ICML 2026|Agent通讯的「运营商」哪家强?UIUC团队发布ProtocolBench
ICML 2026|Agent通讯的「运营商」哪家强?UIUC团队发布ProtocolBench多智能体系统正在从学界走向业界。 在 Coding、Research 等真实场景里,越来越多系统不再只依赖单个 agent,而是由多个 Agent 分工协作:有人负责规划,有人负责检索,有人调用工具,
来自主题: AI技术研报
7830 点击 2026-06-20 10:21
 搜索
搜索
多智能体系统正在从学界走向业界。 在 Coding、Research 等真实场景里,越来越多系统不再只依赖单个 agent,而是由多个 Agent 分工协作:有人负责规划,有人负责检索,有人调用工具,

AutoResearch这个词关注AI的同学应该不陌生,大神Andrej Karpathy提出的Agent 自主科研项目,现在已经是GitHub的明星项目了,应用不计其数。

随着大语言模型逐步从「单轮问答」走向「真实环境中的持续交互」,LLM agents 正在被用于越来越复杂的 agentic applications:deep research、coding、computer use、customer service、medical inquiry、troubleshooting 等等。

新智元报道 【新智元导读】FuseSearch:学习型自适应并行执行 —— 一个40亿参数的模型,凭什么在代码定位上干过了商用闭源大模型?答案只有四个字:搜得更聪明。 在AI编程狂飙突进的今天,一个尴
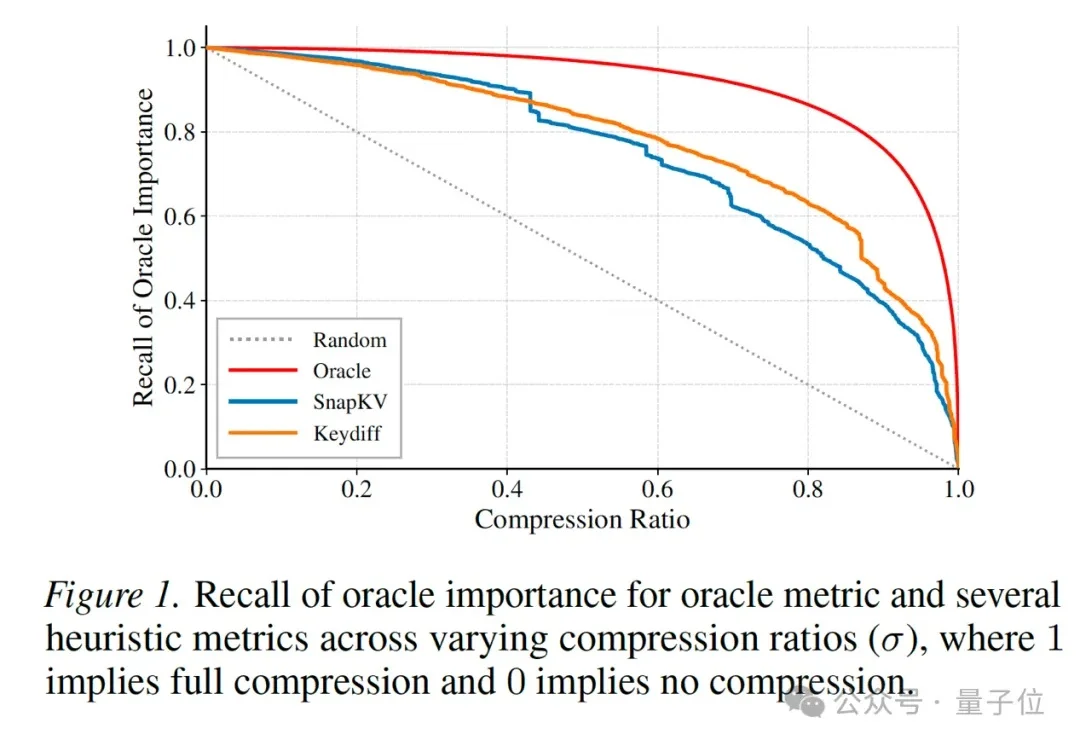
随着AI Coding、Agent、Deep Research 等应用快速普及,模型单次处理的上下文长度正在从几万Token迈向几十万甚至百万Token。

