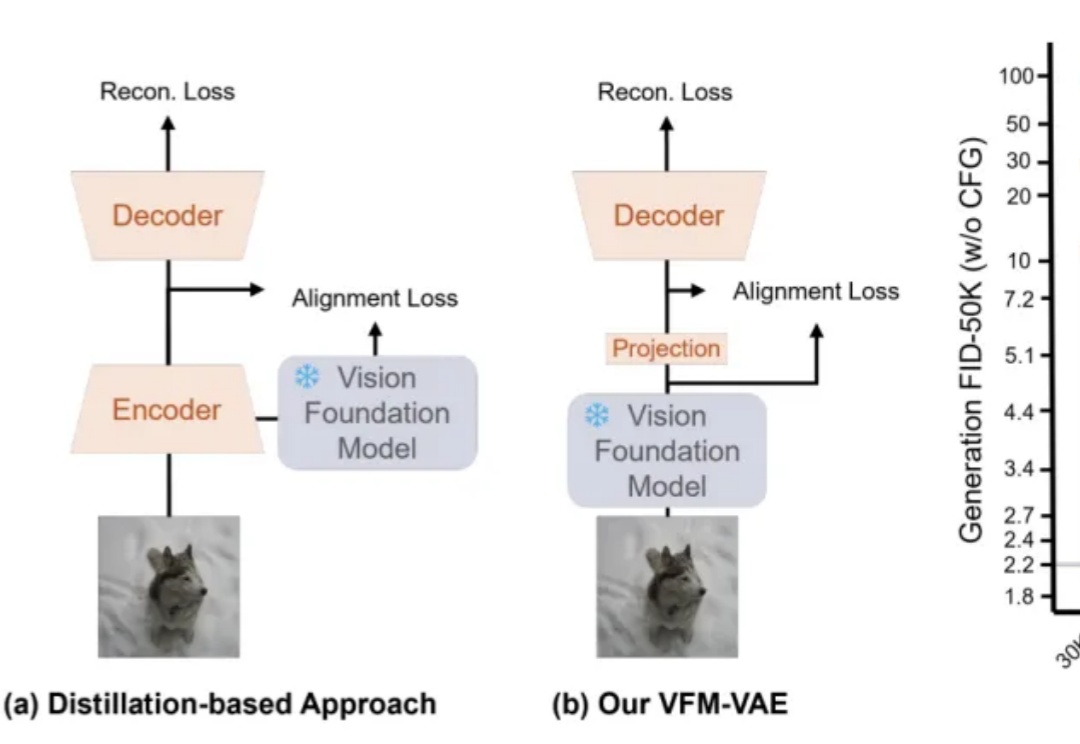
RAE+VAE? 预训练表征助力扩散模型Tokenizer,加速像素压缩到语义提取
RAE+VAE? 预训练表征助力扩散模型Tokenizer,加速像素压缩到语义提取近期,RAE(Diffusion Transformers with Representation Autoencoders)提出以「 冻结的预训练视觉表征」直接作为潜空间,以显著提升扩散模型的生成性能。
来自主题: AI技术研报
12195 点击 2025-11-14 10:21
 搜索
搜索
近期,RAE(Diffusion Transformers with Representation Autoencoders)提出以「 冻结的预训练视觉表征」直接作为潜空间,以显著提升扩散模型的生成性能。
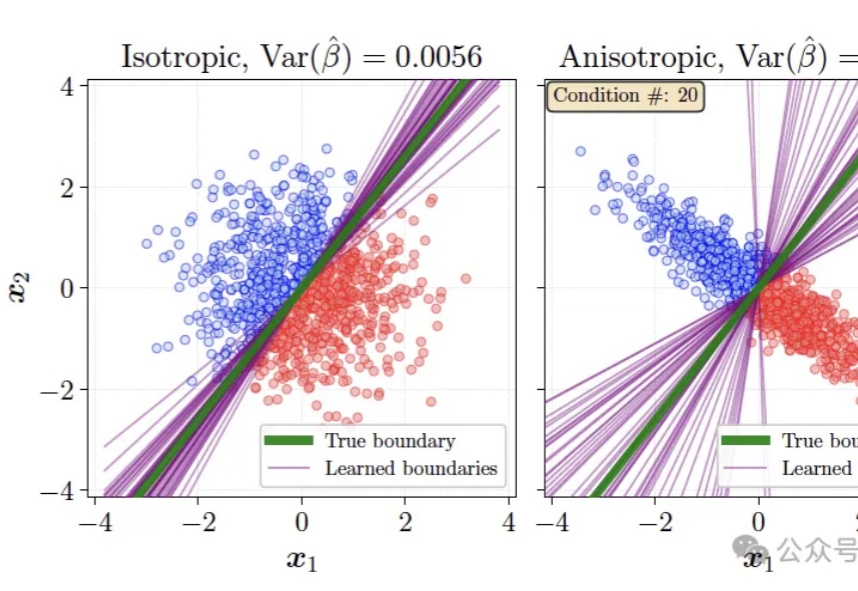
《LeJEPA:无需启发式的可证明且可扩展的自监督学习》。
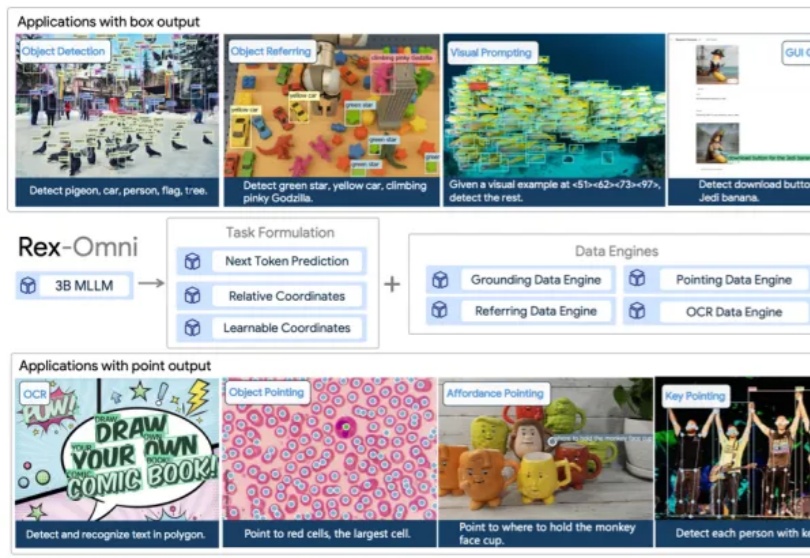
多模态大语言模型(MLLM)在目标定位精度上被长期诟病,难以匹敌传统的基于坐标回归的检测器。近日,来自 IDEA 研究院的团队通过仅有 3B 参数的通用视觉感知模型 Rex-Omni,打破了这一僵局。
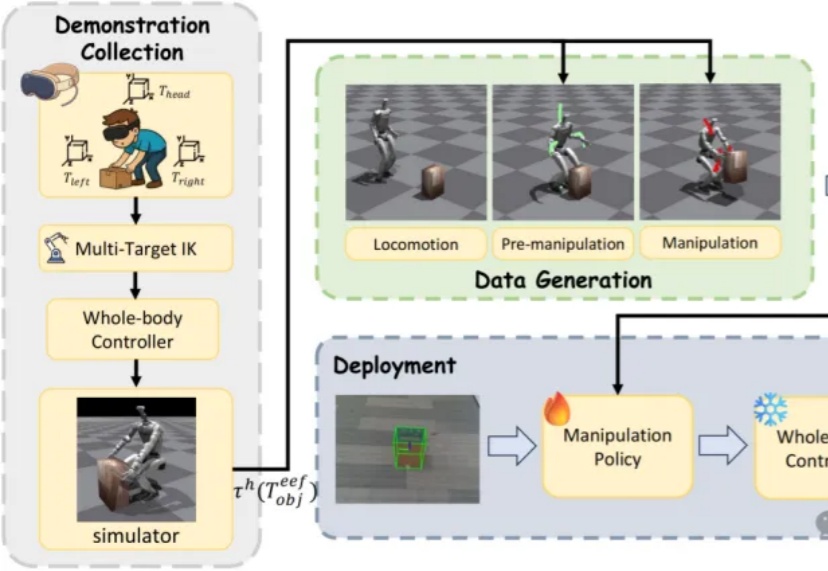
近日,来自北京大学与BeingBeyond的研究团队提出DemoHLM框架,为人形机器人移动操作(loco-manipulation)领域提供一种新思路——仅需1次仿真环境中的人类演示,即可自动生成海量训练数据,实现真实人形机器人在多任务场景下的泛化操作,有效解决了传统方法依赖硬编码、真实数据成本高、跨场景泛化差的核心痛点。

