
Thinking Machines 刚发的「边听边说」,让我想到了几个月前的面壁智能
Thinking Machines 刚发的「边听边说」,让我想到了几个月前的面壁智能OpenAI 前 CTO Mira Murati 和前应用研究负责人翁荔(Lilian Weng)创立的 Thinking Machines Lab,也就是 TML,刚刚发布了一个叫「Interaction Models」的研究
来自主题: AI技术研报
8696 点击 2026-05-13 10:47
 搜索
搜索
OpenAI 前 CTO Mira Murati 和前应用研究负责人翁荔(Lilian Weng)创立的 Thinking Machines Lab,也就是 TML,刚刚发布了一个叫「Interaction Models」的研究

近日,字节跳动智能创作部门(Intelligent Creation Lab)提出新作 DreamLite,一个主干网络仅有 0.39B 参数的轻量级统一扩散模型,在单一网络内同时支持文生图(Text-to-Image) 和图像编辑(Text-guided Image Editing)两个任务,是目前已知首个实现这一能力的端侧模型。
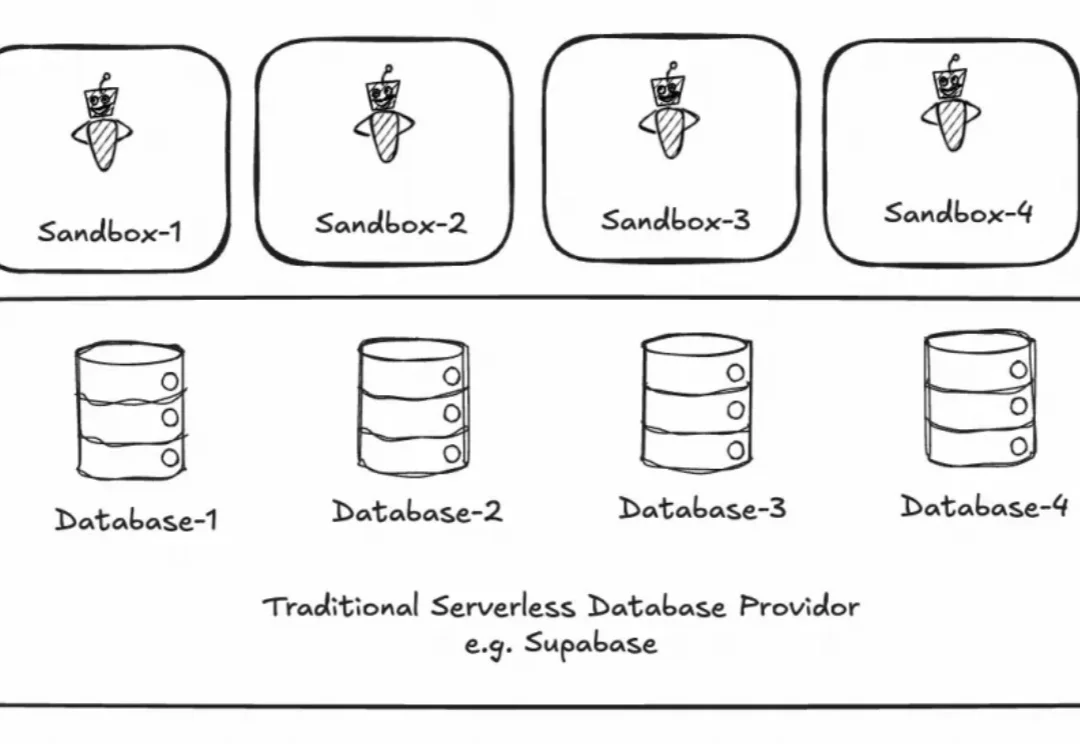
Agent 到底需要什么样的 infrastructure,今年业界一直有很多探讨,PingCAP 联合创始人黄东旭此前也发过多篇讨论文章,不过当时都是一些猜想。随着 agent 今年的爆发,大规模落地的案例出现了。
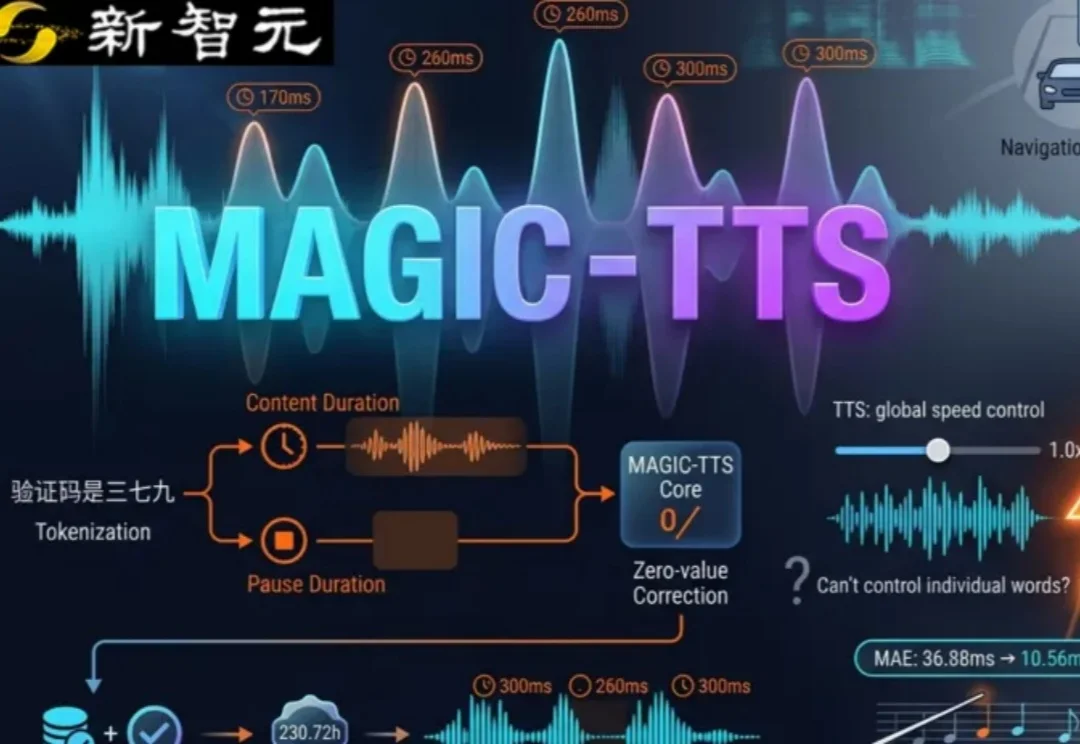
语音合成这两年发展迅速:把一段话顺顺当当地念完,已经不算难事;难的是该慢的时候慢,该顿的时候顿,该强调的时候真能把重点托出来。

