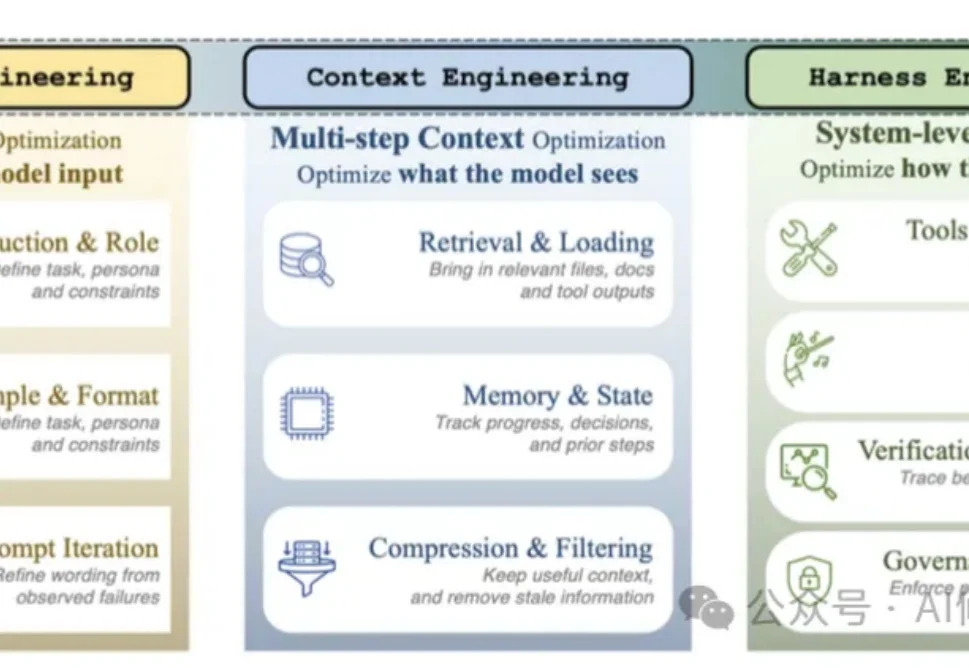
Agent Harness Engineering:Agent的底盘工程综述|CMU、耶鲁、Amazon
Agent Harness Engineering:Agent的底盘工程综述|CMU、耶鲁、Amazon经常切换使用CC、Codex、OpenClaw这类Agent的人会发现:同一个模型,放进不同系统里,表现可能完全不同。
来自主题: AI技术研报
9909 点击 2026-05-19 14:58
 搜索
搜索
经常切换使用CC、Codex、OpenClaw这类Agent的人会发现:同一个模型,放进不同系统里,表现可能完全不同。
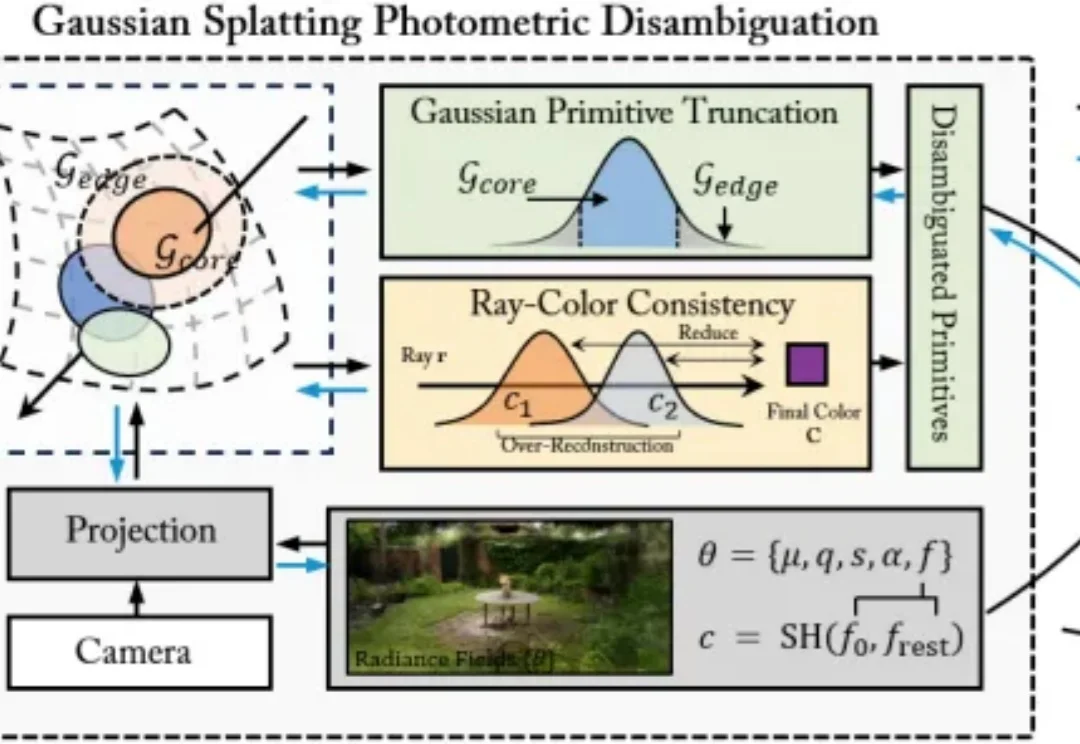
