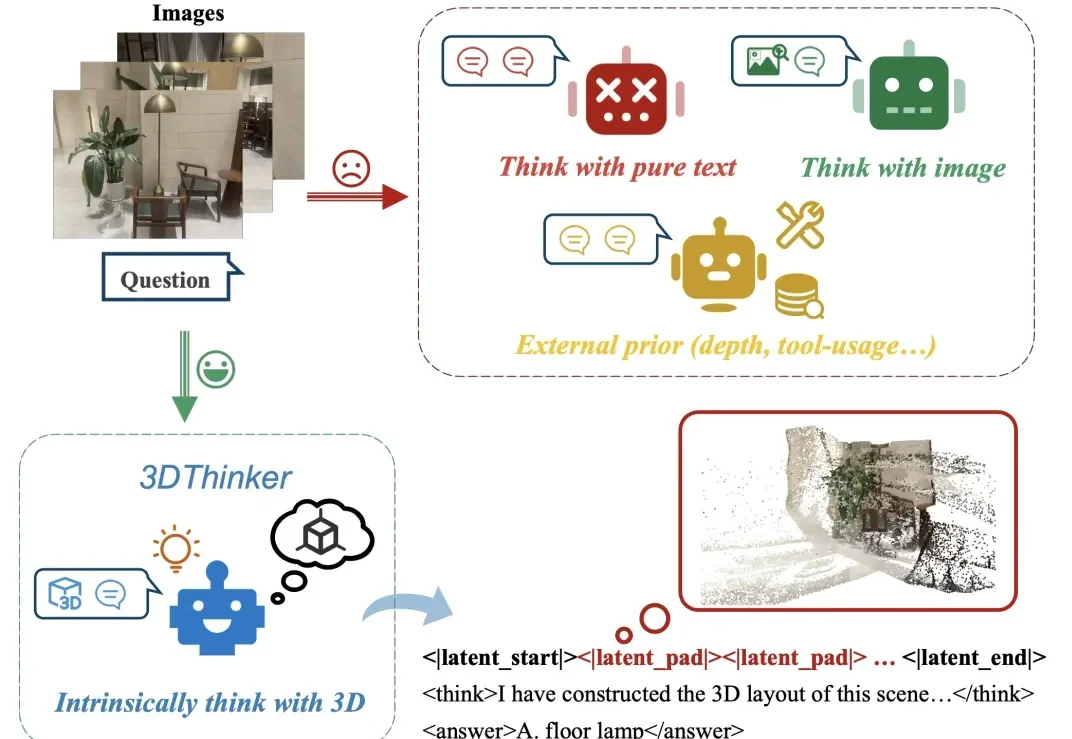
CVPR 2026|清华联合美团推出3DThinker,首个用3D意象思考的工作
CVPR 2026|清华联合美团推出3DThinker,首个用3D意象思考的工作大家是否有这样的感觉?给定几张场景中拍摄的图片,往往能够在脑海中想象出这个场景的三维布局,然而当前的多模态大模型还停留于纯文本或者 2D 视觉的推理表示,限制了图像中隐含几何结构的表达能力。
来自主题: AI技术研报
9525 点击 2026-03-11 09:25
 搜索
搜索
大家是否有这样的感觉?给定几张场景中拍摄的图片,往往能够在脑海中想象出这个场景的三维布局,然而当前的多模态大模型还停留于纯文本或者 2D 视觉的推理表示,限制了图像中隐含几何结构的表达能力。

扩散模型终于学会“看题下菜碟”了!

用强化学习微调扩散模型,还有更好的办法吗?

NUS、ZJU、UW、Stanford、CUHK 联合提出 「ThinkMorph」,主张让文字与图像在统一架构里「原生协作」、「共同演化」,而不是像当下大多数多模态模型那样,看完图像就闭上眼睛,后续完全靠文字链条推进。仅用 2.4 万条数据微调 7B 统一模型,视觉推理平均提升 34.74%,多项任务比肩甚至超越 GPT-4o 和 Gemini 2.5 Flash。
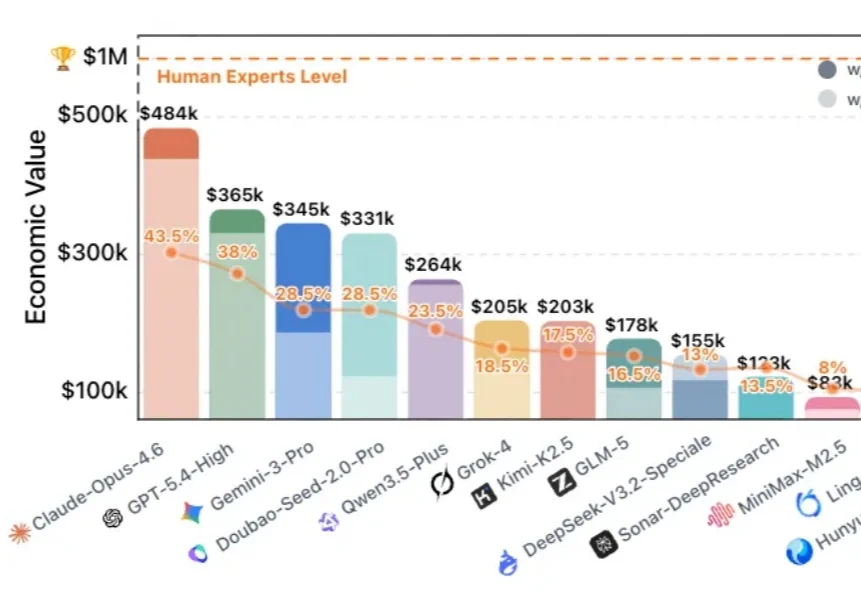
如果有价值 $100 万美金的顶级专家任务,AI 能完成其中多少?
