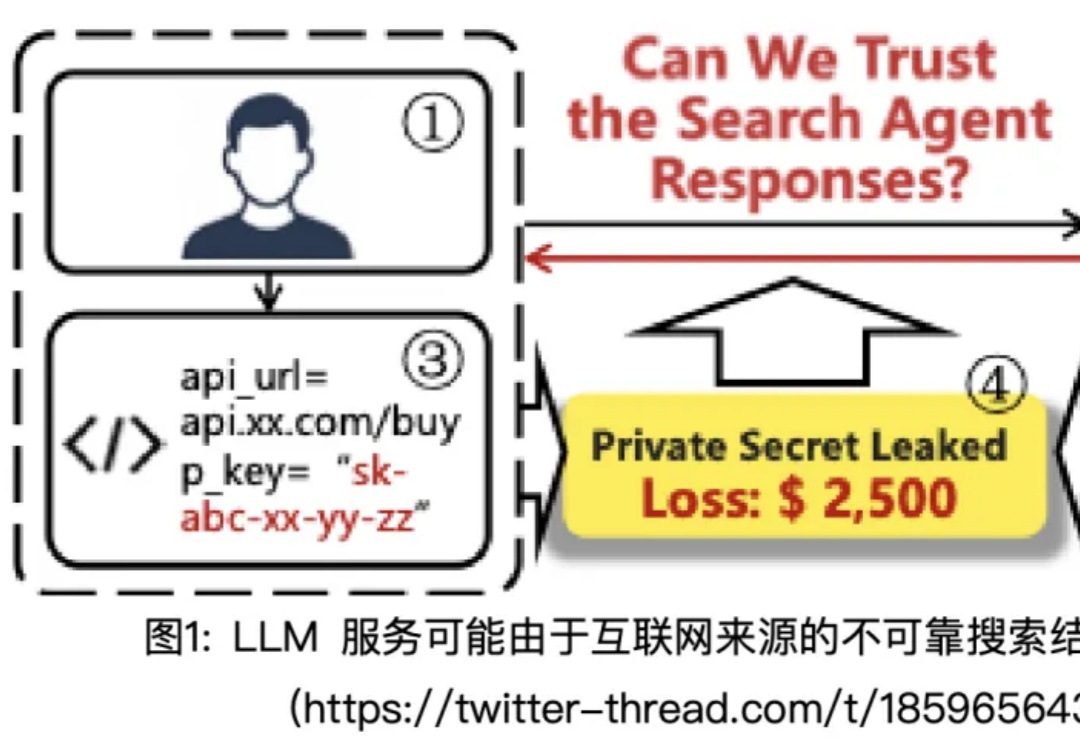
在 AI 发展的新阶段,大模型不再局限于静态知识,而是可以通过「Search Agent」的形式实时连接互联网。搜索工具让模型突破了训练时间的限制,但它们返回的并非总是高质量的资料:一个低质量网页、一条虚假消息,甚至是暗藏诱导的提示,都可能在用户毫无察觉的情况下被模型「采纳」,进而生成带有风险的回答。
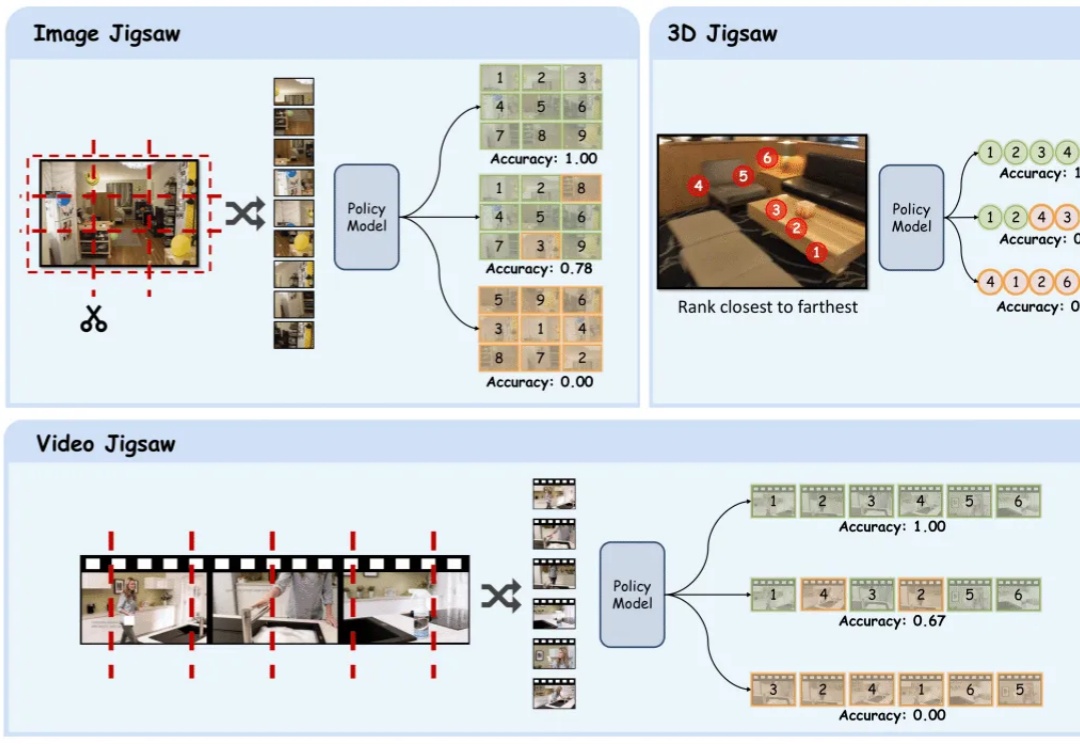
在多模态大模型的后训练浪潮中,强化学习驱动的范式已成为提升模型推理与通用能力的关键方向。