近年来,3D 高斯泼溅(3D Gaussian Splatting, 3DGS)凭借其卓越的新视角合成能力和实时的渲染效率,极大地推动了神经渲染技术的发展。然而,当研究者试图直接从 3DGS 中提取精确的 3D 几何表面(Mesh 等)时,往往会面临严重的几何失真问题。

传统API集成已死!在这个Agent满地跑的时代,被低估的搜索终于迎来了第四次范式转移。AnySearch的问世,让Agent告别了单一的网页总结功能,转而通过获取可信的结构化信息,真正具备触达并连接现实世界的能力。

最近一段时间,Agent 又一次成为 AI 圈最热的关键词。

大语言模型真的只能走“预测下一个token”的路子吗?

OpenAI 的 Codex App 正式开放了远程控制功能。
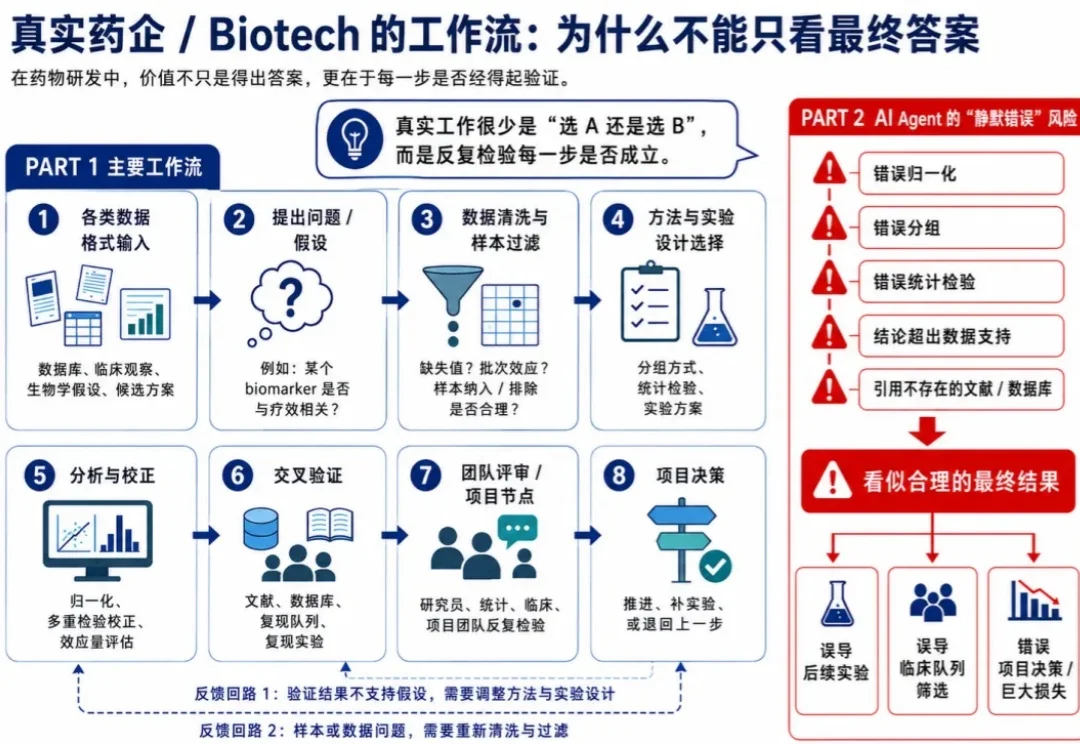
xbench,就是红杉自己弄的那个中立评测lab,刚刚又整了个新活:让 AI 做药企的数据分析,跟人类实习生比个高低,然后遥遥领先的赢了

全行业都在押注多Agent。
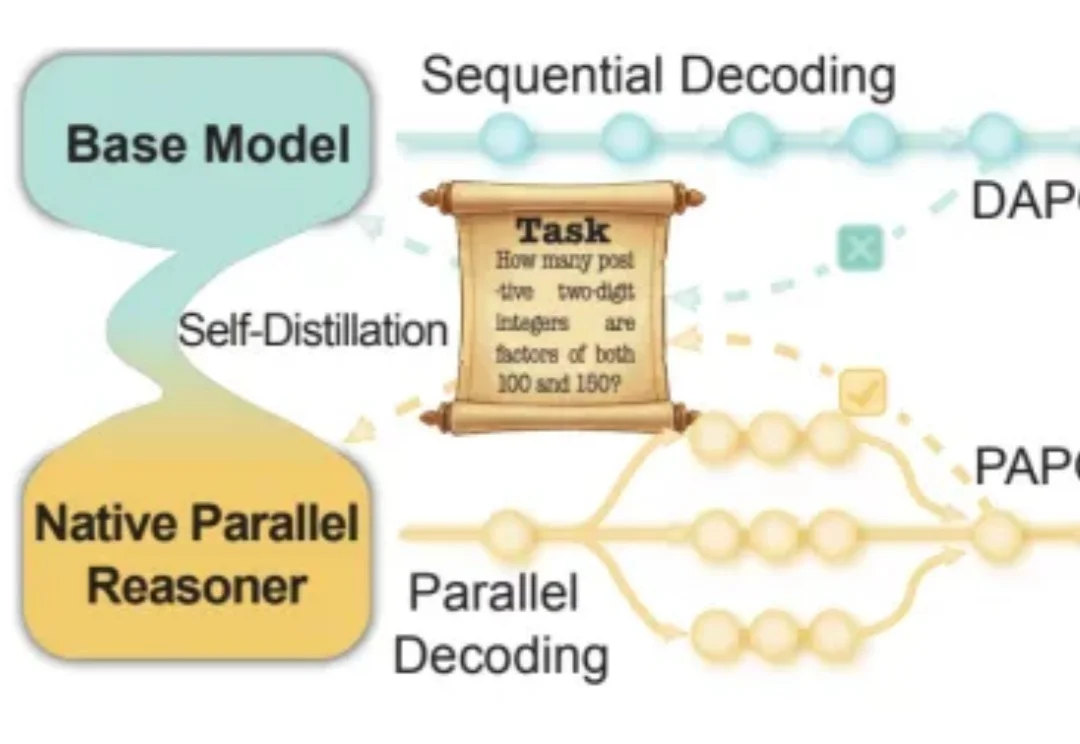
近年来,大语言模型在「写得长、写得顺」这件事上进步飞快。但当任务升级到真正复杂的推理场景 —— 需要兵分多路探索、需要自我反思与相互印证、需要在多条线索之间做汇总与取舍时,传统的链式思维(Chain-of-Thought)往往就开始「吃力」:容易被早期判断带偏、发散不足、自我纠错弱,而且顺序生成的效率天然受限。

