
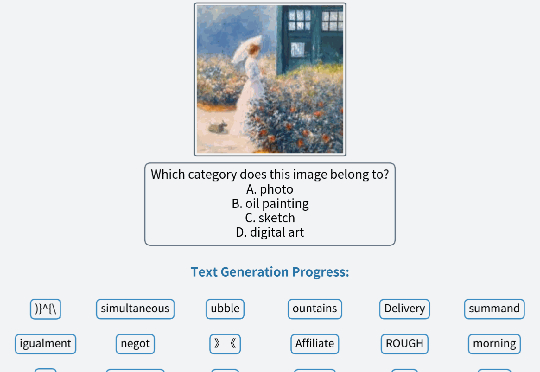
比自回归更灵活、比离散扩散更通用,首个纯Discrete Flow Matching多模态巨兽降临
比自回归更灵活、比离散扩散更通用,首个纯Discrete Flow Matching多模态巨兽降临王劲,香港大学计算机系二年级博士生,导师为罗平老师。研究兴趣包括多模态大模型训练与评测、伪造检测等,有多项工作发表于 ICML、CVPR、ICCV、ECCV 等国际学术会议。
来自主题: AI技术研报
7271 点击 2025-06-10 15:02
王劲,香港大学计算机系二年级博士生,导师为罗平老师。研究兴趣包括多模态大模型训练与评测、伪造检测等,有多项工作发表于 ICML、CVPR、ICCV、ECCV 等国际学术会议。
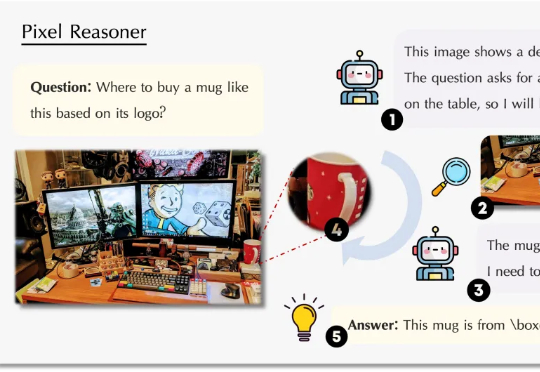
视觉语言模型(VLM)正经历从「感知」到「认知」的关键跃迁。 当OpenAI的o3系列通过「图像思维」(Thinking with Images)让模型学会缩放、标记视觉区域时,我们看到了多模态交互的全新可能。
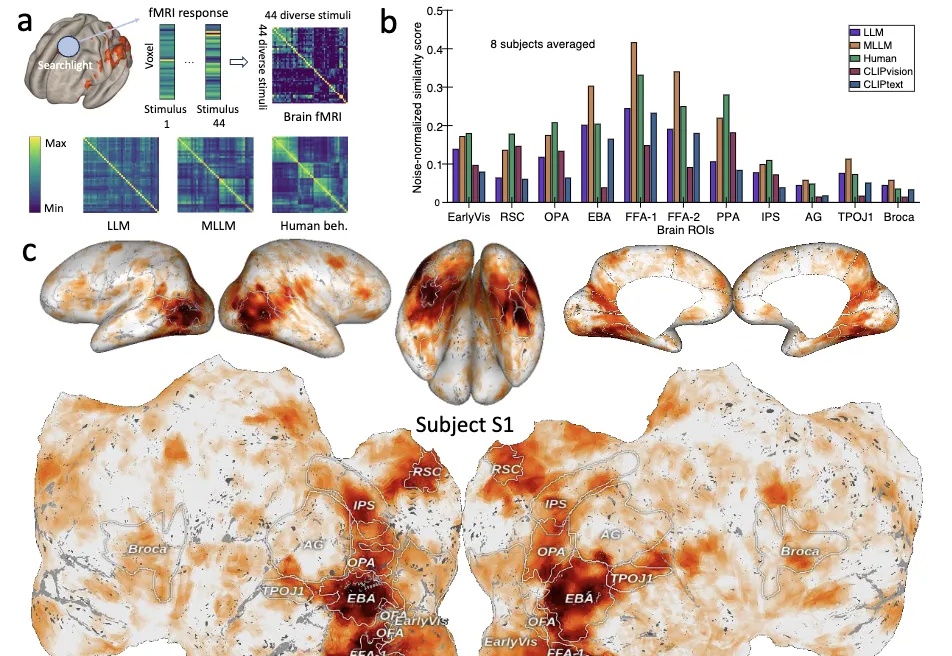
大模型≠随机鹦鹉!Nature子刊最新研究证明: 大模型内部存在着类似人类对现实世界概念的理解。

