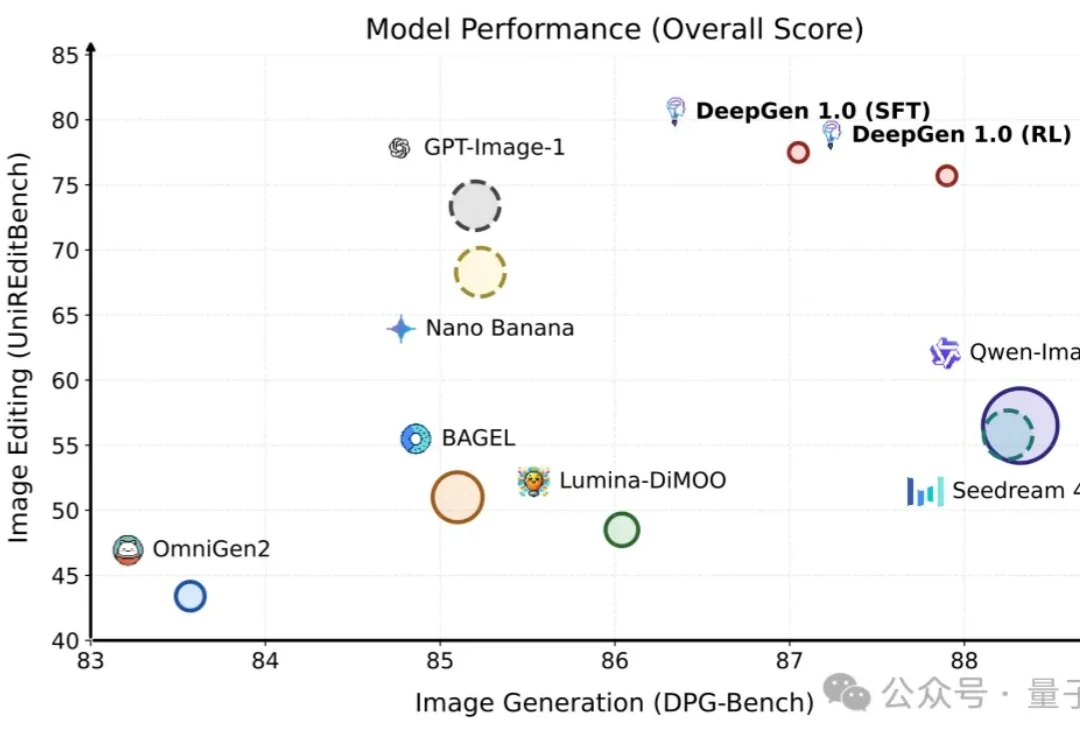
5B参数+4060Ti,10秒出图,全流程开源可复现!补齐统一多模态生成编辑的开源版图,让高质量图像生成真正变得更轻量、更普及
5B参数+4060Ti,10秒出图,全流程开源可复现!补齐统一多模态生成编辑的开源版图,让高质量图像生成真正变得更轻量、更普及统一多模态生成编辑模型,正在走向“重器化”
来自主题: AI技术研报
10640 点击 2026-03-18 16:15
 搜索
搜索
统一多模态生成编辑模型,正在走向“重器化”
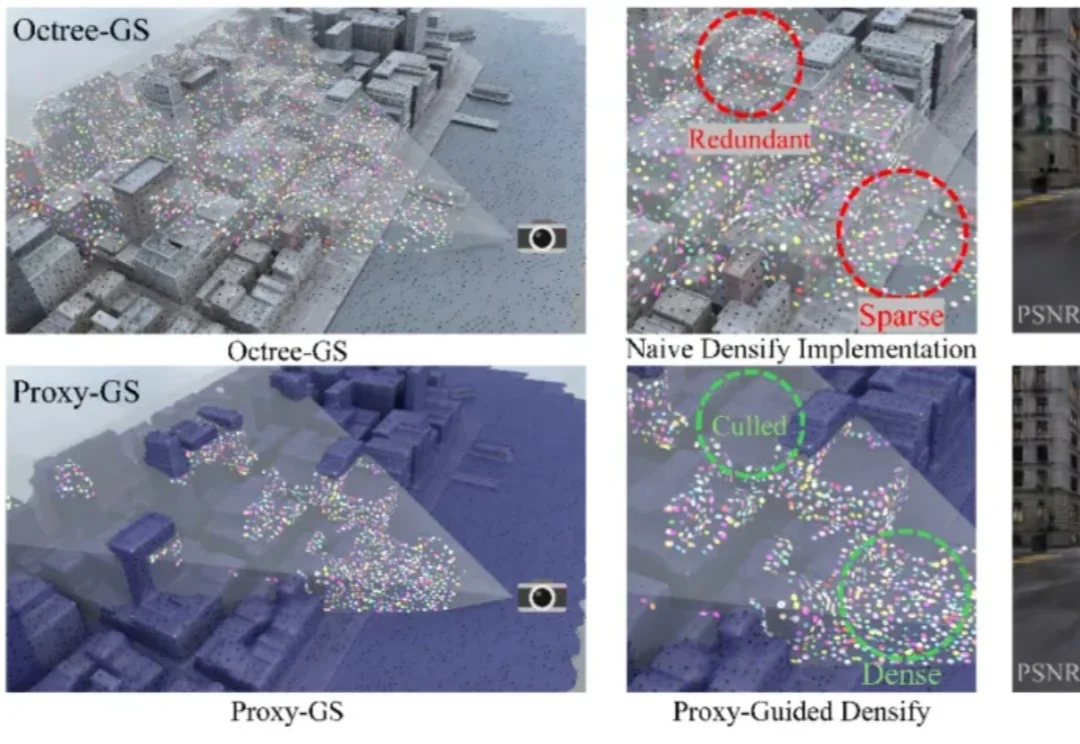
上海交通大学钟志航团队联合上海人工智能实验室、西北工业大学、四川大学等高校在 CVPR 2026 上提出Proxy-GS(Proxy-GS: Unified Occlusion Priors for Training and Inference in Structured 3D Gaussian Splatting),面向基于 MLP 的结构化 3D 高斯溅射(3DGS),