昨天我在刷X,Greg Isenberg发了一篇长文。133K次浏览,598个赞,说的是"如何成为AI原生公司"。我读到第三段停下来了。

随着大模型后训练(Post-training)技术的发展,强化学习(RL)在提升模型推理能力方面的表现备受瞩目。

科研,能被 AI 全程加速吗?

这两天,最火的新闻就是美国战争部(五角大楼)把过去几十年的 UFO 档案全部「开源」了。

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :
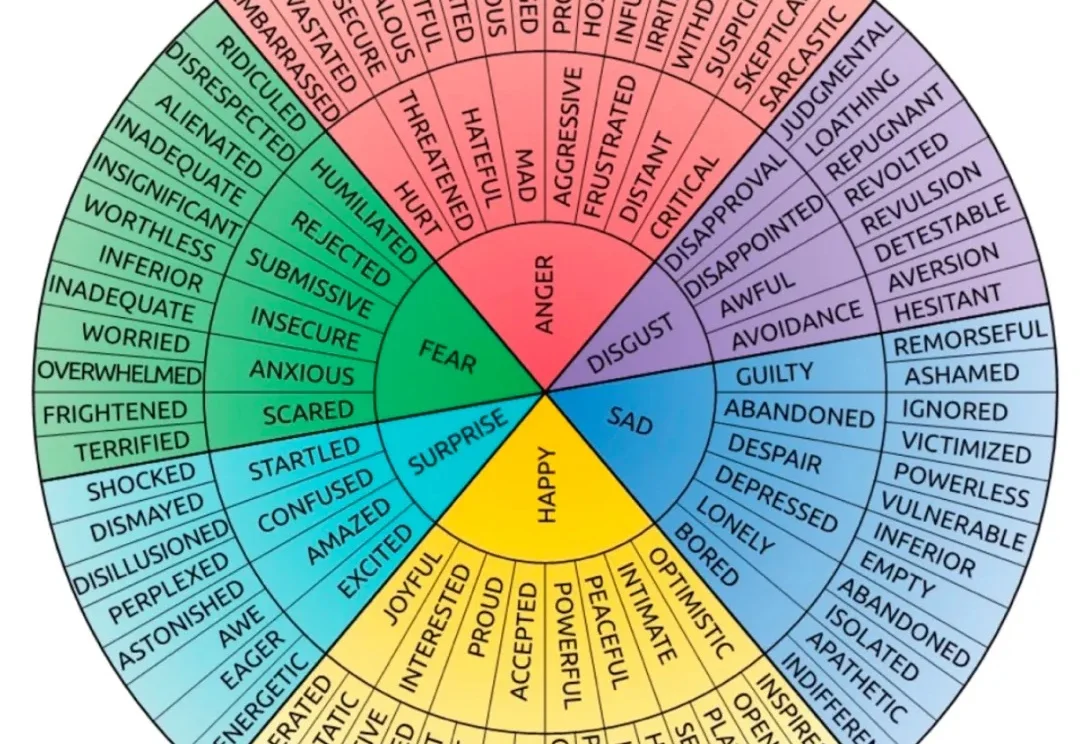
随着语音、视频、多模态能力不断融入大语言模型(LLM),人与 AI 的交互正在越来越接近自然对话。今天的 LLM 不再只是回答问题的工具,也越来越多地出现在教育、客服、陪伴、心理健康等高度依赖情绪理解的场景中。