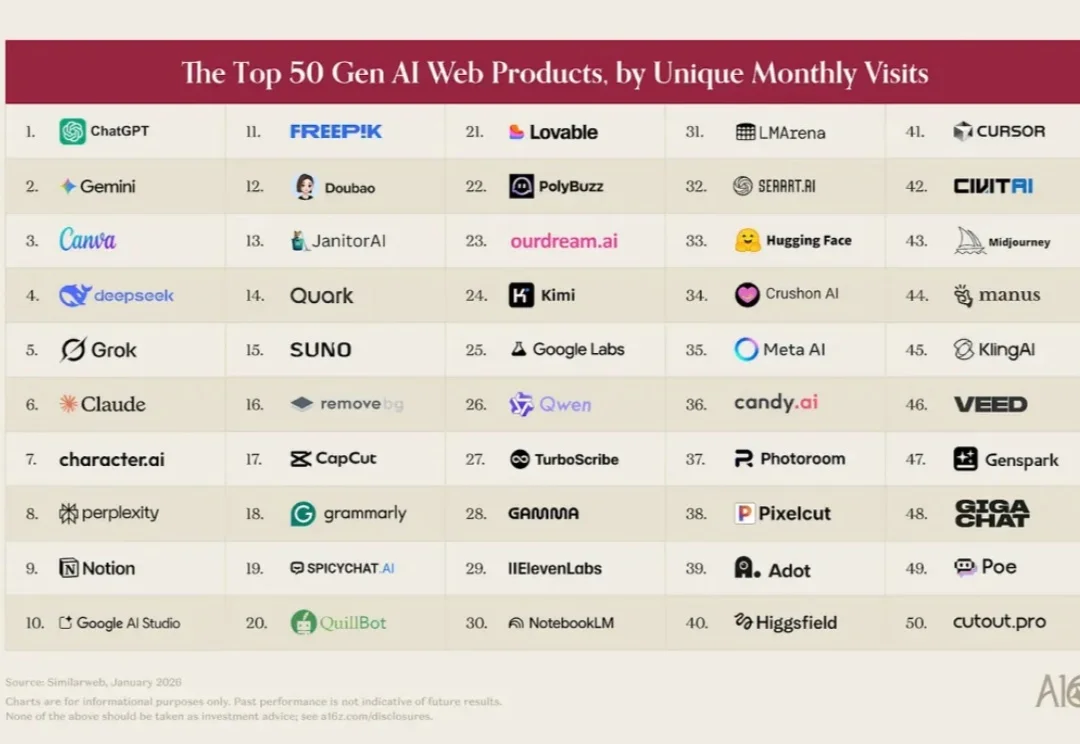
三年前,我们发布了这份榜单的第一版,目标很简单:找出哪些生成式 AI 产品真正被主流消费者使用。在当时,「AI 原生」公司和其他公司之间的界限很清晰。ChatGPT、Midjourney 和 Character.AI 都是围绕基础模型从零构建的产品,而软件行业的其他玩家还在摸索这项技术该怎么用。

DragStream,首次实现视频生成时的实时拖拽编辑。用户可随时拖动画面中的物体,自由平移、旋转或变形,系统自动保持后续帧连贯自然,无需重训模型,无缝适配主流AI视频生成器,真正实现「所见即所得」。

视频生成进入大规模时代,但计算成本也炸了。
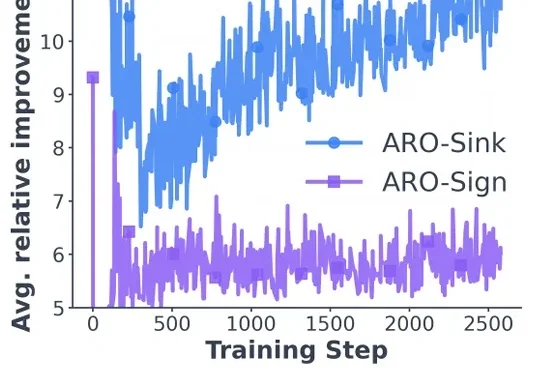