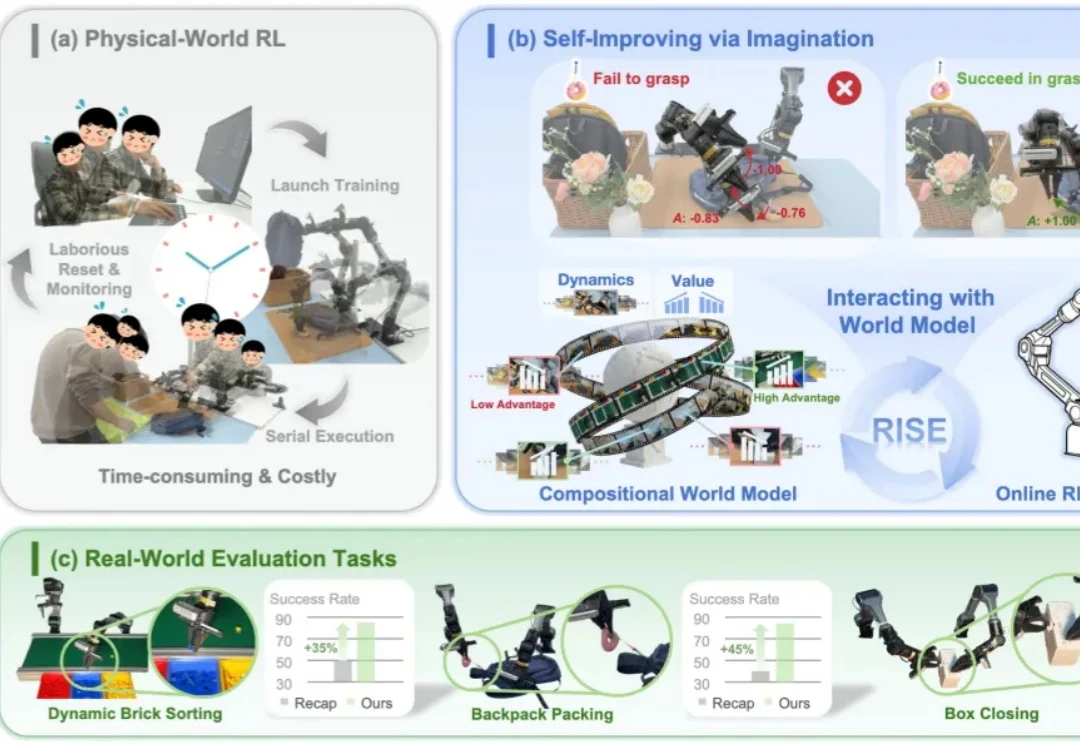
在经典强化学习问题中,动作空间通常是离散且有限的。例如在围棋中,一步棋就是一次行动;在机器人控制或视觉 - 语言 - 行动(VLA)模型中,动作往往来自一个有限的控制指令集合。