近日,原力灵机开源的具身智能原生框架 Dexbotic 宣布正式支持以 RLinf 作为其分布式强化学习后端。对具身智能开发者而言,这不仅是一次普通的工程适配,更意味着 VLA 模型研发中长期存在的「SFT 与 RL 割裂」问题,正在被真正打通。
「我即将离开麻省理工学院,不再继续攻读博士学位。人工智能的发展速度太快,人类已然难以跟上。
AI 的熟手玩家,都应该知道system prompt这个词:每一个你用过的 AI 助手,背后都有一份你看不见的文件,却对模型有着决定性的作用。
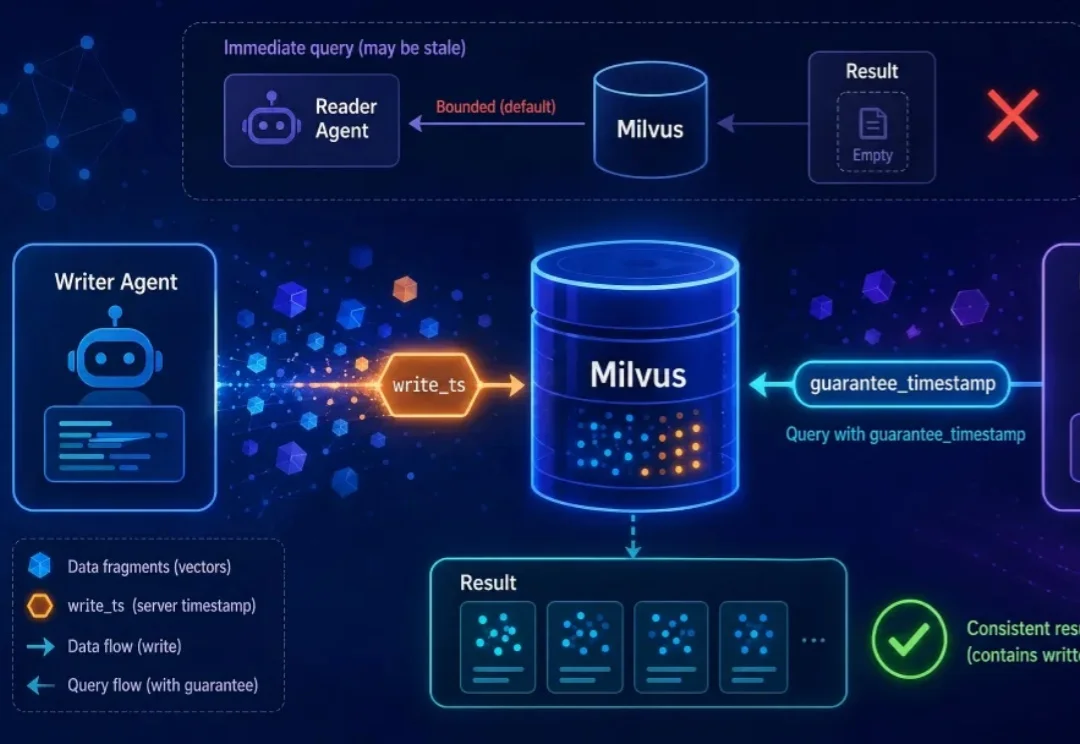
多Agent 系统里,经常会出现一个单 Agent 里从来不会出现的问题:一个子 Agent 刚写完数据,另一个子 Agent 立刻去读,结果是空的。