如果你在过去一年关注过大模型训练的技术,大概率听过 Muon 这个名字 —— 这个在月之暗面 K2 模型的相关讨论中走红的优化器,被视为是可能挑战 Adam 的新秀。它的思路很直接:对动量矩阵进行正交化,让各个奇异方向上的更新速率一致,提升训练效率。
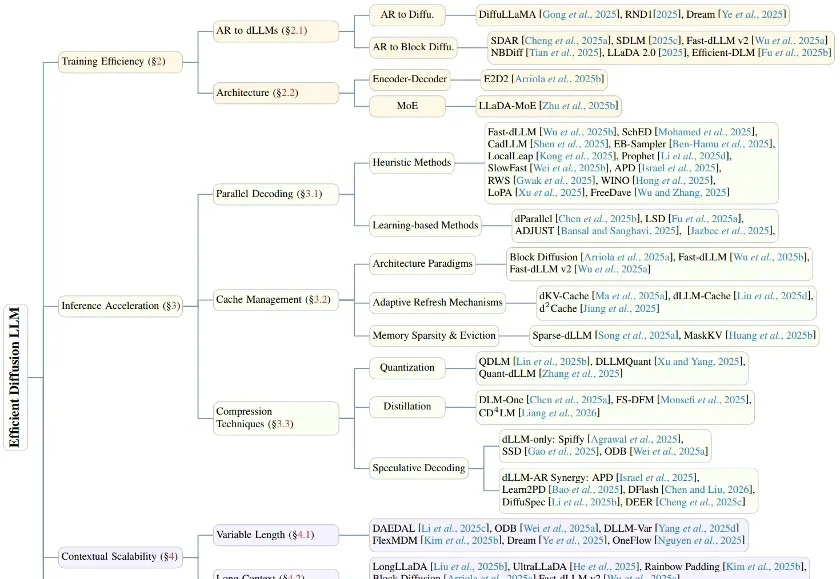
在生成式 AI 的浪潮中,自回归(Autoregressive, AR)模型凭借其卓越的性能占据了统治地位。然而,其「从左到右」逐个预测 Token 的串行机制,天生限制了并行生成的可能性。
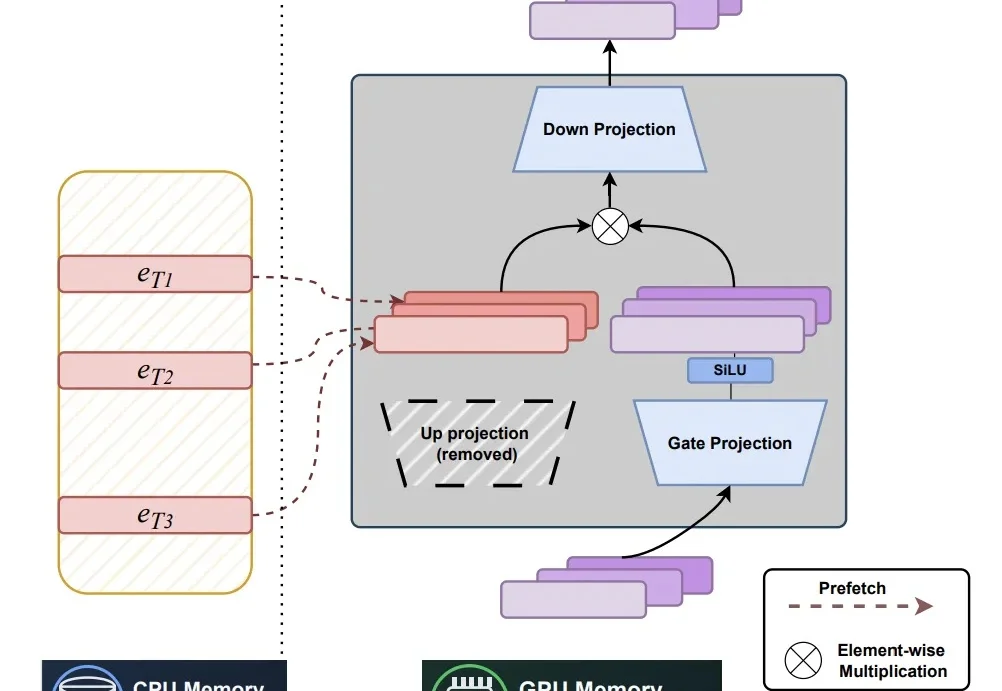
近年来,随着大语言模型规模与知识密度不断提升,研究者开始重新思考一个更本质的问题:模型中的参数应如何被组织,才能更高效地充当「记忆」。
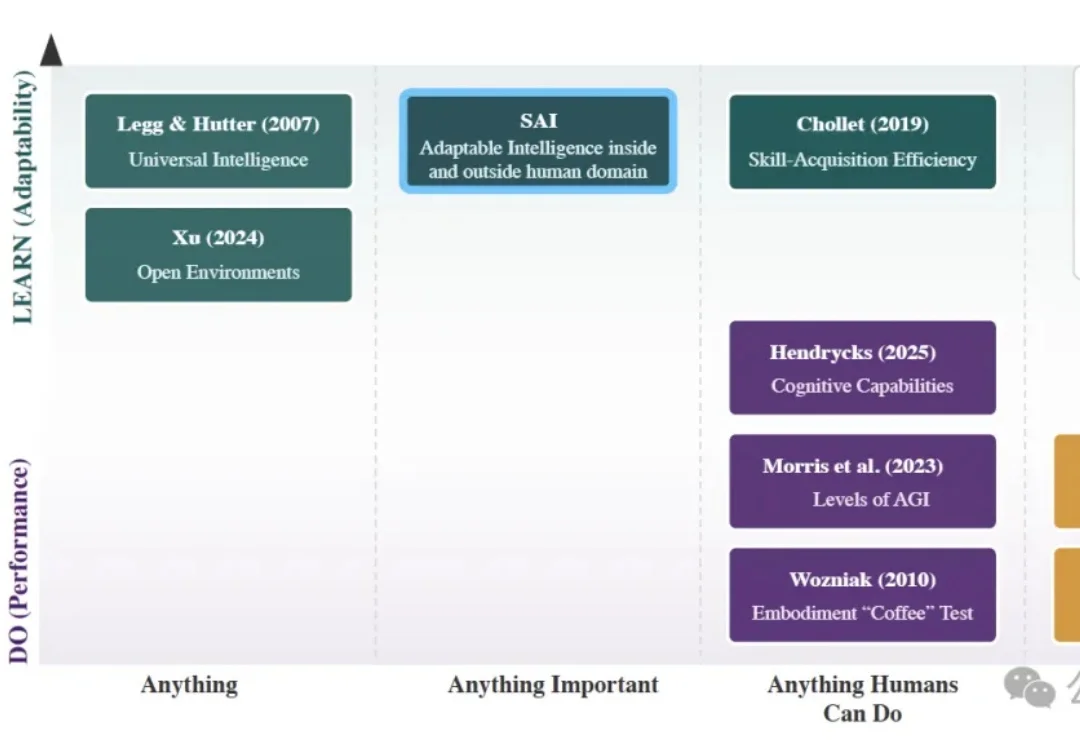
AI圈追逐多年的通用人工智能(AGI),可能从一开始就走偏了。