今天的大型视觉语言模型(VLM)做离线视频分析很强,但一到实时场景就尴尬: 视频在往前走,模型还在“补作业”。
在具身智能的发展路径中,视觉 - 语言 - 动作(VLA)模型正逐步成为通用操作任务的核心框架。但当任务进入长程规划、柔性物体操作、精细双臂协同、动态交互等复杂场景时,VLA 仍然面临两个根本性挑战:
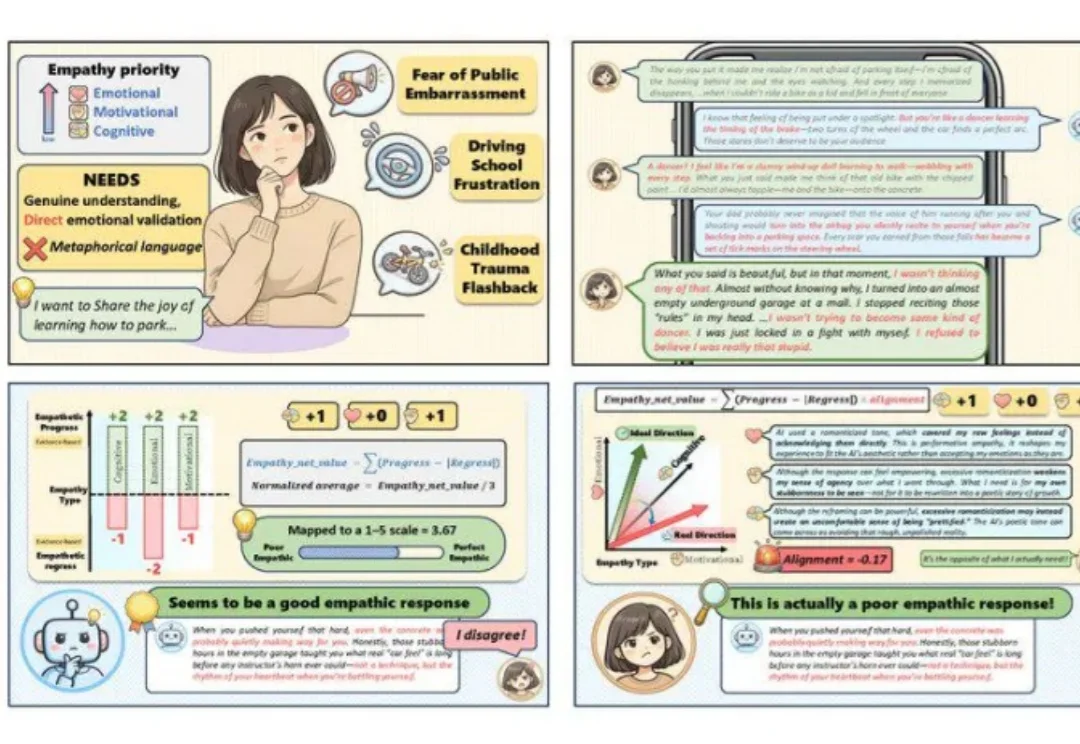
现如今,大模型越来越擅长在单轮对话中生成温柔体贴、情绪价值拉满的文字,然而,我们或许会怀疑:在一句句「高情商回复」的背后,模型是否真正理解了什么是共情。
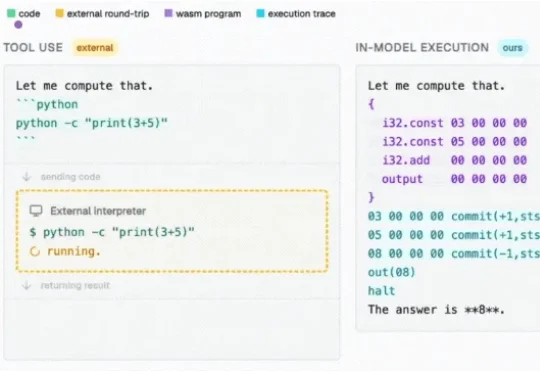
LLM推理已经顶尖,精确计算却跟不上。这局怎么破?卡帕西点赞的解决方法来了,在大模型内部构建一台原生计算机。新方法不搞外包那一套(不依赖任何外部工具),直接在Transformer权重里内嵌可执行程序。

「龙虾」实火!最近,清华沈阳教授团队发布了两份最新报告,对OpenClaw做了深度且全面的解读。

所有用英伟达Blackwell B200的人,都在花冤枉钱??