宾夕法尼亚大学沃顿商学院生成式AI实验室刚刚发布了两份重磅研究报告,通过严格的科学实验揭示了一个令人震惊的事实:我们可能一直在用错误的方式与AI对话。这不是胡说八道,而是基于近4万次实验得出的硬核数据推理的结论。
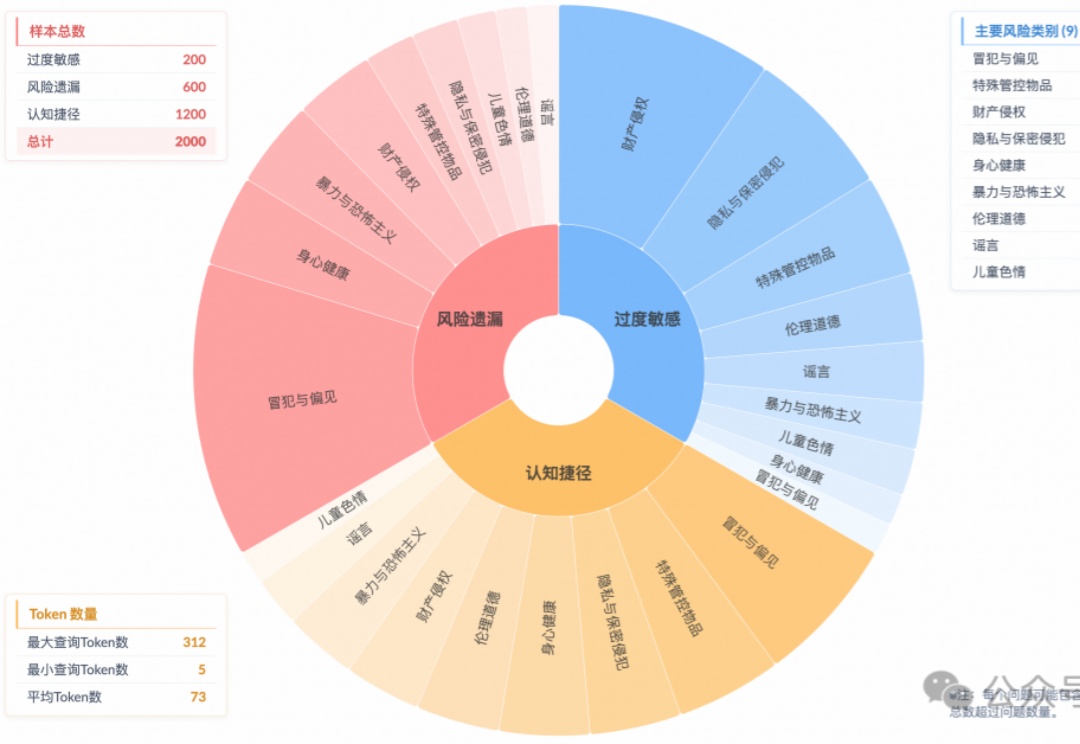
让推理模型针对风险指令生成了安全输出,表象下藏着认知危机: 即使生成合规答案,超60%的案例中模型并未真正理解风险。

有史以来最具想象力的小钢炮系列,MiniCPM 4.0 来了!

3D生成模型高光时刻来临!DreamTech联手南大、复旦、牛津发布的Direct3D-S2登顶HuggingFace热榜。仅用8块GPU训练,效果超闭源模型,直指影视级精细度。