当前视频检索研究正陷入一个闭环困境:以MSRVTT为代表的窄域基准,长期主导模型在粗粒度文本查询上的优化,导致训练数据有偏、模型能力受限,难以应对真实世界中细粒度、长上下文、多模态组合等复杂检索需求。
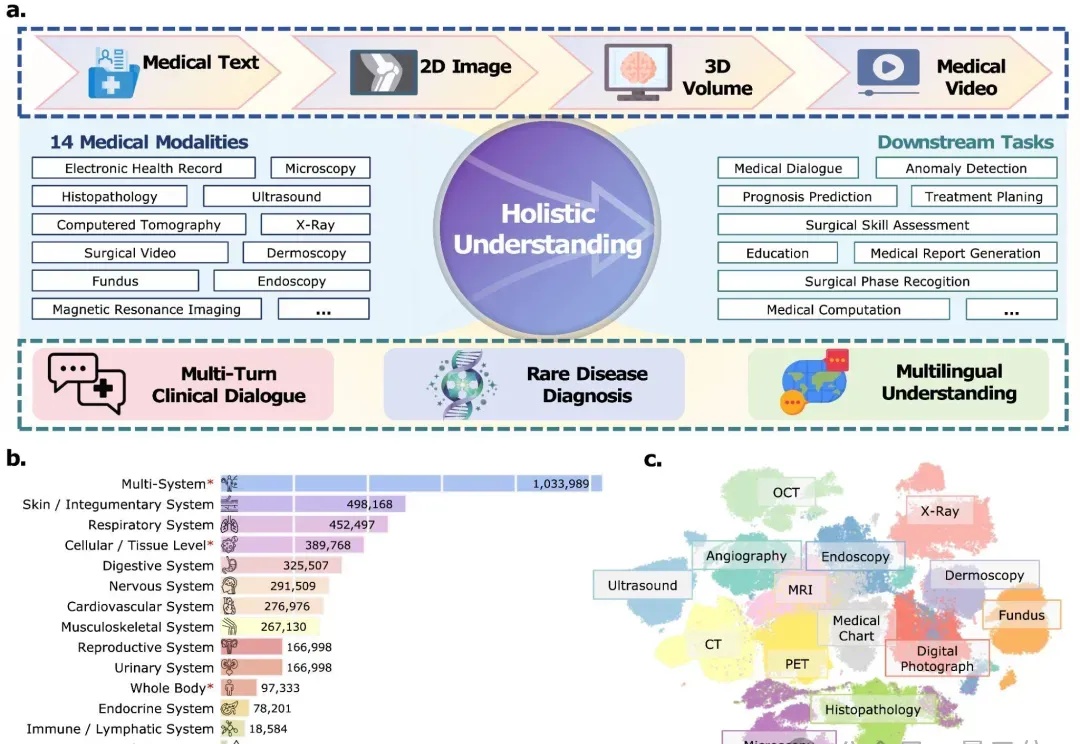
从影像诊断到手术指导,从多语言问诊到罕见病推理—— 医学AI正在从“专科助手”进化为“全能型选手”。