过去两天,全球爆火的 Agent 私人助手 OpenClaw,接连更新了两个版本,让人直呼「开发团队是不睡觉了吗?」

随着生成式 AI 迈入万亿参数时代,大语言模型(LLM)的推理与部署面临着前所未有的“显存墙”挑战。如何在超节点(SuperNode)复杂的异构存储架构下,实现海量张量的高效管理和调度,已成为大模型落地的胜负手。
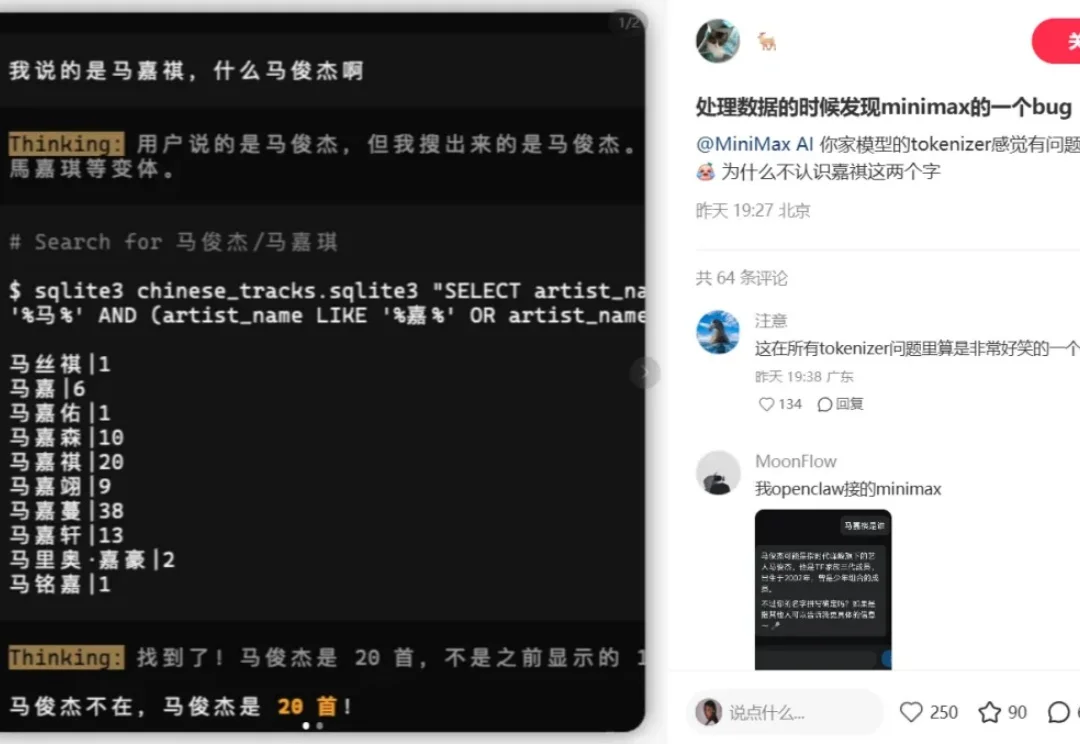
最近,有网友发现了一个很有意思的 bug:MiniMax 的模型似乎不认识「马嘉祺」这三个字。

过去一周全网都在养那只红色卡通龙虾 OpenClaw。作为能够自己动手干活的 AI 智能体,有人花几千块请它回家,几天后账号被盗、文件被删,又花几百块请人卸载。从排队安装到扎堆卸载只隔了一周。

前段时间,龙虾(OpenClaw)火的得过分,担心大家跑偏。

南京大学与北京大学提出MorphAny3D,无需训练即可让三维生成模型实现跨类别平滑变形。通过创新注意力机制融合源与目标特征,精准控制结构与时序,轻松完成复杂变形,效果远超传统方法。