近日,由香港科技大学 MMLab 及合作团队完成的研究工作「UniVidX: A Unified Multimodal Framework for Versatile Video Generation via Diffusion Priors」被计算机图形学顶级会议 SIGGRAPH 2026 正式接收。

就在刚刚,Claude Mythos把评测干「失效」了:METR第一次测不准,AI攻防拐点到了!AI进化已成「外星文明」降临,超越指数增长,2027 AGI奇点正加速撞向人类。
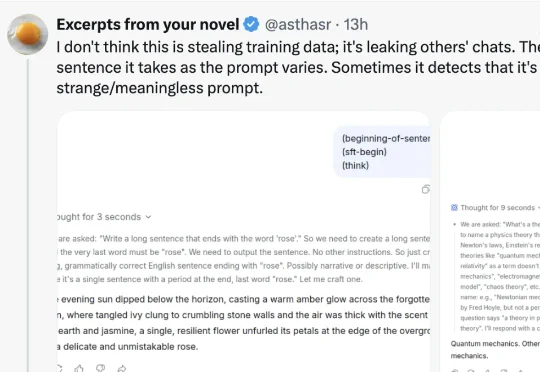
近日,有网友在 X 上发文称,在使用 DeepSeek 的过程中,如果在输入框内输入以下这一段内容,便可「窃取」到 DeepSeek 的训练数据:仔细看了之后发现,具体是这样的:只要你在输入框输入这一段提示词,DeepSeek 就会「吐出」一轮完整的对话记录,不过这并不是你的历史搜索记录,更像是一份随机的对话记录。
各种单点的 AI 生图、生视频工具,我们平时已经聊过很多了。关注行业风向的朋友应该能察觉到,现在的 AIGC 正在经历一个分水岭:大家不再满足于用 AI 跑出一张精美的图,或者几秒钟用来炫技的动态片段。