谷歌DeepMind的IMO金牌模型,完整技术全公开了!

大家好,我是 Ai 学习的老章 最近 GitHub 发布了 2025 年度开发者趋势报告

skill‑creator 是 Anthropic 在 Claude Skills 体系中提供的“元技能”。它本身是一个可直接在 Claude 对话中调用的 Skill,专门用于 帮助用户快速创建、编辑、打包其他自定义 Skill,从而让 Claude 能够在特定业务场景下拥有专业化的能力。
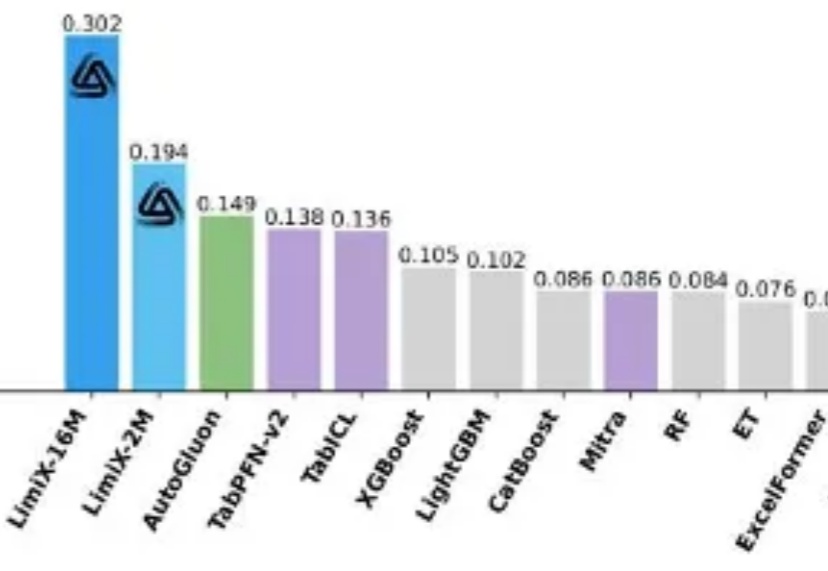
提到 AI 的突破,人们首先想到的往往是大语言模型(LLM):写代码、生成文本、甚至推理多模态内容,几乎重塑了通用智能的边界。但在一个看似 “简单” 的领域 —— 结构化表格数据上,这些强大的模型却频频失手。