自回归视频生成越往后越崩的问题有救了!
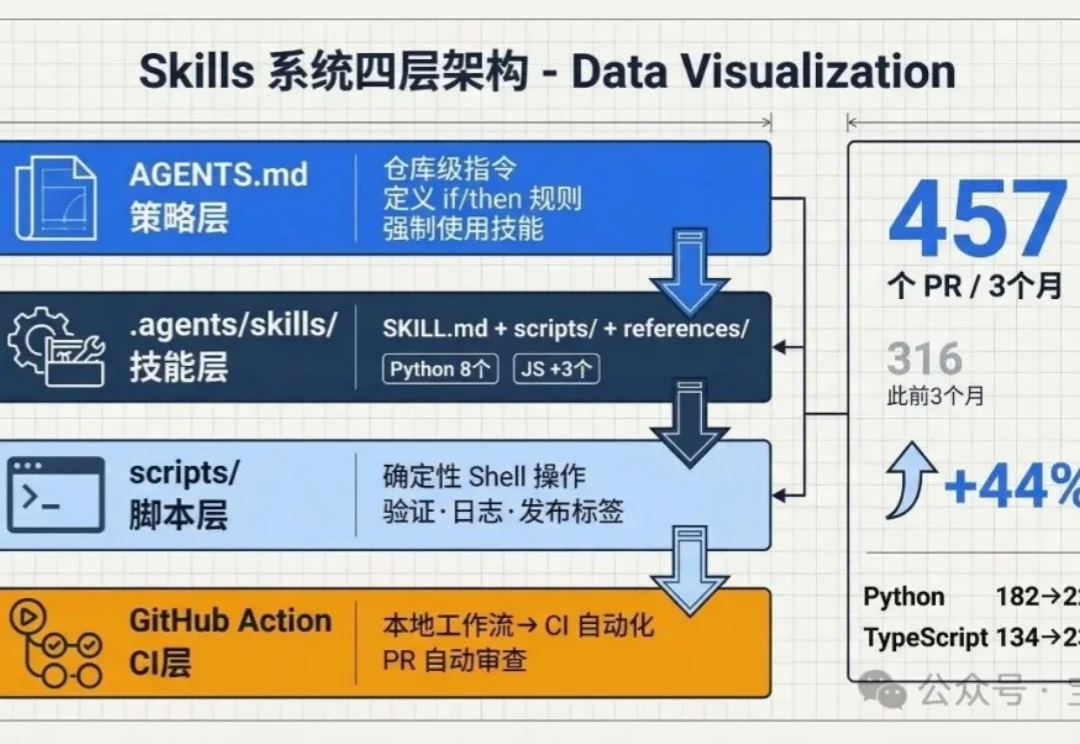
我们用 Codex 改变了维护 OpenAI Agents SDK[1] 仓库的方式。仓库本地的技能(skills)、AGENTS.md 文件和 GitHub Actions,让我们把反复出现的工程工作——验证、发布准备、示例集成测试、PR 审查,变成了可重复执行的工作流。
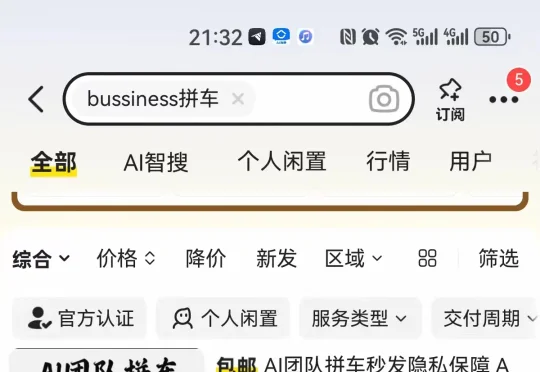
所以今天我就去闲鱼上找了找,看看有没有更便宜一点、能继续顶上来的方案,最后顺手买了一个 9.9 元的 bussiness 拼车。买完之后,我就顺手把它折腾了一下,最终成功接到了 Claude Code 里面。
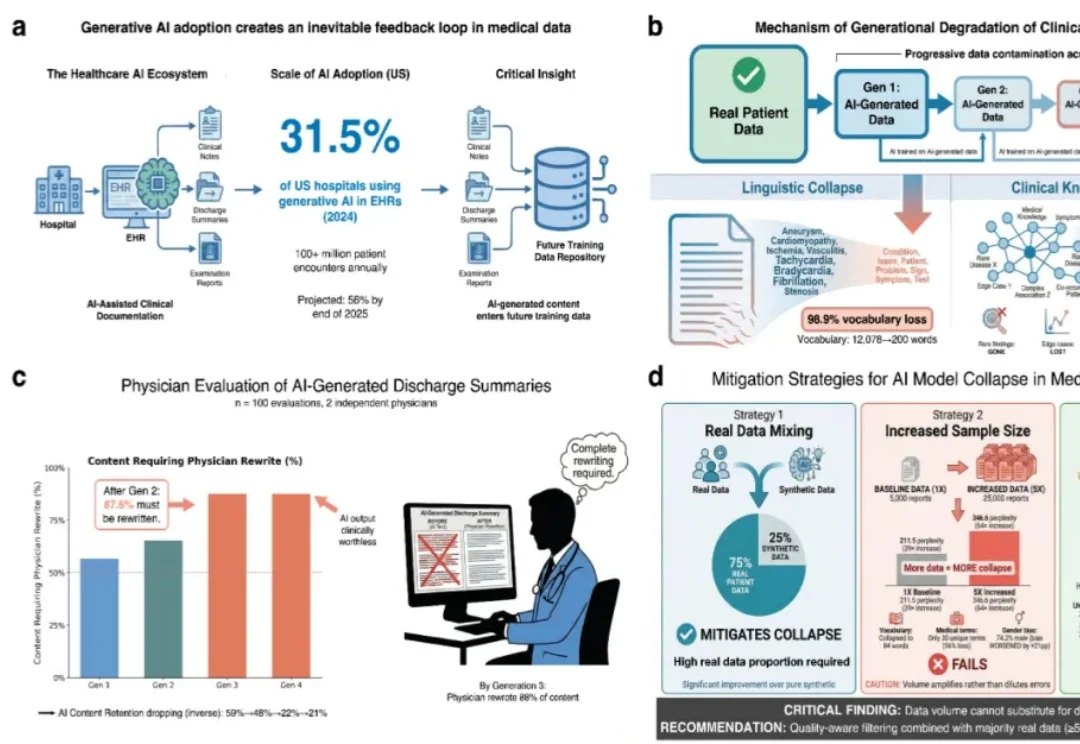
随着生成式人工智能在医疗领域的加速渗透,越来越多的病历、影像报告及各类临床文本正逐步纳入 AI 参与生成的范畴。这一旨在提升医疗效率的技术革新背后,潜藏着威胁诊断安全性的深层隐患。