近年来,Chain-of-Thought(CoT)推理已经成为提升大语言模型和多模态大语言模型复杂问题求解能力的重要技术路径。

过去一年,Agent学会了两件事:会用工具、会调用Skill。
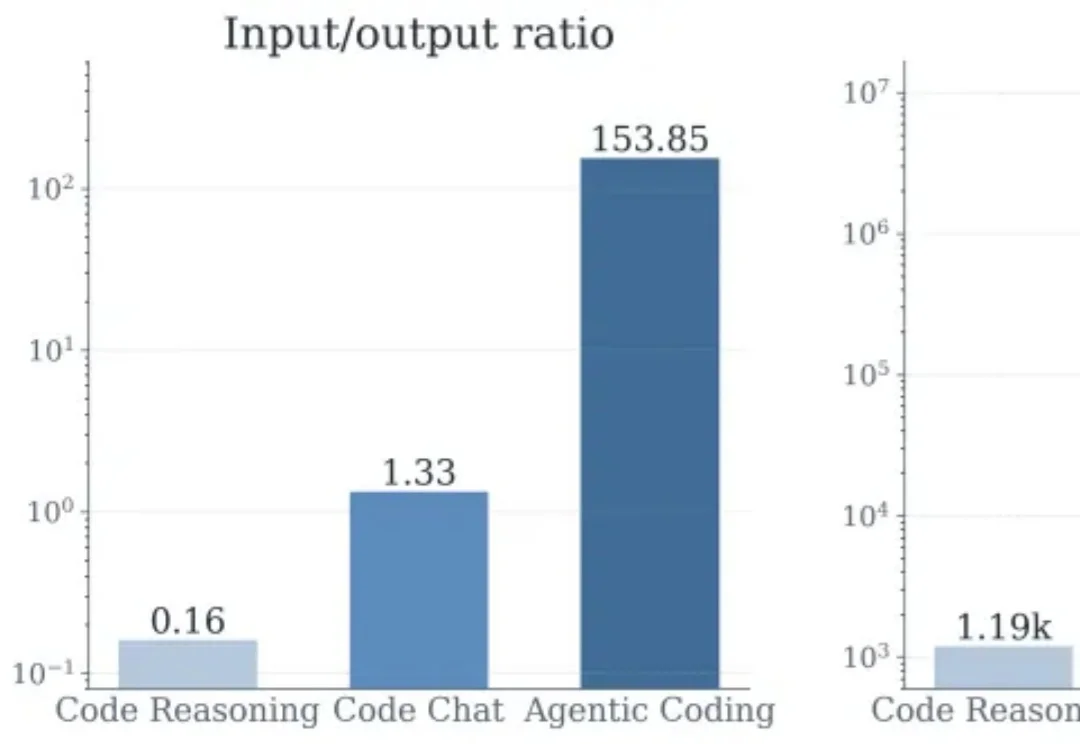
如今的 AI Agent 正在大规模落地,其中应用最广且最受关注的当数 Claude Code,Codex,Cursor 这类 coding agent。过去的一年里,这类 coding agent 产品迭代迅速,在一年内将在 swe-bench- verified 的准确率提高到了 78%+。
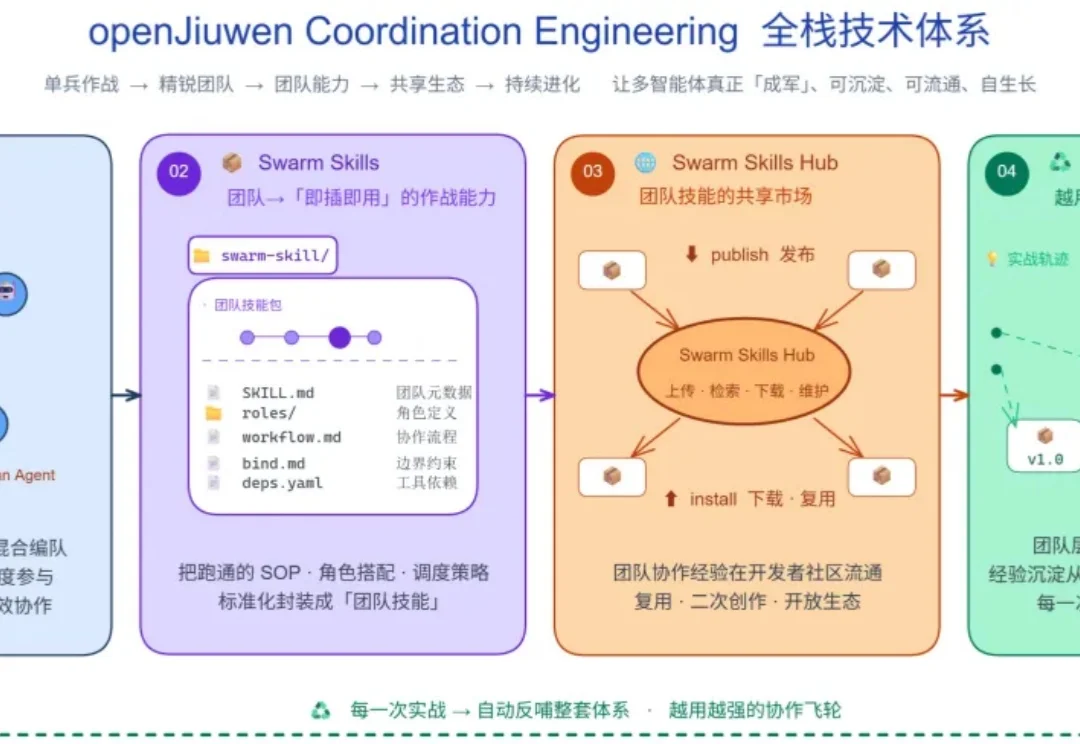