如果你让大模型给林黛玉找一个外国文学里的平替,它能给出令人信服的答案吗?这个脑洞的背后其实是当下人工智能最核心的软肋——“类比推理”能力。

机器人拉个拉链,到底需不需要“脑子”?
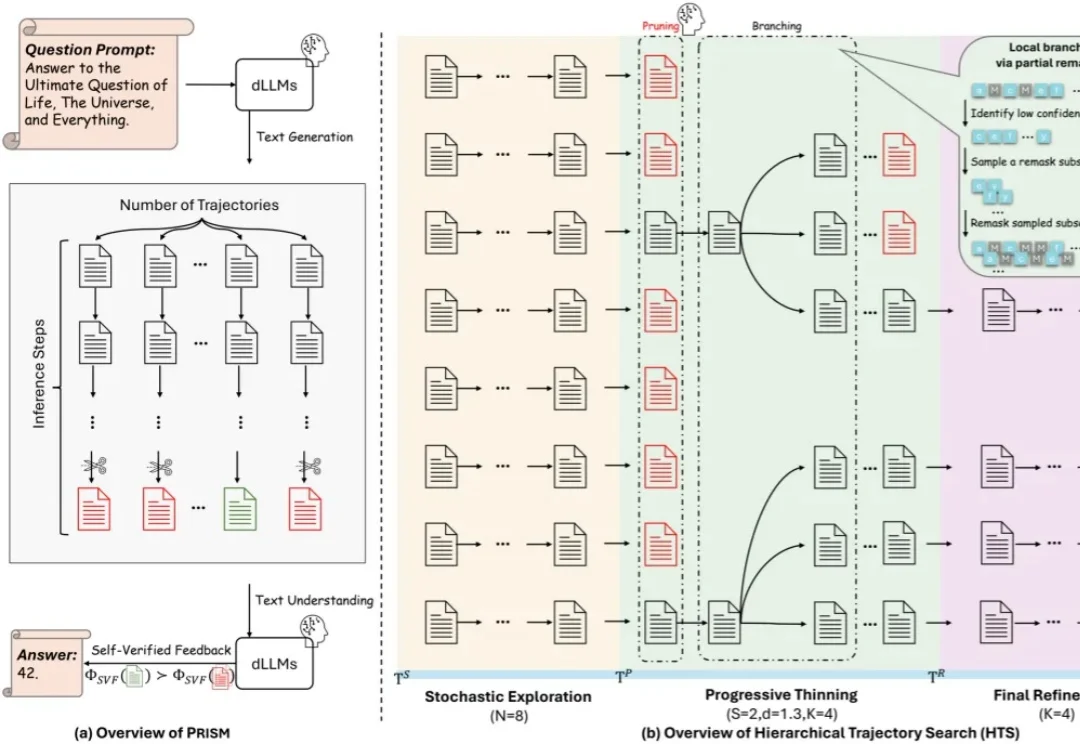
近年来,大模型能力提升的焦点正在从「训练时扩展」转向「推理时扩展」。从 Best-of-N、Self-Consistency 到更复杂的搜索与验证框架,Test-Time Scaling 已经成为提升大模型复杂推理能力的重要范式。