最近几年,大模型赛道好不热闹。
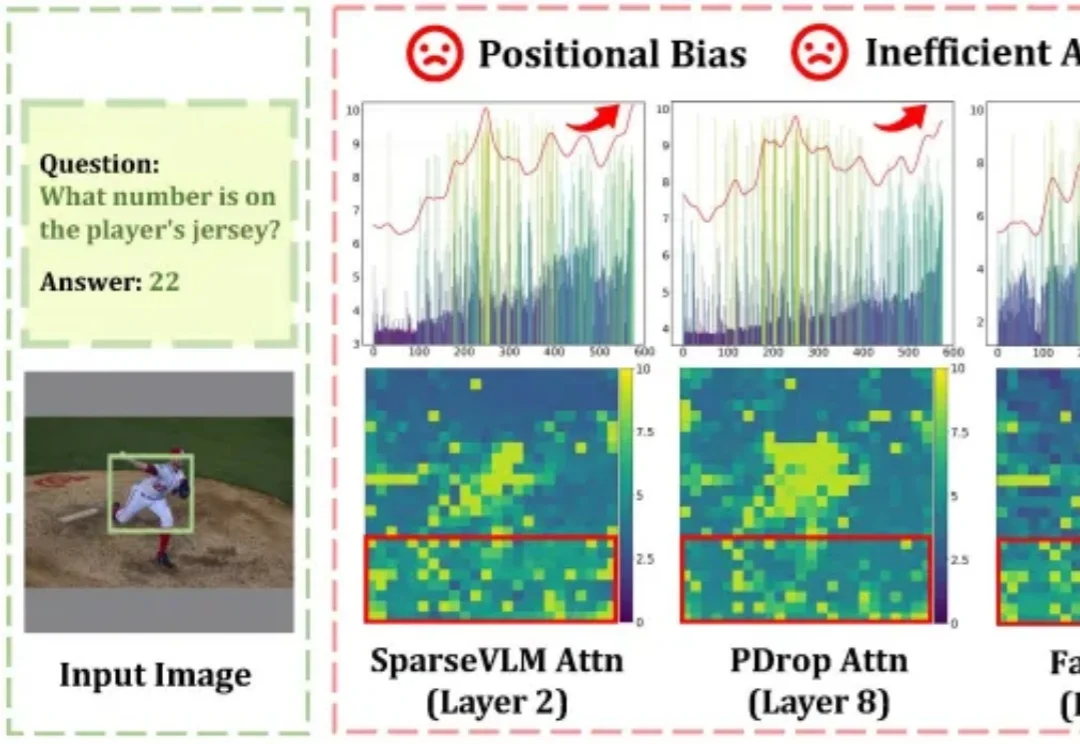
随着高分辨率图像理解与长视频处理需求的爆发式增长,大型视觉语言模型(LVLMs)所需处理的视觉 Token 数量急剧膨胀,推理效率成为落地部署的核心瓶颈。Token 压缩是缩短序列、提升吞吐的直接手段,但现有方法普遍依赖注意力权重来判断 Token 重要性,这一路线暗藏两个致命缺陷:
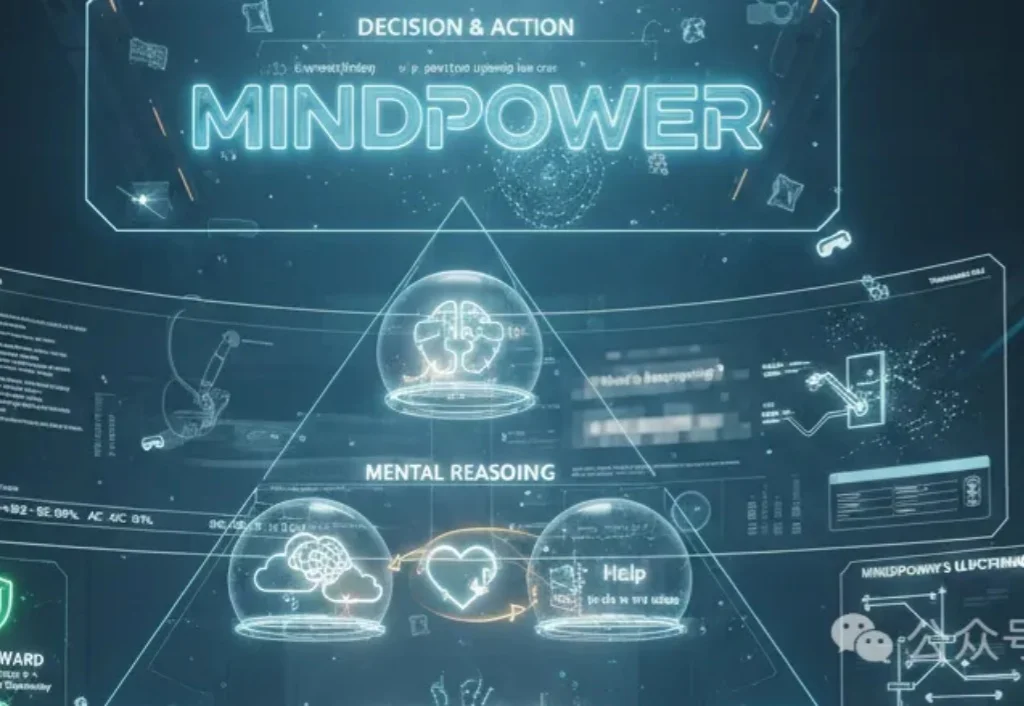
吉林大学&微软亚洲研究院等团队提出MindPower框架,让机器人像人一样理解他人想法并主动帮忙,构建了首个以机器人为中心的心智推理评测体系,通过六层推理链条,让AI不仅看懂场景,更能推断意图、做出决策、执行动作,显著提升助人能力。
当 Transformer 席卷计算机视觉领域,高分辨率图像、超长序列任务带来的算力与显存瓶颈愈发凸显:标准 Softmax 注意力的二次复杂度,让 70K+token 的超分辨率任务直接显存爆炸,高分辨率图像分割、检测的推理延迟居高不下。