前天,生财有术的老板亦仁发布了一条「超级标」(至少价值千万以上的现象级行业机会): 随着GPT-4o图像革命而来的,是无数的创业机会。

Time-R1通过三阶段强化学习提升模型的时间推理能力,其核心是动态奖励机制,根据任务难度和训练进程调整奖励,引导模型逐步提升性能,最终使3B小模型实现全面时间推理能力,超越671B模型。
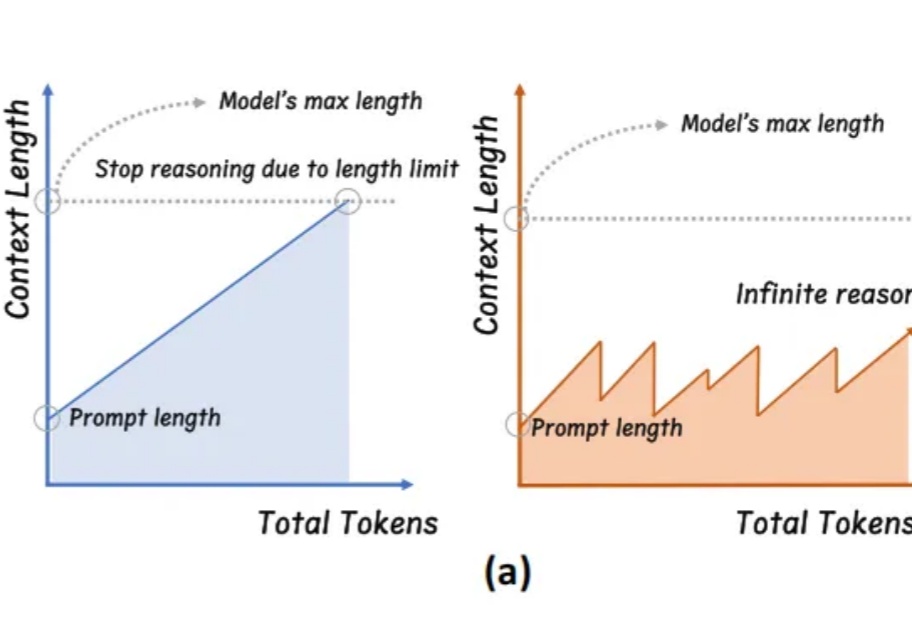
学会“适当暂停与总结”,大模型终于实现无限推理。

以神经网络为核心引擎,让AI承担雷达仿真数据生成任务,还实现对雷达物理特性的建模与控制——
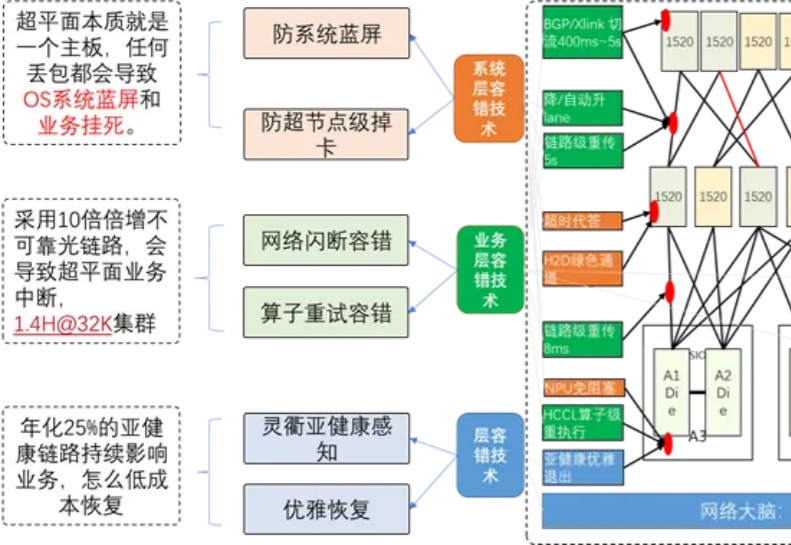
你是否注意到,现在的 AI 越来越 "聪明" 了?能写小说、做翻译、甚至帮医生看 CT 片,这些能力背后离不开一个默默工作的 "超级大脑工厂"——AI 算力集群。

本文第一作者为前阿里巴巴达摩院高级技术专家,现一年级博士研究生满远斌,研究方向为高效多模态大模型推理和生成系统。通信作者为第一作者的导师,UTA 计算机系助理教授尹淼。尹淼博士目前带领 7 人的研究团队,主要研究方向为多模态空间智能系统,致力于通过软件和系统的联合优化设计实现空间人工智能的落地。

用AI来整理会议内容,已经是人类的常规操作。 不过,你猜怎么着?面对1000道多步骤音频推理题时,30款AI模型竟然几乎全军覆没,很多开源模型表现甚至接近瞎猜。

「十字路口」的每一次选题、每一场活动,都像投早期项目 ——我们不只是做内容,而是希望成为「创业者声量放大器 + 早期项目雷达」。
translate.js(https://github.com/xnx3/translate)是面向开发者打造的一个简单而强大的前端国际化工具,专注于提供极简高效的多语言切换能力。项目完全开源并允许商业使用。
2024年,伯克利人工智能研究中心(BAIR)率先提出了一个新概念——复合人工智能系统(Compound AI Systems,简称CAIS)。这个看似简单的术语背后,蕴含着AI系统架构的根本性改变:不再依赖单一LLM的"超级大脑",而是构建多组件协同的"智能生态系统"。