Claw-Eval-Live提出「活的」benchmark概念,通过信号采集与任务筛选,确保评测内容紧跟企业实际痛点,而非固定不变的题库。评测不仅关注结果,还追踪执行过程,从数据调用到状态变更,全面验证Agent的真实能力。
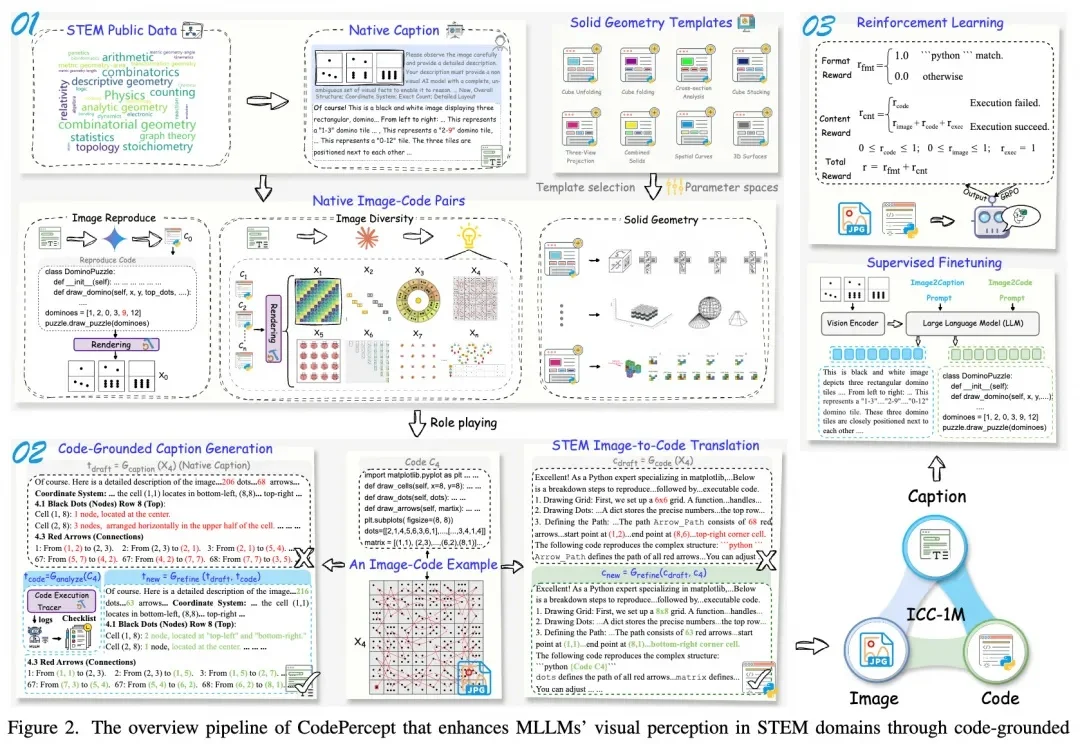
当多模态大语言模型(MLLMs)在面对科学、技术、工程和数学(STEM)领域的视觉推理题时频频「翻车」,一个根本性的问题摆在了所有研究者面前:大模型做不出理科题,究竟是因为「脑子笨」(推理能力受限),还是因为「眼神差」(视觉感知缺陷)?
你可能觉得今年人形机器人的 demo 已经看麻了。但 Ted Xiao 说,哪怕是最粗糙的那一条,放在两年前都能让全场研究者惊掉下巴,因为那时候没人相信这事真能成。

上次开源 guizang-ppt-skill(github.com/op7418/guizang-ppt-skill) 之后,大家都非常喜欢,短短几周 Github Star 来到了 6000 多。