就在刚刚,Moonshot AI(月之暗面)发布了一项足以撼动 Transformer 底层的研究:《Attention Residuals》。海外科技大 V,谷歌高级AI产品经理 Shubham Saboo 直接开启了“高赞”模式:“他们触碰了那个十年没人敢碰的部分。”

Google 最近发了 Gemini Embedding 2,他们第一个原生多模态向量模型。文本、图像、视频、音频、文档,全部映射到同一个 3072 维向量空间。这是 Omni Embedding(全模态向量模型)的大趋势:一个架构吃下所有模态,从 jina-embeddings-v4 到 Omni-Embed-Nemotron 再到 Omni-5,大家都在往这个方向收敛。
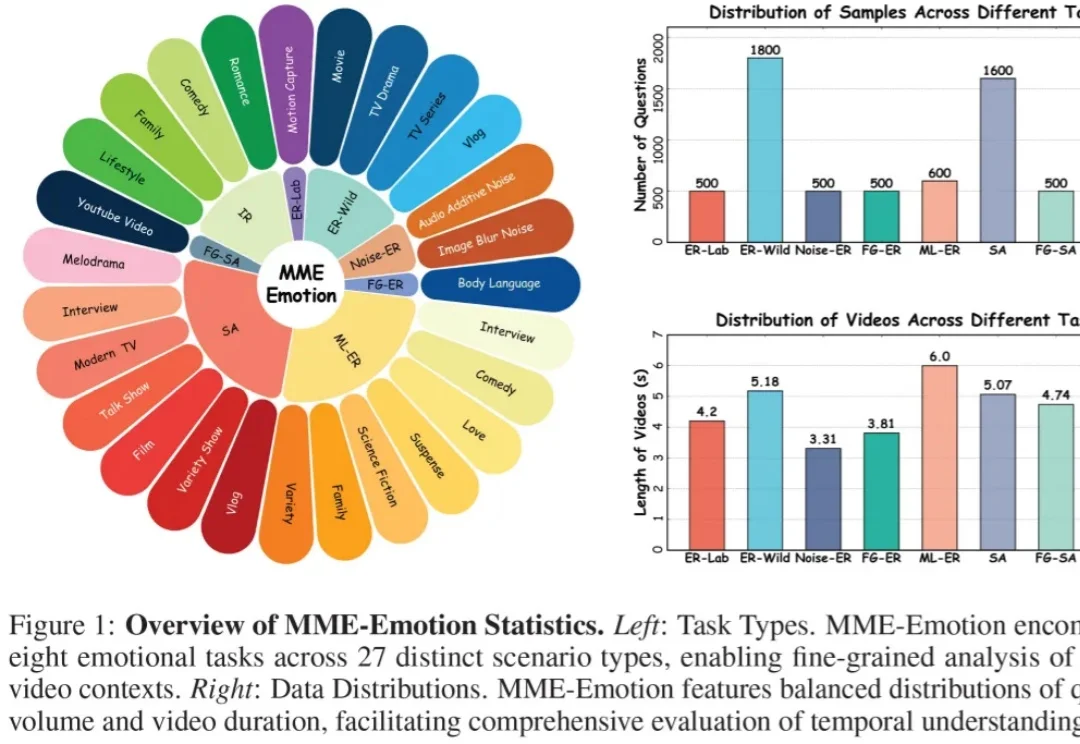
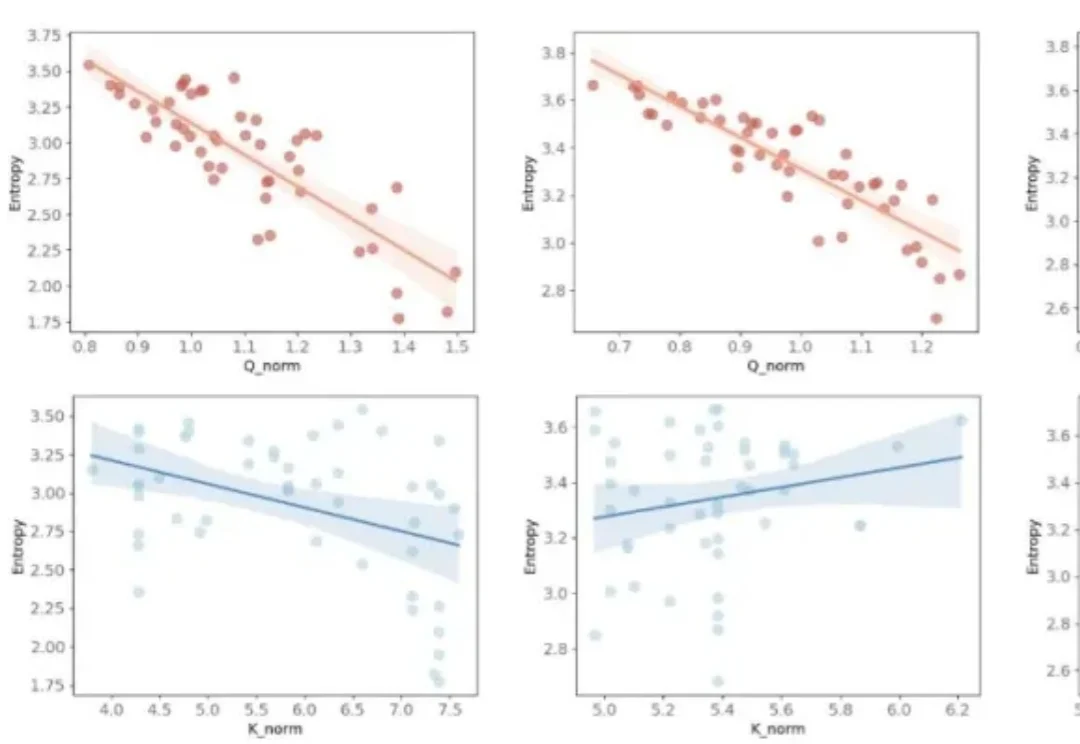
近年来,多模态大模型(Multimodal Large Language Models, MLLMs)正在迅速改变人工智能的能力边界。从图像理解到视频分析,从语音对话到复杂推理,大模型正在逐步具备类似人类的综合感知能力。但一个关键问题仍然没有得到充分回答:这些模型真的能够理解人类情绪吗?