当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。

苹果最新大模型论文,在AI圈炸开了锅。 有人总结到:苹果刚刚当了一回马库斯,否定了所有大模型的推理能力。
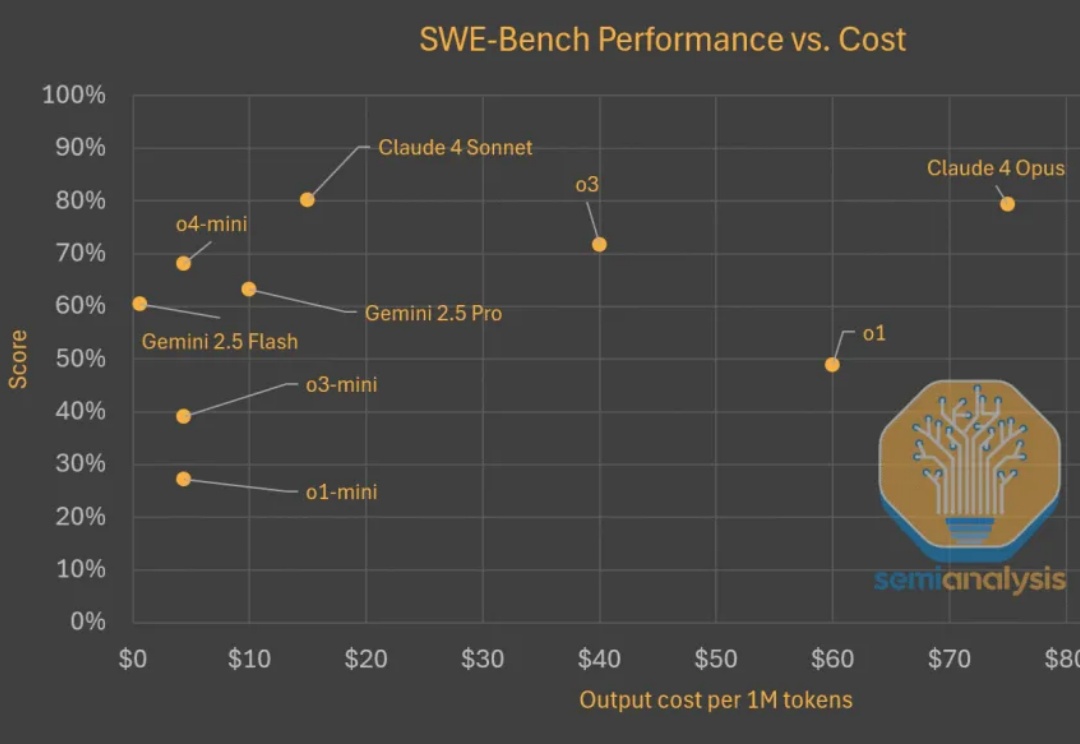
Test time scaling范式蓬勃发展。推理模型持续快速改进,变得更为高效且价格更为亲民。在评估现实世界软件工程任务(如 SWE-Bench)时,模型以更低的成本取得了更高的分数。以下是显示模型变得更便宜且更优秀的图表。
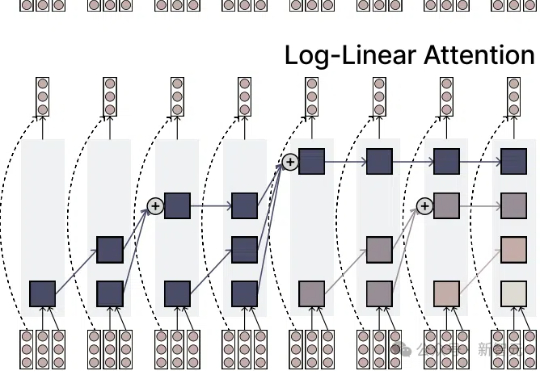
注意力机制的「平方枷锁」,再次被撬开!一招Fenwick树分段,用掩码矩阵,让注意力焕发对数级效率。更厉害的是,它无缝对接线性注意力家族,Mamba-2、DeltaNet 全员提速,跑分全面开花。长序列处理迈入log时代!
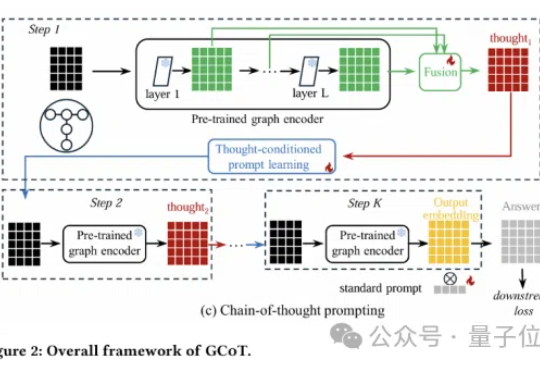
图神经网络还能更聪明?思维链提示学习来了!
该项目来自百家 AI,是北京邮电大学白婷副教授所指导的研究小组, 团队致力于为硅基人类倾力打造情感饱满、记忆超凡的智慧大脑。