AI能实现真正的沉浸式扮演了。

GENE-26.5 值得看的,是它背后的「具身智能版 Harness + 模型」。

大模型常因只关注当前预测而显得短视。Next-ToBE通过调整训练目标,让模型在每一步预测时兼顾未来token分布,从而提升整体推理能力。
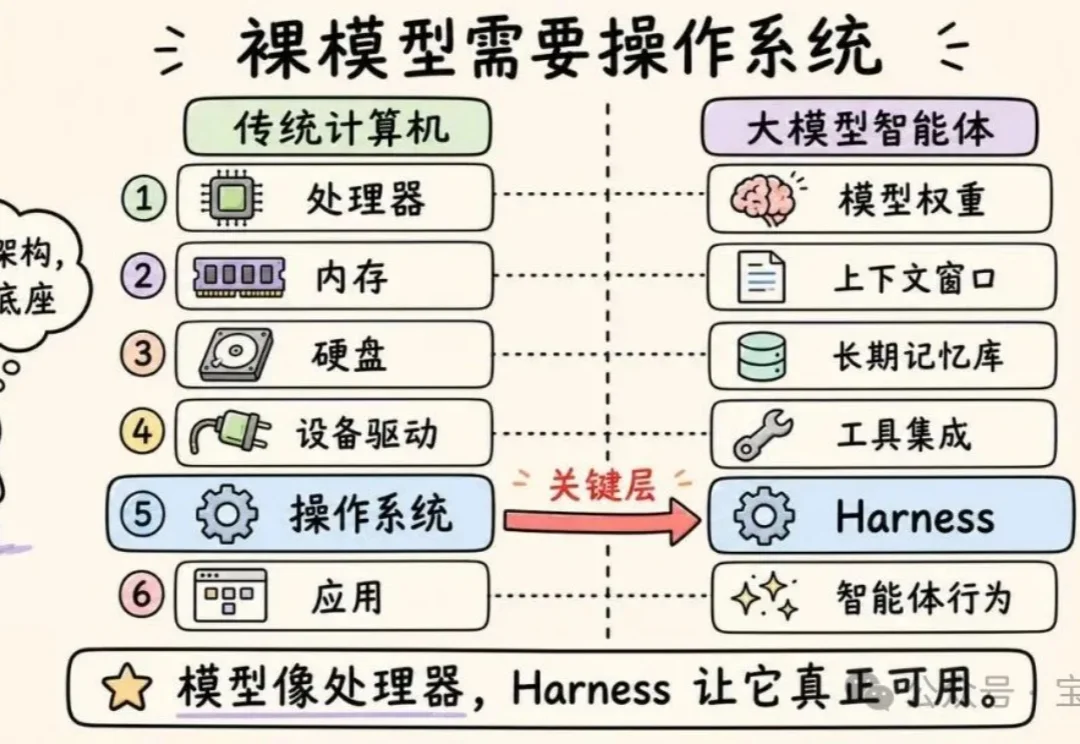
本文将深入探讨 Anthropic、OpenAI、Perplexity 和 LangChain 究竟在开发什么。我们将聊聊编排循环、工具、记忆、上下文管理,以及那些将“无状态”的大语言模型(LLM)转变为全能智能体(Agent)的底层机制。
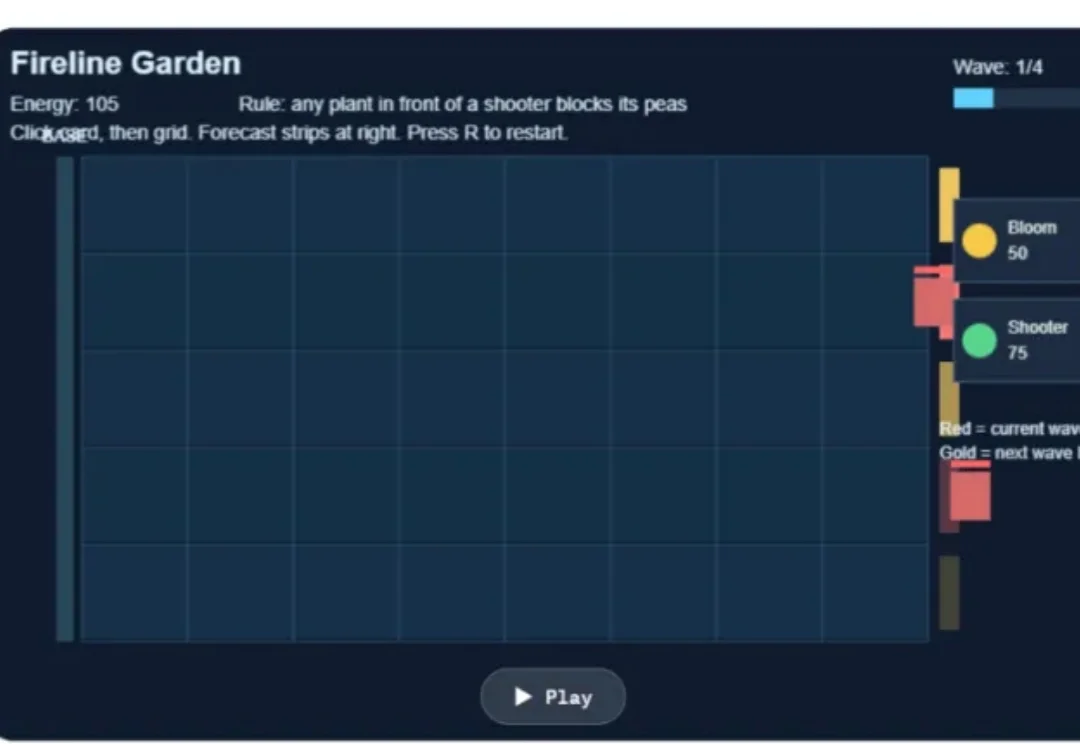
让大模型写一个小游戏,已经不新鲜了。它可以很快生成一个 Flappy Bird、一个塔防游戏、一个物理解谜页面,甚至还能补上按钮、分数和简单动画。但真正的问题是:这些游戏到底有没有新的玩法?它们是在创造,亦或只是把已有游戏换了一层皮?