“一位老师,用 AI 做了个《林黛玉初进贾府》的互动游戏。”

本文档分析 CAMEL 项目中 hybrid_browser_toolkit 的技术实现,覆盖其架构设计、核心功能与通信协议。
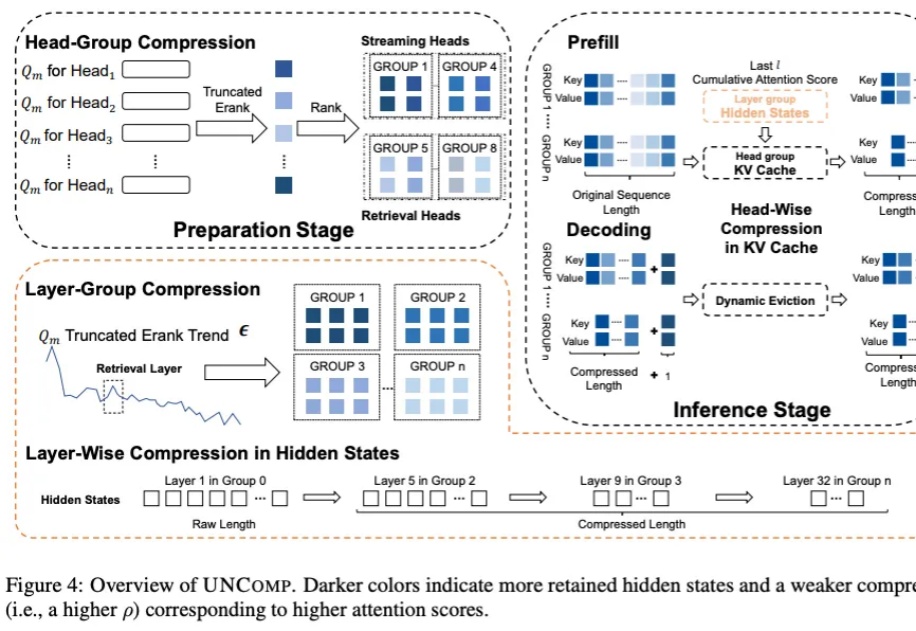
我们都知道 LLM 中存在结构化稀疏性,但其底层机制一直缺乏统一的理论解释。为什么模型越深,稀疏性越明显?为什么会出现所谓的「检索头」和「检索层」?
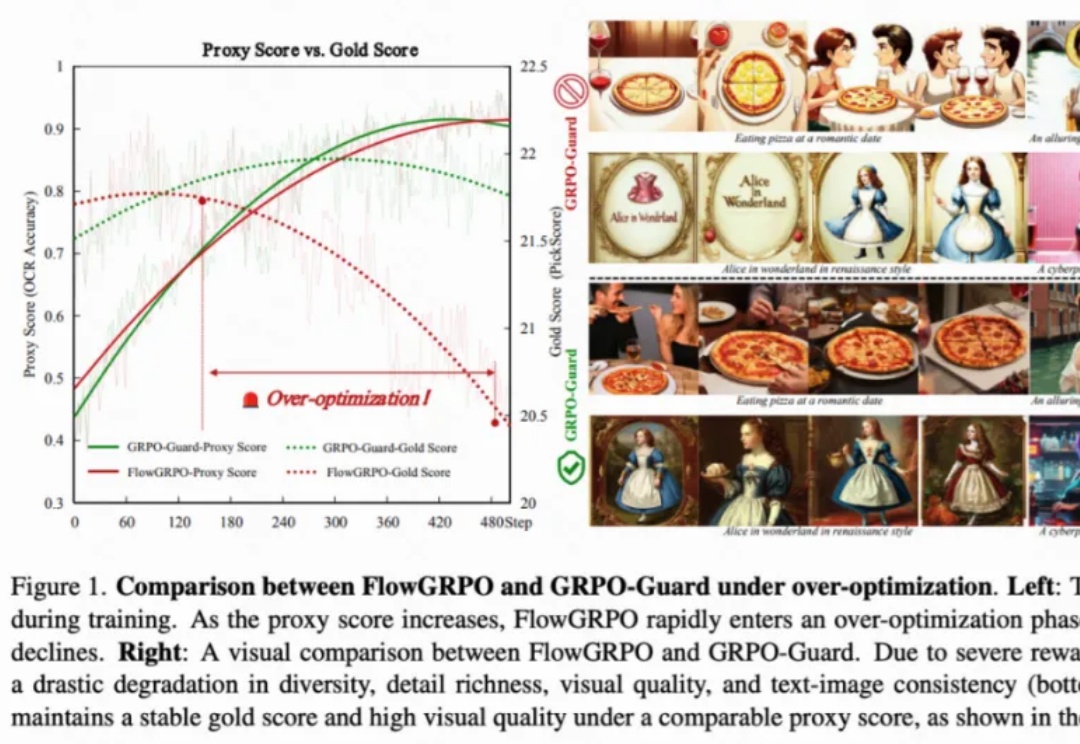
目前,GRPO 在图像和视频生成的流模型中取得了显著提升(如 FlowGRPO 和 DanceGRPO),已被证明在后训练阶段能够有效提升视觉生成式流模型的人类偏好对齐、文本渲染与指令遵循能力。
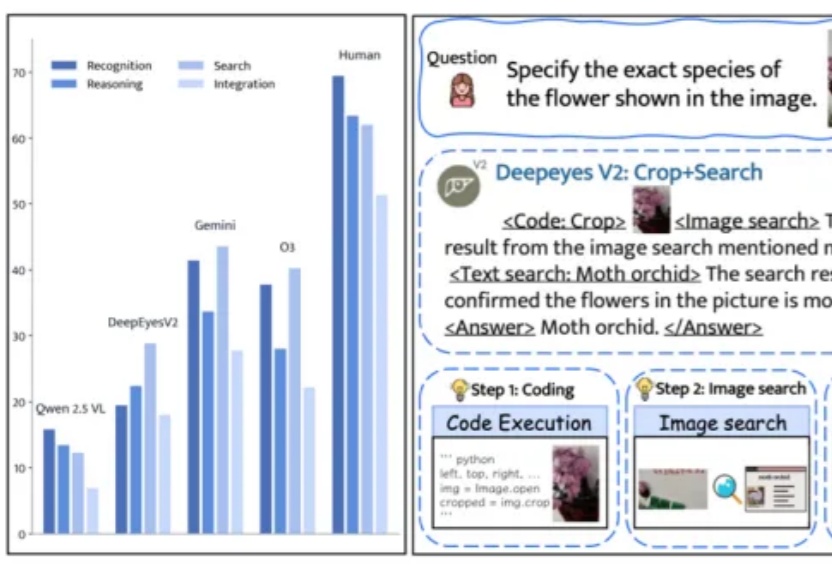
还记得今年上半年小红书团队推出的DeepEyes吗?