在 AI 视觉生成领域,扩散模型(DM)凭借其强大的高保真数据生成能力,已成为图像合成、视频生成等多模态任务的核心框架。然而,预训练后的扩散模型如何高效适配下游应用需求,一直是行业面临的关键挑战。

自扩散模型提出以来,它不仅在图像、视频和音频生成方面取得了优异效果,也正逐渐成为解决图像复原、超分辨率、去模糊等逆问题的重要工具。

大神Karpathy又开源了新项目——一个能够自主进化的AI科研循环系统。这个项目名叫autoresearch,主打让智能体完全自主地搞科研,只要在Markdown文档里写好指令,剩下的流程全都由AI自动完成。
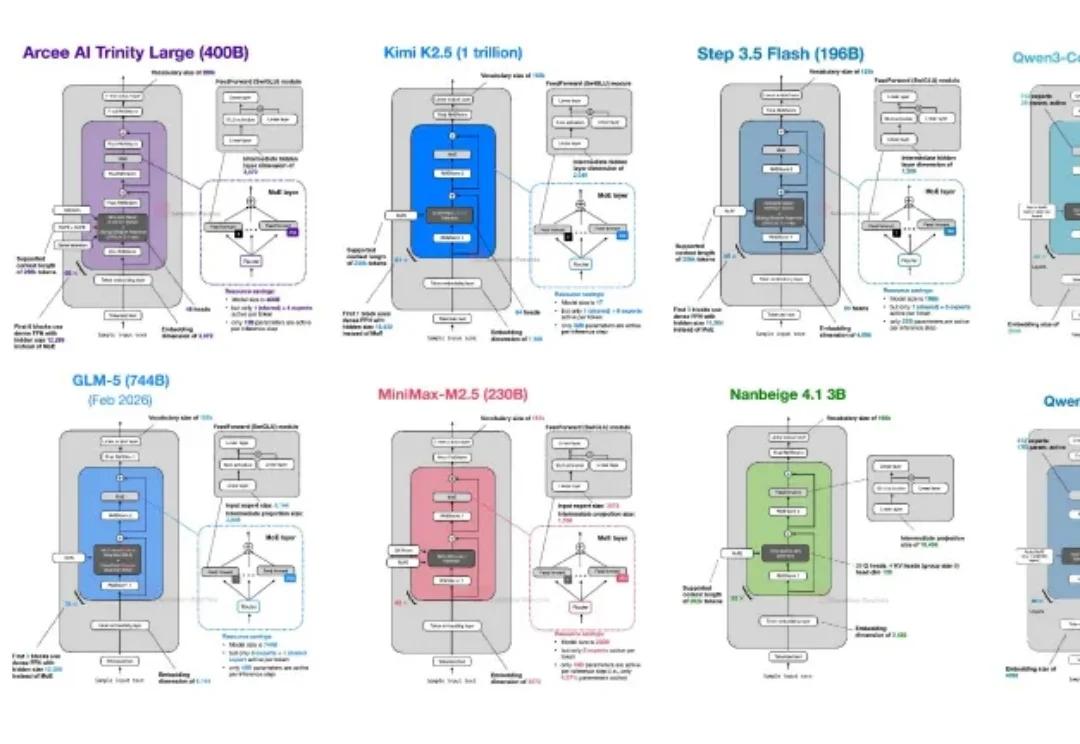
这两年,大模型大厂之间堪比军备竞赛。不论开源还是闭源阵营,为了在指标上领先对手,都在疯狂地卷 Scaling Law,卷算力,卷参数量,已经达到了近乎离谱的程度。

上面就是我最近日常的打字方式,在家、在公司、在咖啡厅都可以。