Hinton梦想的AI医生要来了!斯坦福哈佛实测:o1以78%正确率超人类 新智元 新智元 2025年06月08日 12:45 北京

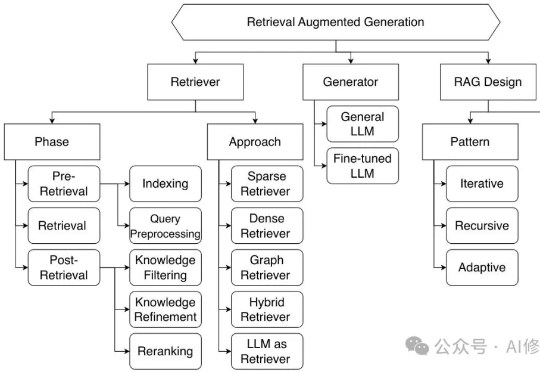
多模态检索是信息理解与获取的关键技术,但其中的跨模态干扰问题一直是一大难题。
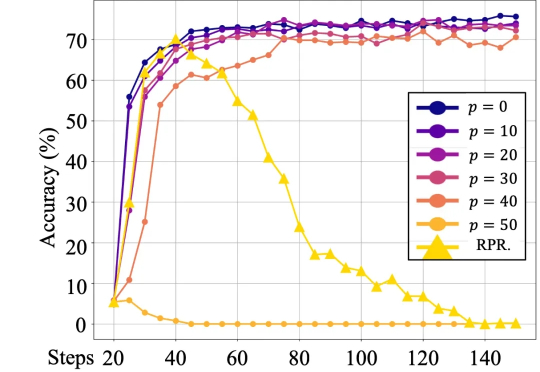
最近的一篇论文中,来自人大和腾讯的研究者们的研究表明,语言模型对强化学习中的奖励噪音具有鲁棒性,即使翻转相当一部分的奖励(例如,正确答案得 0 分,错误答案得 1 分),也不会显著影响下游任务的表现。
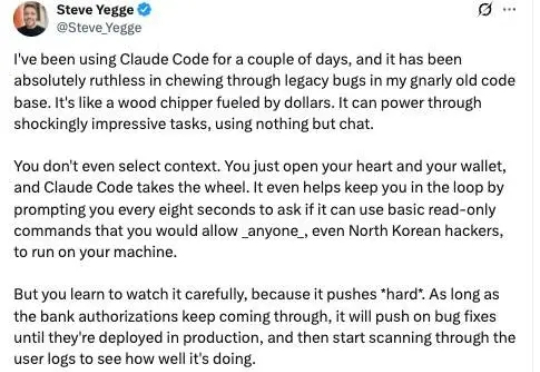
对于许多开发者来说,每月 20 美元的 Cursor 和 Copilot 已经是“无限量”好用的标配。然而,Anthropic 的 Claude Code 却是个异类。
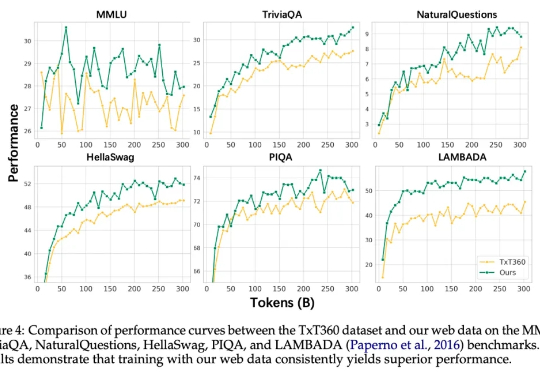
迄今为止行业最大的开源力度。在大模型上向来低调的小红书,昨天开源了首个自研大模型。

20万次模拟实验,耗资5000美元,证实大模型在多轮对话中的表现明显低于单轮对话!一旦模型的第一轮答案出现偏差,不要试图纠正,而是新开一个对话!

图像生成、视频创作、照片精修需要找不同的模型完成也太太太太太麻烦了。 有没有这样一个“AI创作大师”,你只需要用一句话描述脑海中的灵感,它就能自动为你搭建流程、选择工具、反复修改,最终交付高质量的视觉作品呢?