科学家用 AI 预测细胞未来的命运照进了现实——在虚拟世界中重塑生命系统,这对药物发现、早期筛选和疾病预防至关重要。
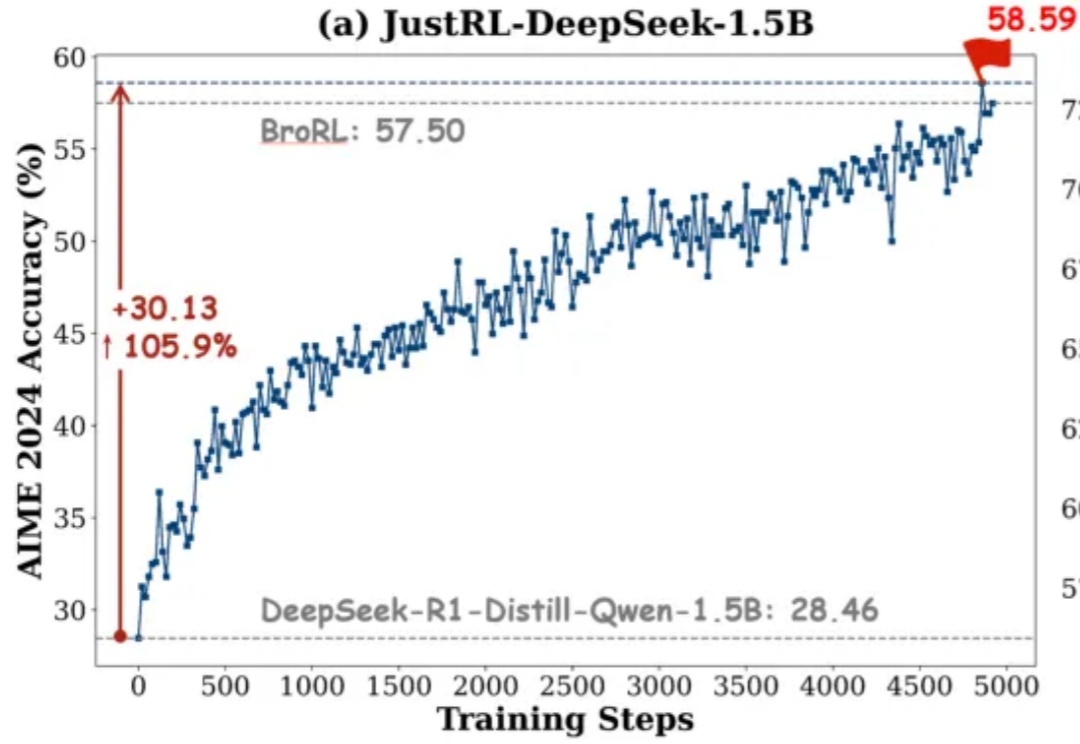
如果有人告诉你:不用分阶段做强化学习、不搞课程学习、不动态调参,只用最基础的 RL 配方就能达到小模型数学推理能力 SOTA,你信吗?
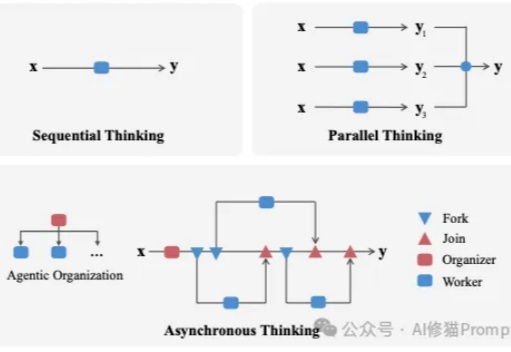
我们长期把LLM当成能独闯难关的“单兵”,在很多任务上,这确实有效。