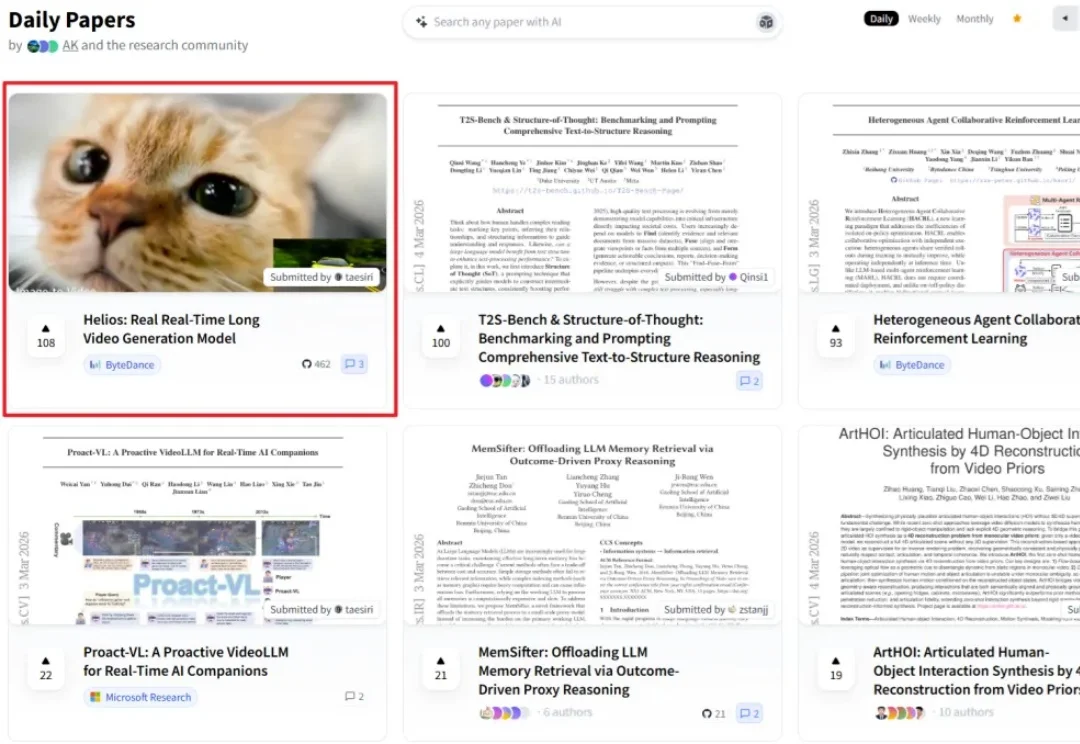
春节期间, Seedance 2.0 爆火,堪称现象级,这也再次把视频生成推上风口。前两天,字节跳动又携手北大、安努智能和 Canva 共同开源了具备实时生成能力的视频模型 Helios 家族。该系列包含了 Helios-Base、Helios-Mid 与 Helios-Distilled 三个版本,全面覆盖了 T2V、I2V、V2V 以及交互式生成任务。
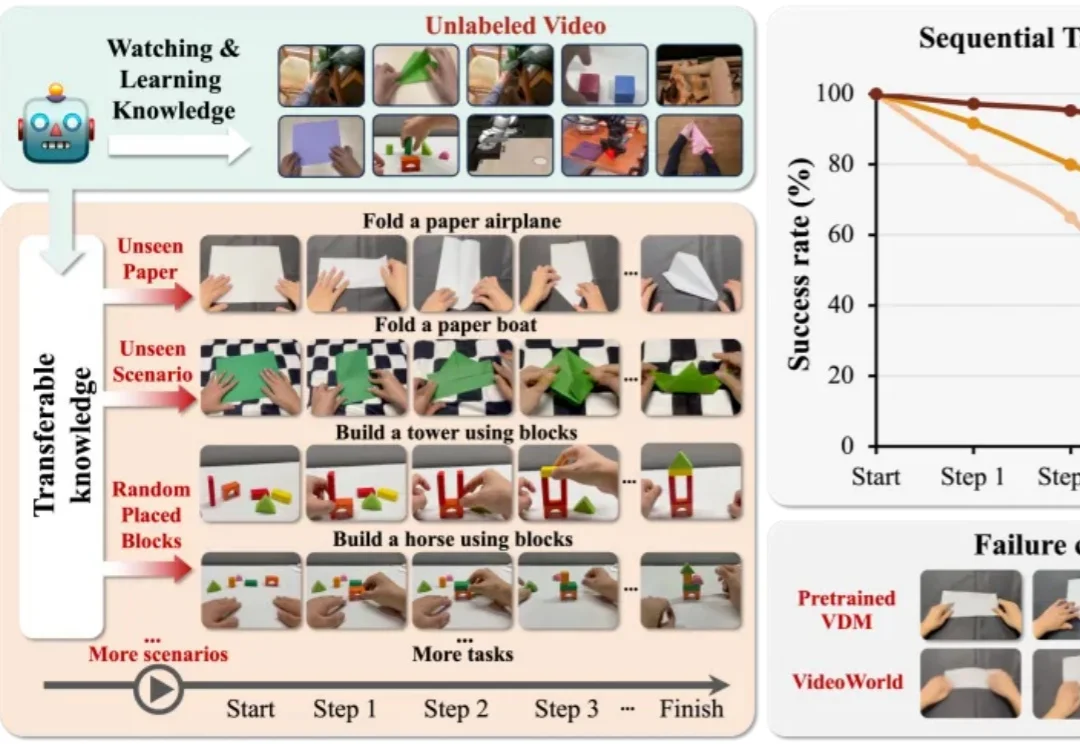
视觉世界模型 “VideoWorld 2” 由豆包大模型团队与北京交通大学联合提出。不同于 Sora 2 、Veo 3、Wan 2.2 等主流多模态模型,VideoWorld 系列工作在业界首次实现无需依赖语言模型,即可认知世界。