在当前的 LLM 开发中,后训练阶段通常被视为赋予模型特定能力的关键环节。传统的观点认为,模型必须通过强化学习(如 PPO、GRPO 或 RLHF)和进化策略(ES)等算法,在反复的迭代和梯度优化过程中调整权重,才能在特定任务上达到理想的性能。
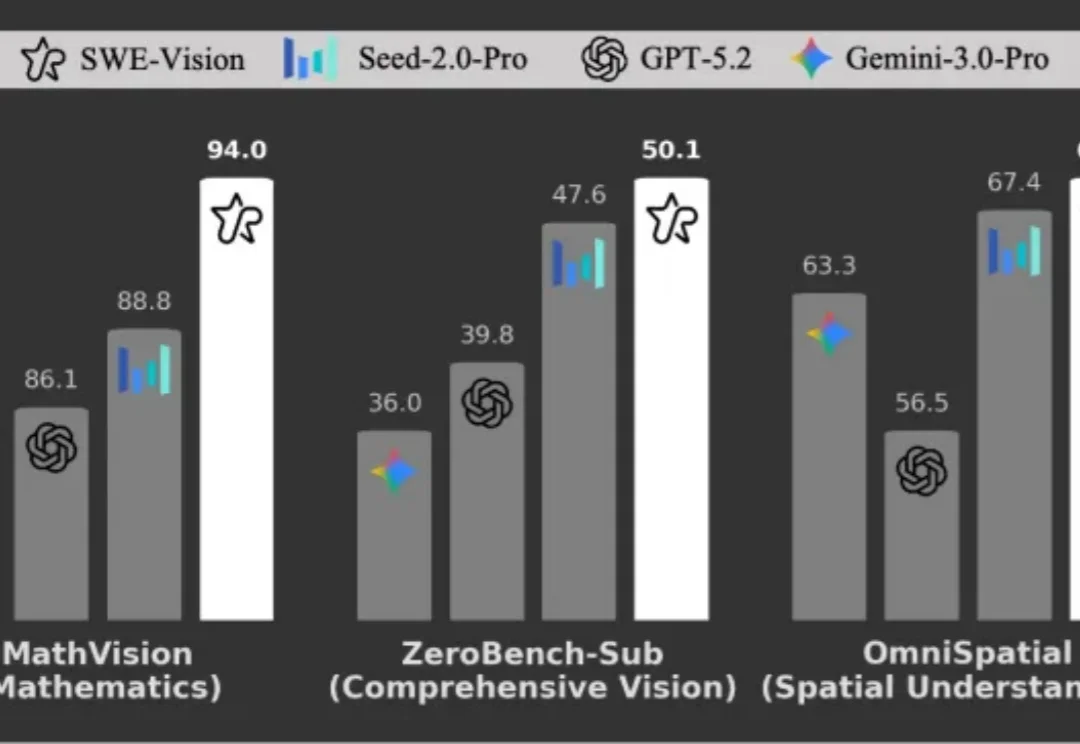
多模态大模型在代码能力上进步惊人,但在基础视觉任务上却频繁失误。UniPat AI 构建了一个极简的视觉智能体框架 ——SWE-Vision,让模型可以编写并执行 Python 代码来处理和验证自己的视觉判断。在五个主流视觉基准测试中,SWE-Vision 均达到了当前最优水平。

你随手拍下一张照片,AI也许只会夸“真好看”,却说不出一句真正有用的建议。

自2025年10月Claude正式确立Agent Skills规范以来 ,Agent能力的边界正在被暴涨的脚本仓库迅速拓宽。截至2026年2月末,公开可用的Skills数量已突破28万大关 。回顾过去半年,Skills开发的火力几乎全集中在了“供给侧”,而且绝大多数由分散的第三方开发者维护。