华中科技大学团队推出首个水下多模态大模型NAUTILUS,支持8种水下场景理解任务,并开源145万图文对的NautData数据集。模型通过视觉特征增强模块解决水下图像模糊和颜色失真问题,性能超越现有模型,恶劣环境下表现更佳。

复杂的简历,AI也能读懂了。
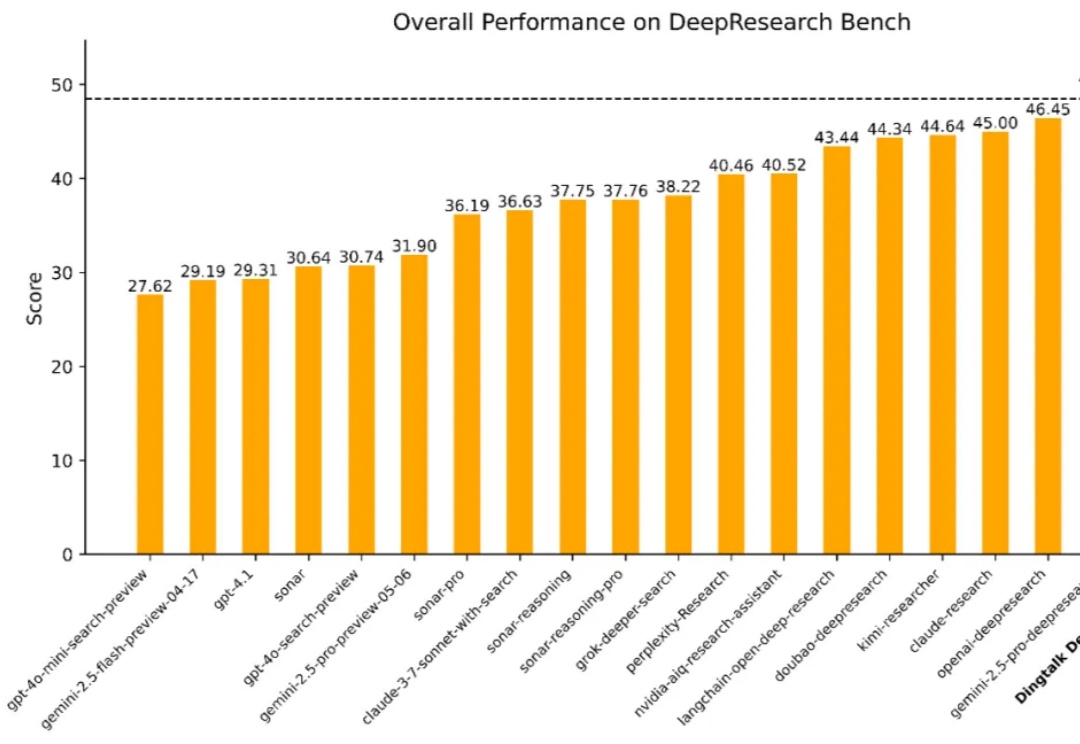
在数字经济浪潮中,企业对于高效、精准的信息获取与决策支持的需求日益迫切。从前沿科学探索到行业趋势分析,再到企业级决策支持,一个能够从海量异构数据源中提取关键知识、执行多步骤推理并生成结构化或多模态输出的「深度研究系统」正变得不可或缺。