港科大团队提出音频生成统一模型AudioX,只需一个模型,就能从文本、视频、图像等任意模态生成高质量音效和音乐,在多项基准上超越专家模型。团队同时开源了700万样本的细粒度标注数据集IF-caps与可控T2A评测基准T2A-bench,并在该基准上大幅领先现有方法。论文已被ICLR 2026接收。
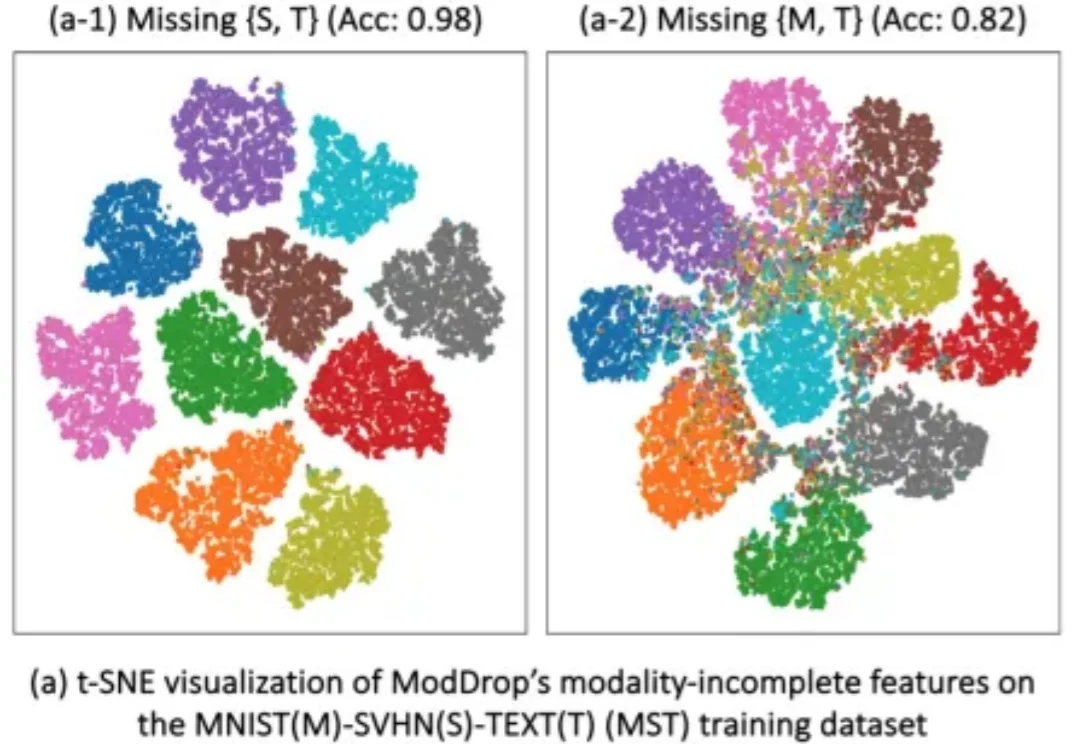
多模态学习(Multimodal Learning)正在推动 AI 在医学影像、自动驾驶、人机交互等领域取得突破。通过融合图像、文本、表格等多种模态,模型能够获得更全面的信息,从而显著提升性能。
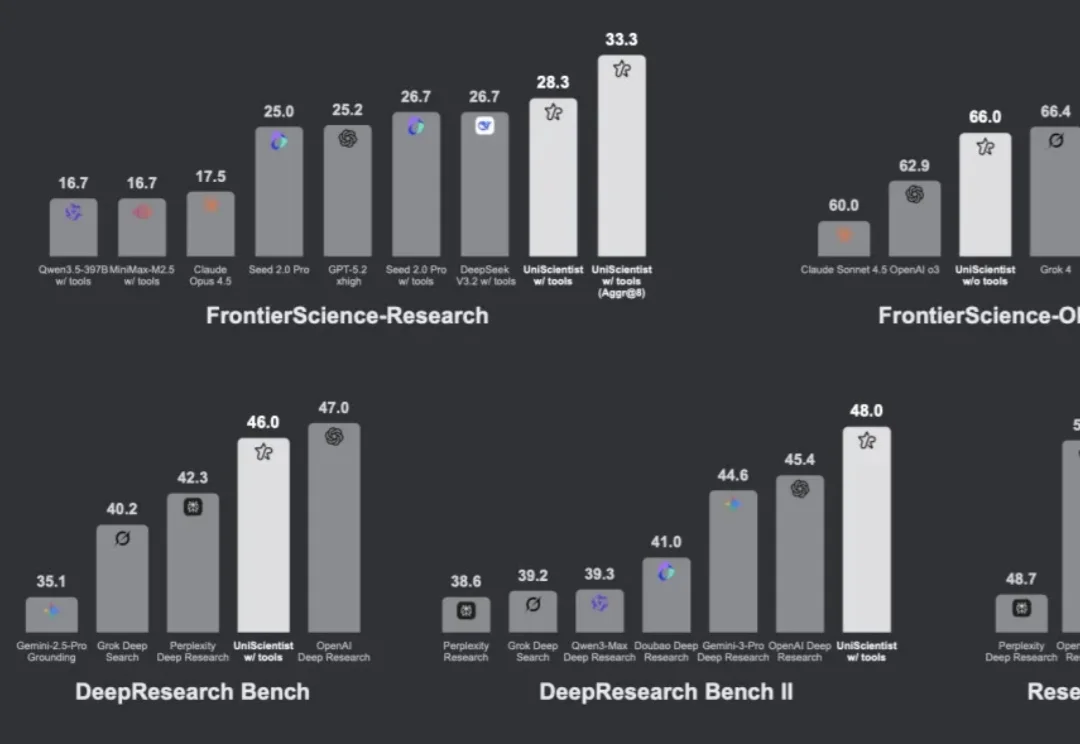
多数大模型能生成 “看起来像” 研究的文本,但极少数能真正做研究 —— 提出假设、收集证据、执行可复现的推导、迭代验证直至结论成立。

十亿参数的三维重建模型,能塞进手机吗?
