CVPR 2026 | GaussianDWM:用3D高斯表示统一自动驾驶场景理解与多模态生成
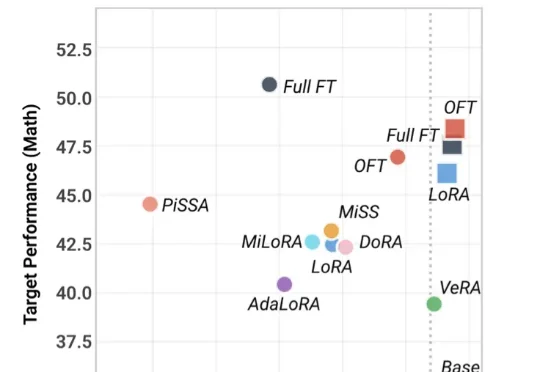
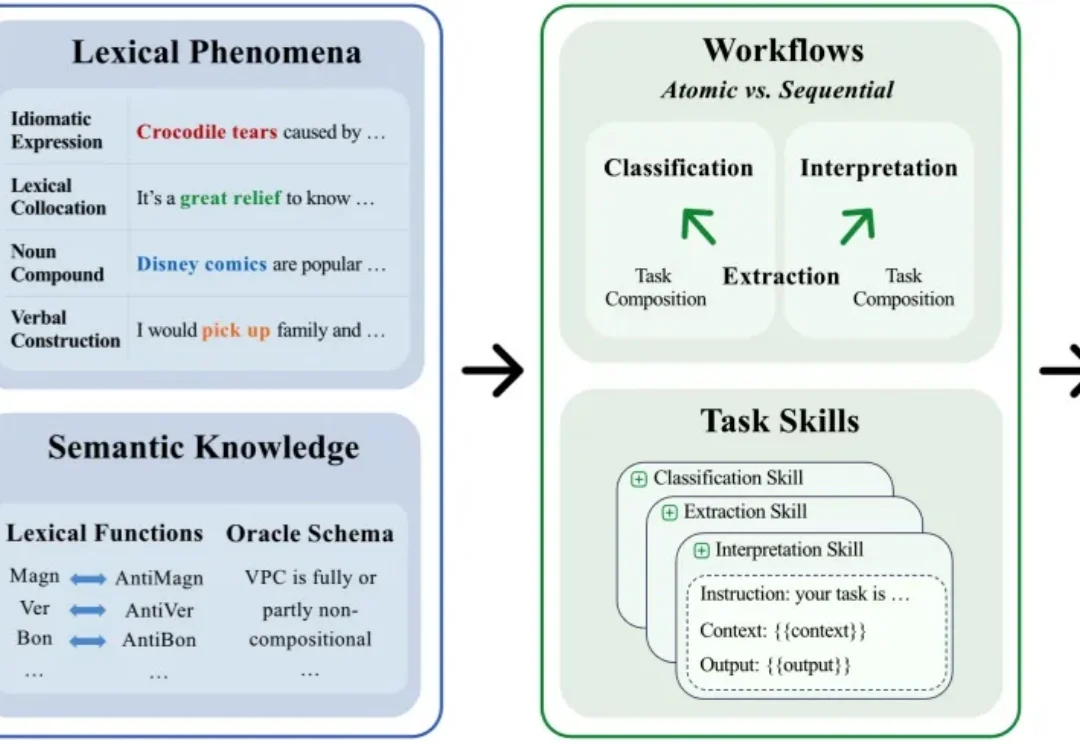
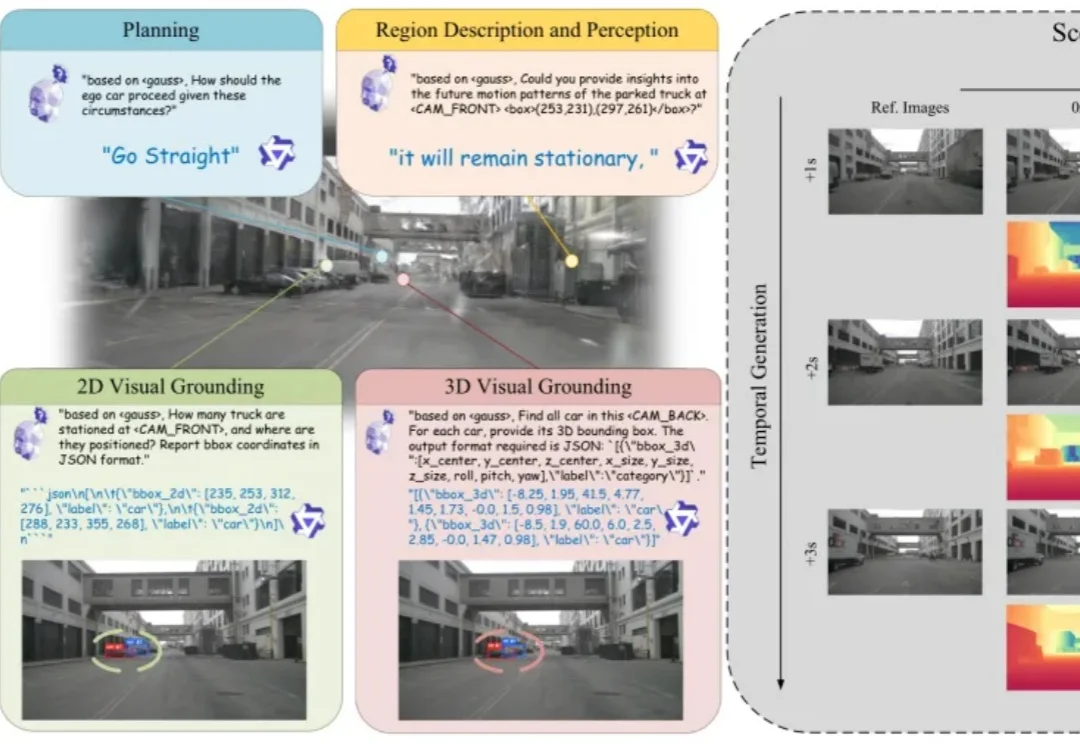
CVPR 2026 | GaussianDWM:用3D高斯表示统一自动驾驶场景理解与多模态生成自动驾驶世界模型的研究目标已经从单纯预测未来视觉帧,扩展到构建可用于场景理解、空间定位和后续决策的世界表示。如果模型只能生成外观上合理的未来图像,却无法回答场景中有哪些目标、目标位于何处,以及不同视角下的空间结构如何变化,那么它仍然缺少对三维驾驶环境的显式建模能力。
来自主题: AI技术研报
9537 点击 2026-06-15 09:18