开发者最常使用的编程语言是什么?相信很多人都会不假思索地选择 Python。

浙江大学和新加坡南洋理工大学新研究旨在探索空间碳中和数据中心的可行性。太空环境具备两大独特优势:丰富的太阳能可为计算设备提供清洁稳定的电力;接近绝对零度的深空环境则为服务器废热提供了理想的散热条件。

麦肯锡刚刚发布了2025年AI最新报告,一组数据让人“破防”:88%的组织都在用AI,但只有39%的组织吃出了“真金白银”。这份《The state of AI in 2025》回答了AI时代大家都很关心的一个问题:

四个审稿人全给6分,NeurIPS唯一满分论文炸了!
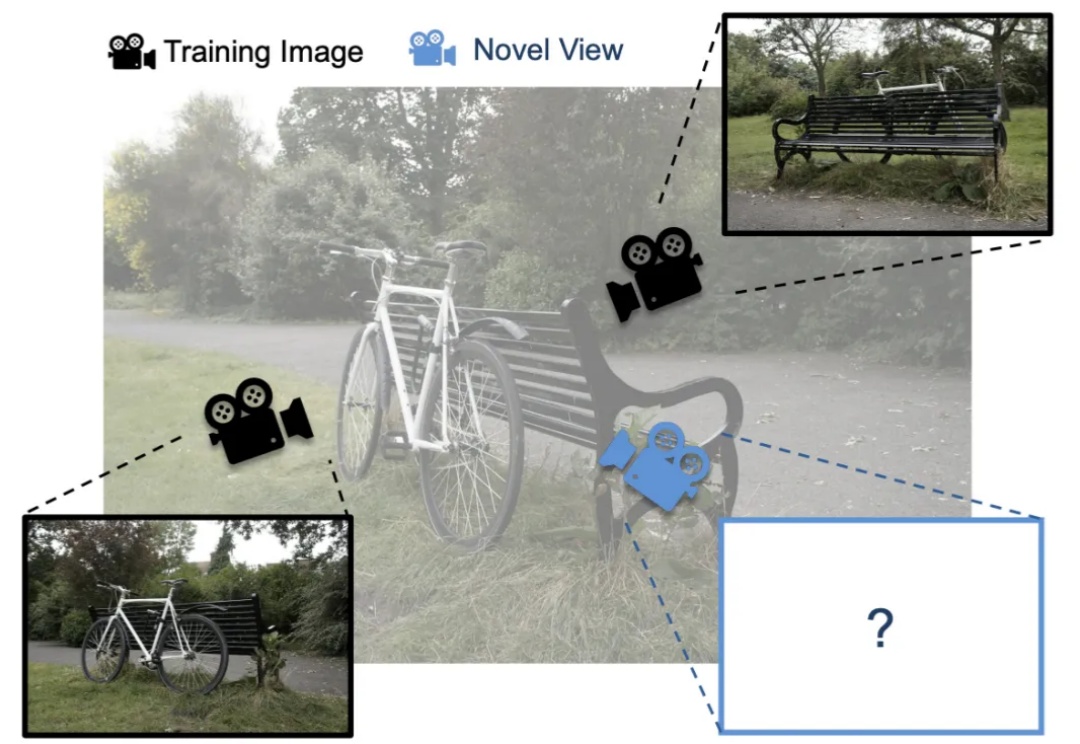
3D Gaussian Splatting (3DGS) 是一种日益流行的新视角合成方法,给定 3D 场景的一组带位姿的图像(即带有位置和方向的图像),3DGS 会迭代训练一个场景表示,该表示由大量各向异性 3D 高斯体组成,用以捕捉场景的外观和几何形状。