OpenClaw 火爆的盛况至今仍在持续,在国内甚至出现了排队在腾讯总部楼下等待安装 OpenClaw 的场景,让人感叹「一代人有一代人的领鸡蛋」。

基础模型时代,大模型能力的爆发,很大程度上源于在海量文本上的预训练。然而问题在于,文本本质上只是人类对现实世界的一种抽象表达,是对真实世界信息的有损压缩。
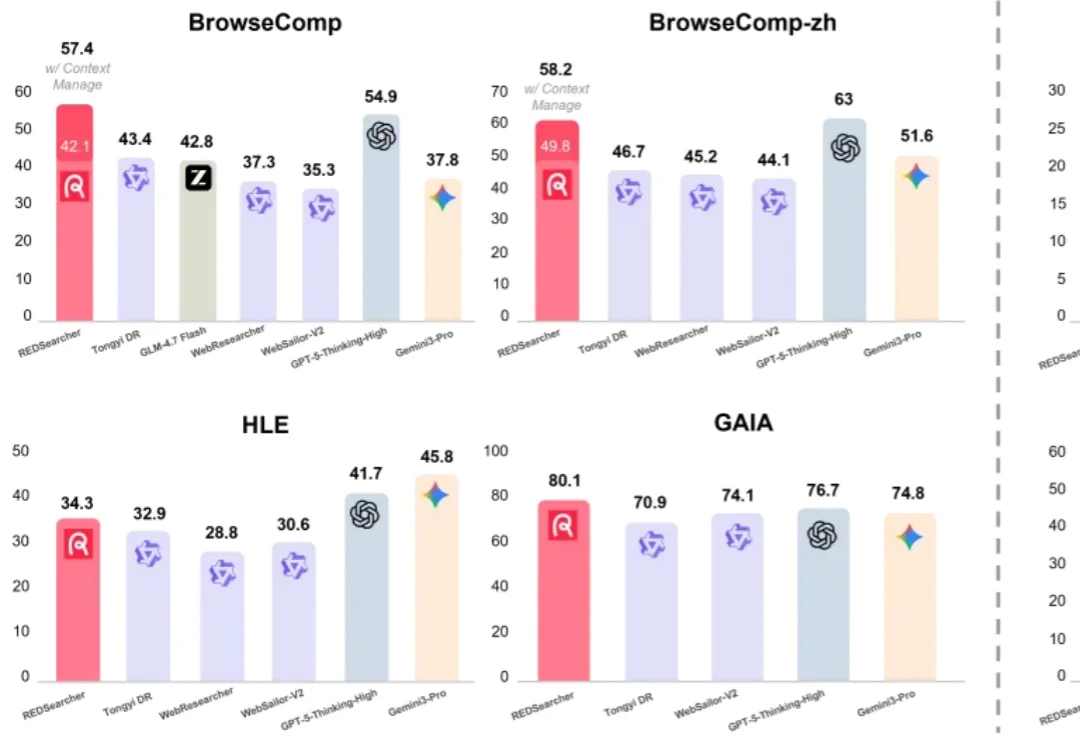
「2018 到 2023 年间在 EMNLP 会议上发表的那篇论文中,第一作者本科就读于达特茅斯学院、第四作者本科就读于宾夕法尼亚大学的那篇科学论文,题目是什么?」
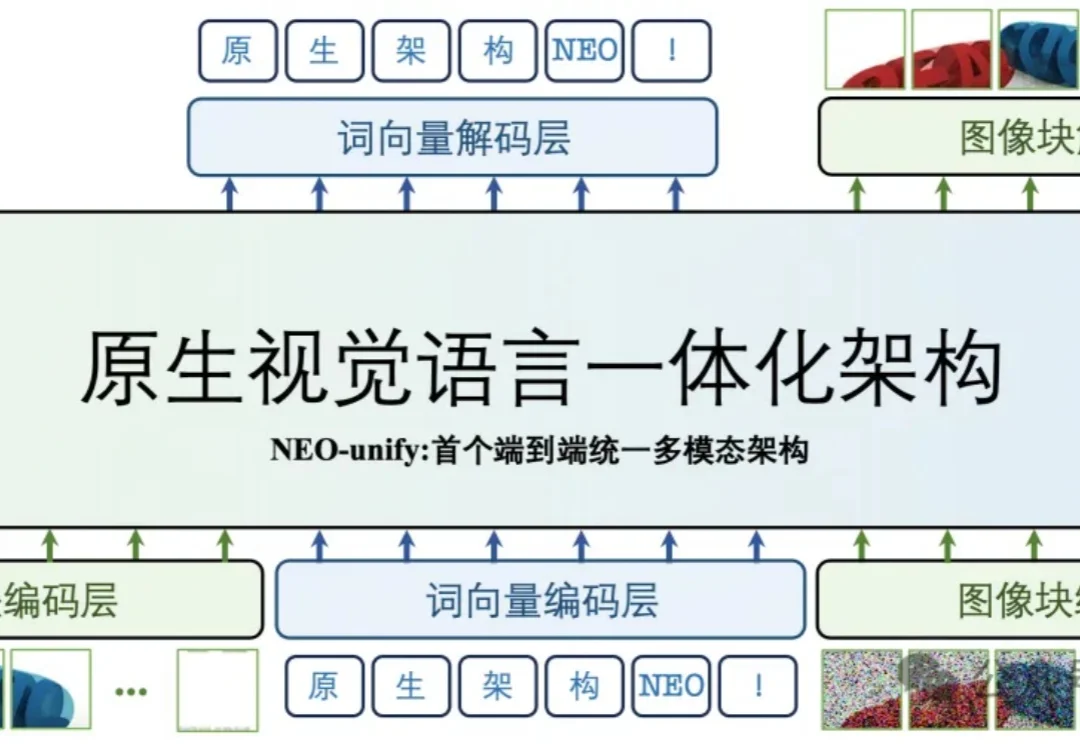
多模态大模型的研发范式,正在被彻底重构。
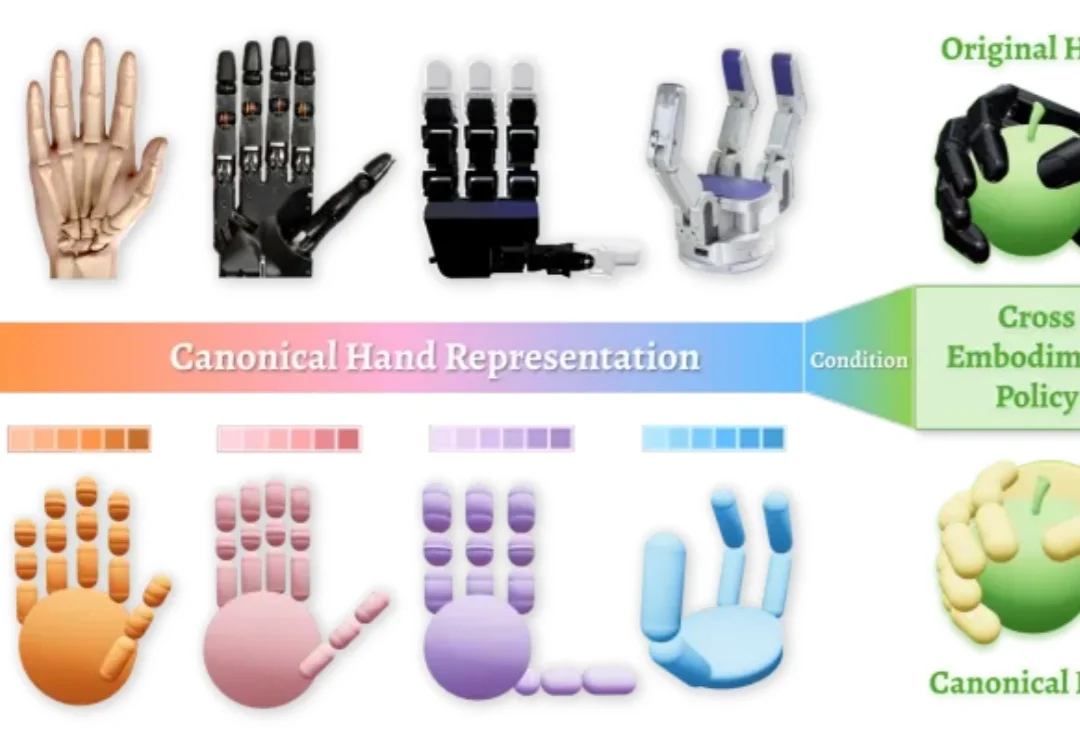