刚刚,华为支持的开源 AI Agent 平台社区 openJiuwen 发布并开源了蜂群智能体 JiuwenSwarm。

Mechanize 发布了一项硬核测试:给前沿 AI coding agents 24 小时,用 Rust 从零写一个完整的 Game Boy Advance 模拟器,再和顶级开源模拟器 Mesen2 逐帧对比打分。

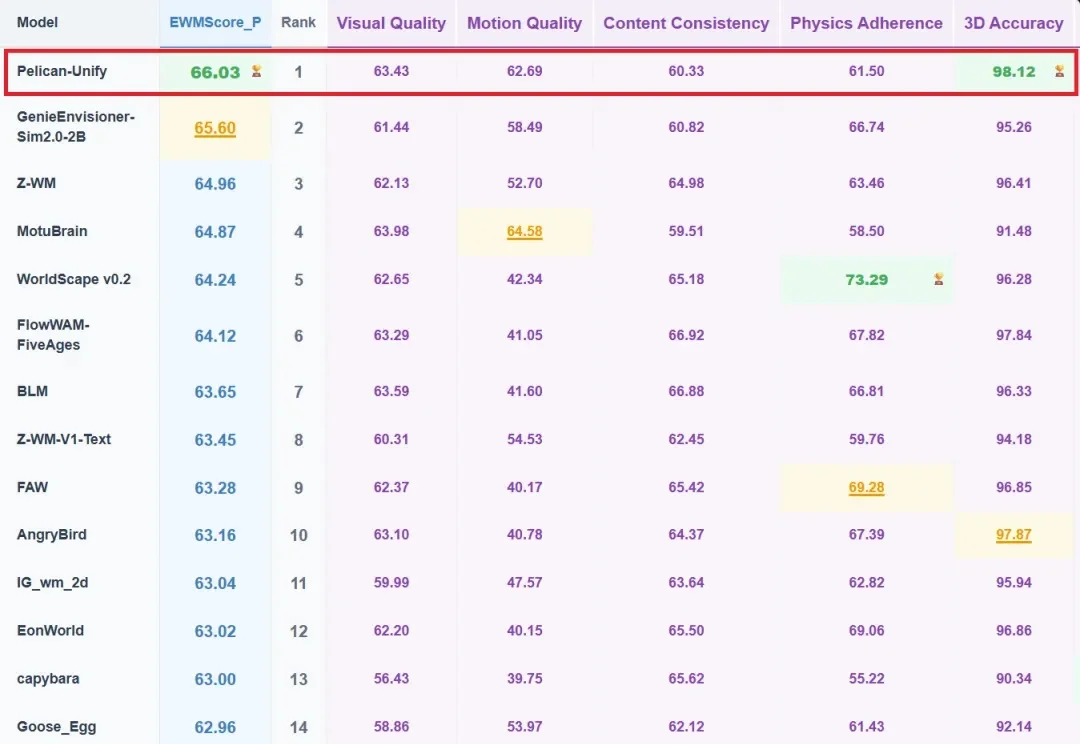
世界模型(World Model),想必你已经在很多场合听过这个术语了。它有时出现在视频生成领域,有时又出现在具身智能领域;它们的含义还有所差别,甚至看起来像是完全不同的概念。
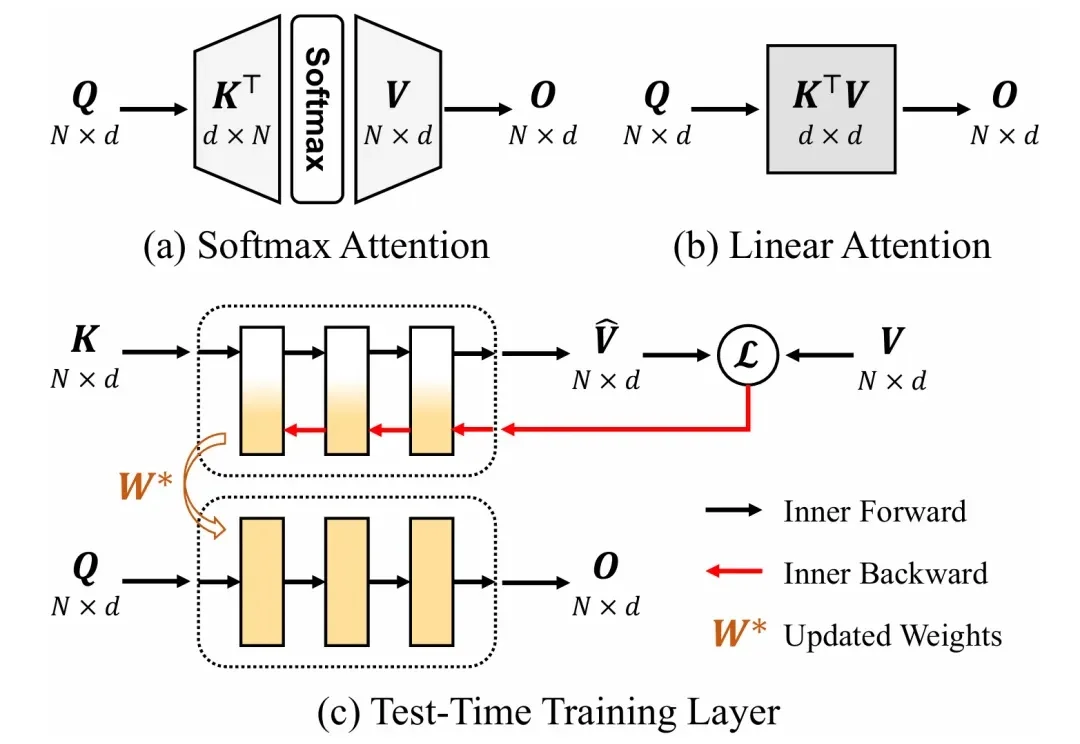
