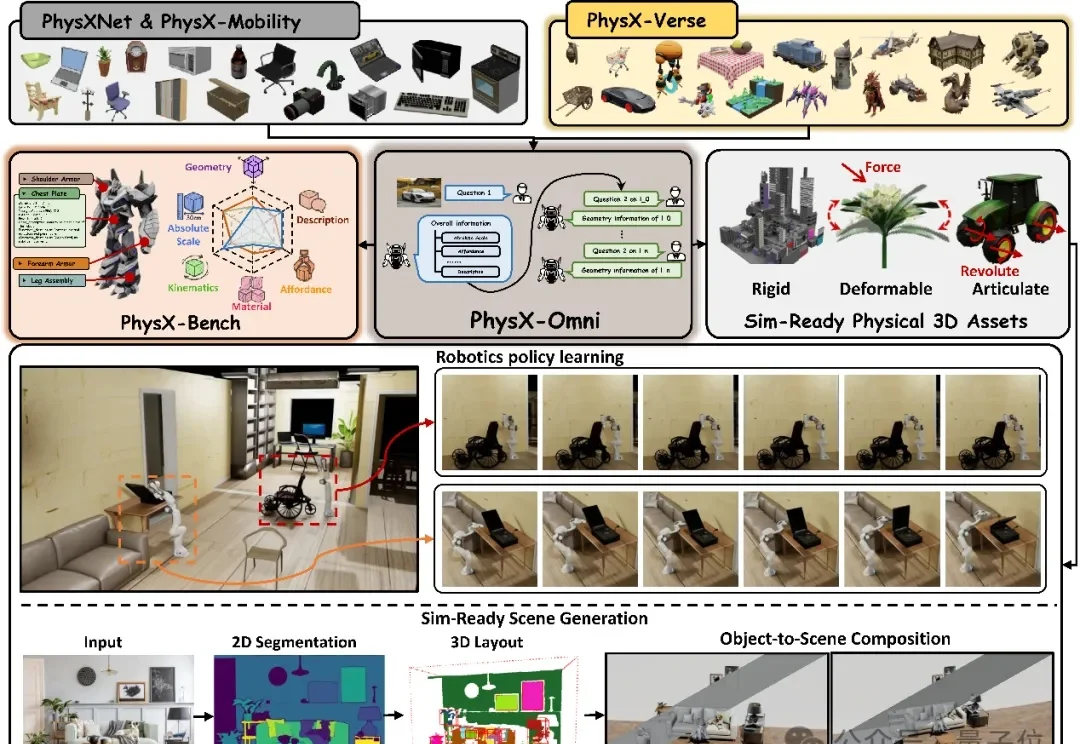
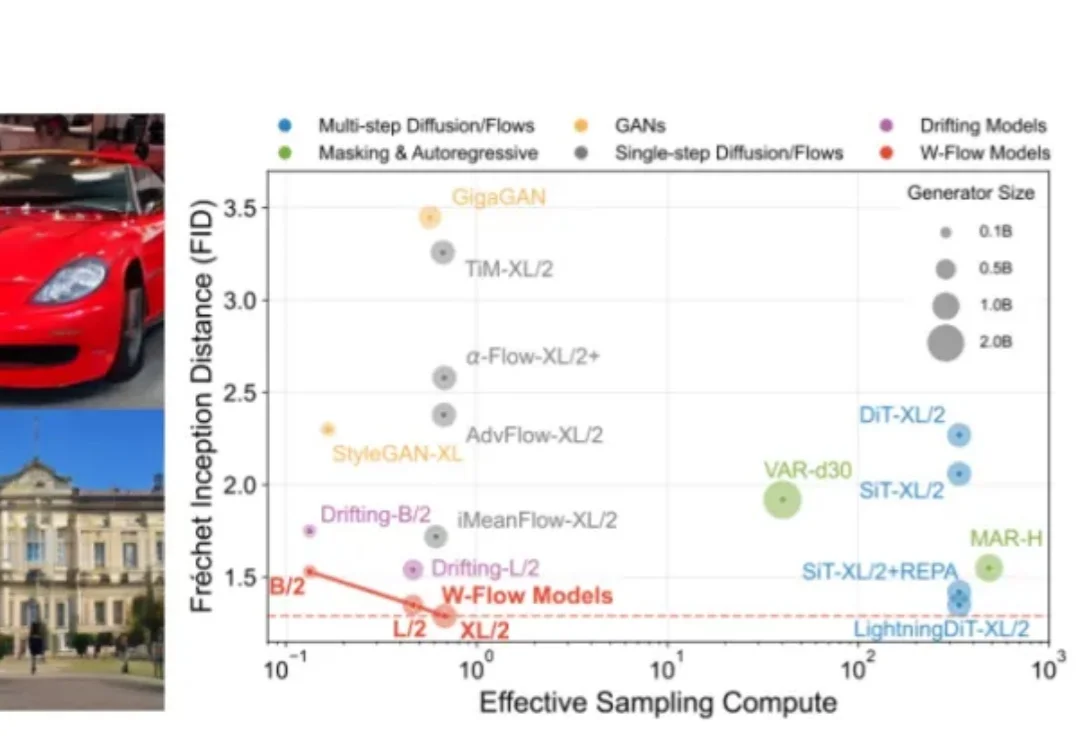
「这可能是人类写的最后一篇论文」Stanford、Michigan、CMU 等 37 位学者联手:把论文从 PDF 改写成 AI 能直接执行的研究包
「这可能是人类写的最后一篇论文」Stanford、Michigan、CMU 等 37 位学者联手:把论文从 PDF 改写成 AI 能直接执行的研究包我们今天以 PDF 写论文的方式,已经持续了三百多年。然而论文其实是把一段混乱反复、充满试错的真实研究,讲成一个干净利落、足以服人的完美故事。
来自主题: AI技术研报
10731 点击 2026-06-05 09:25