在机器人操作领域,一个长期悬而未决的核心问题始终困扰着研究者: 面对形态各异的灵巧手,我们是否注定要为每一种手型单独设计表示方式与控制策略?
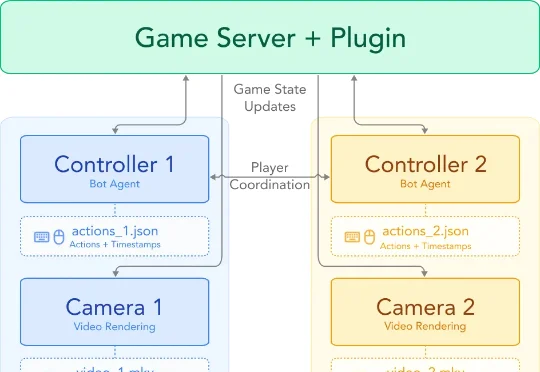
谢赛宁团队的最新视频世界模型 Solaris,首个多人视频世界模型,能够同时生成多个玩家之间保持一致的第一视角。研究团队发现,目前的视频世界模型仅能处理单人视角,这并不能反映现实世界的真实运作方式,希望能够能够实现多人同步观察一个统一世界。于是,研究团队把视角投向了电子游戏。
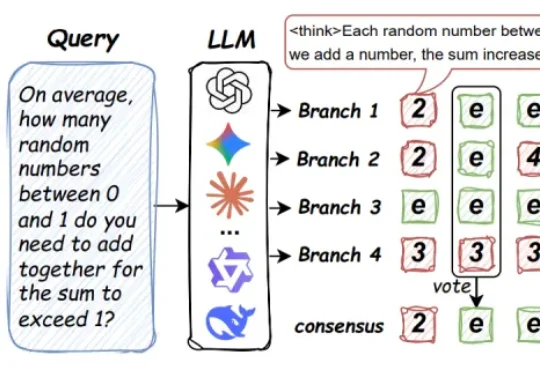
来自马里兰大学、圣路易斯华盛顿大学、北卡罗来纳大学教堂山分校等机构的研究团队提出了 Parallel-Probe。不同于直接从算法设计出发,该研究首先通过引入 2D Probing,对 online 并行推理过程中的全局动态性进行了系统性刻画。