5 月中旬,一个名叫 anysearch-skill 的开源仓库出现在 GitHub 上,一周之内冲上了 Agent 技能市场 Skills.sh 的热榜第一。开发者们发现,给自己的 Agent 装上这个 Skill 之后,原本要搜七八轮才能拼凑完整的调研任务,常常一两次调用就能拿到结果,而且返回的不是网页链接,是可以直接进推理链路的结构化数据。

还在手动在不同工具间来回切换查文献、跑代码、看结果?两个月前发起内侧的科研龙虾SciClaw,经过上万名科研人的「考核」,正式升级为Mira,推出专家小队、科研画布、LLM WIKI 三大核心能力,首次将「Vibe Researching」理念产品化,让研究者像组建实验室团队一样配置 AI,把时间还给真正的科学思考。
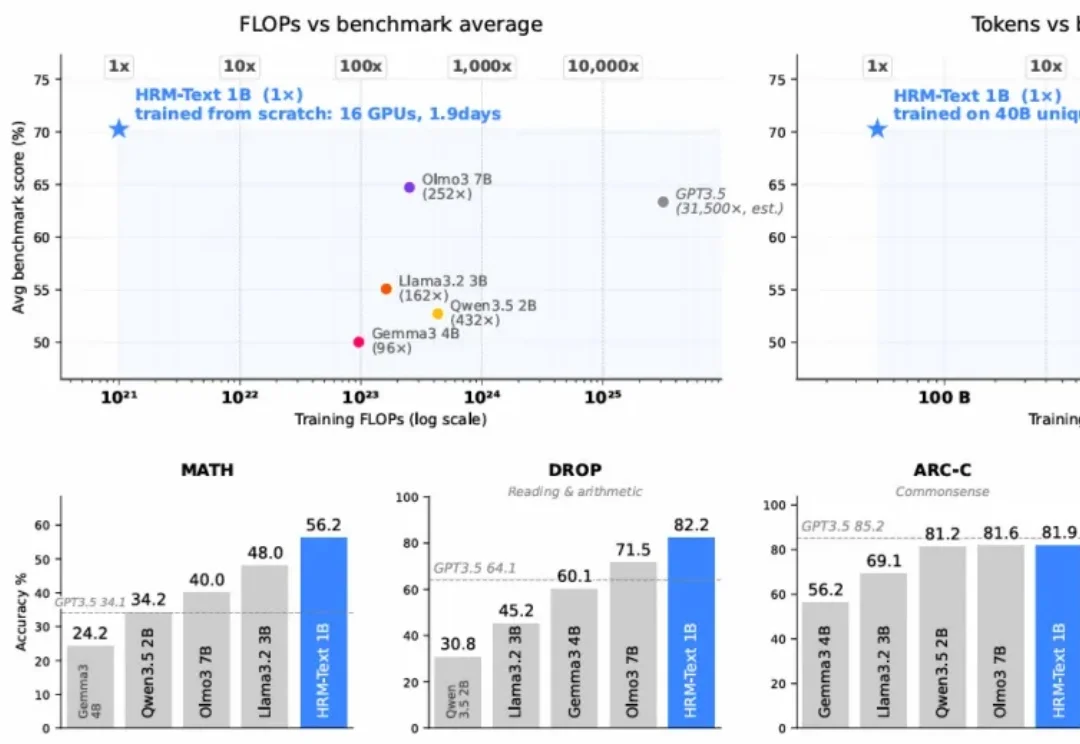
一个约 1B 参数的模型,在 MATH 上拿到 56.2,在 GSM8K 上拿到 84.5,在 ARC-Challenge 上拿到 81.9。训练成本约 1500 美元,16 块 H100 跑了不到两天。

近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。

智东西6月3日报道,宣布和英伟达合作后,Nous Research在昨日晚间,终于放出了他们开发的Hermes桌面版(预览)。在此之前,Hermes用户一直窝在终端里跑命令,有人转投民间开发者做的Web UI和桌面版,有人干脆不折腾,直接连飞书在上面养马,这次官方突然发布桌面版,很多人第一反应就四个字:早该有了。