英伟达在聚光灯下狂飙,谷歌却在幕后悄悄造出自己的AI基建帝国系统。当别人还在抢GPU时,它早已自给自足、闭环生长——闷声干大事,从未如此谷歌。

临床诊断并非一次性的「快照」,而是一场动态交互、不断「探案」的推理过程。然而,当下的大模型大多基于静态数据训练,难以掌握真实诊疗中充满不确定性的多轮决策轨迹。如何让AI学会「追问」、选择检查,并一步步抽丝剥茧,迈向正确诊断?

2025年末,谷歌通过Kaggle平台,以前所未有的力度,连续推出了两个为期五天的线上强化课程。这不仅仅是两次普通的线上分享,更像是一场由谷歌顶级机器学习(ML)研究员和工程师亲自引领的、深入探索生成式AI及其前沿应用——AI Agents(人工智能代理)的集训。
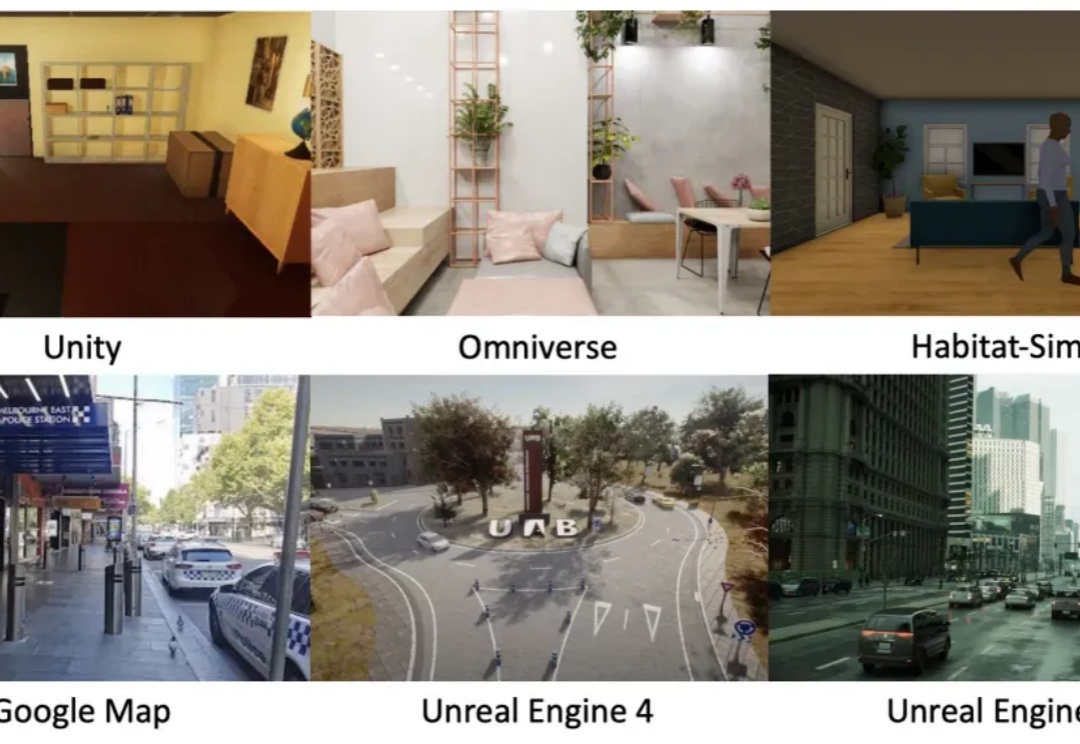
你是否曾为搭建具身仿真环境耗费数周学习却效果寥寥? 是否因人工采集海量交互数据需要高昂成本而望而却步? 又是否因找不到足够丰富真实的开放场景让你的智能体难以施展拳脚?