序列建模是大语言模型、计算机视觉等领域的基础共性问题。当前通用的 Transformer 模型计算复杂度随序列长度平方增长,在长序列任务中面临显著的计算挑战。因此,研究者们一直在探索具有线性计算复杂度的高效序列建模方法。
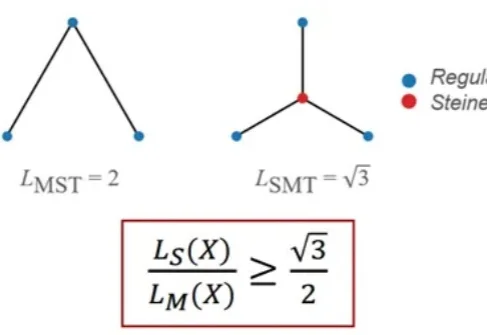
近期,LLM 已经在 IMO 上取得了很好的成绩,在一些研究级数学上(如短程证明、组合构造)也有所进展。但如果真正让 LLM 去处理提出数十年的数学猜想,结果会是如何?
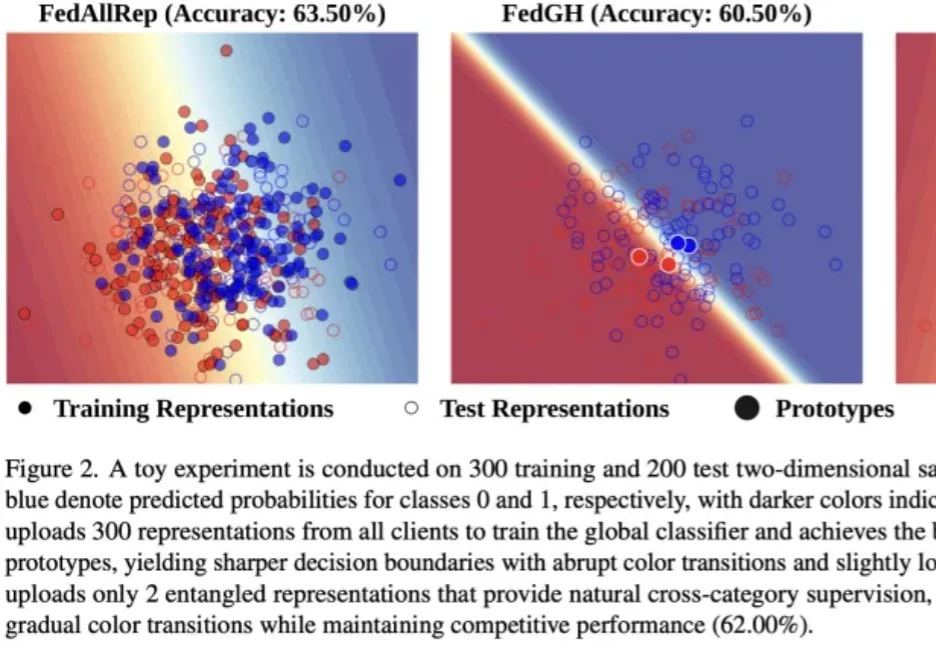
在联邦学习中,如何同时兼顾模型性能、数据隐私和通信开销,是一个亟需解决的挑战。
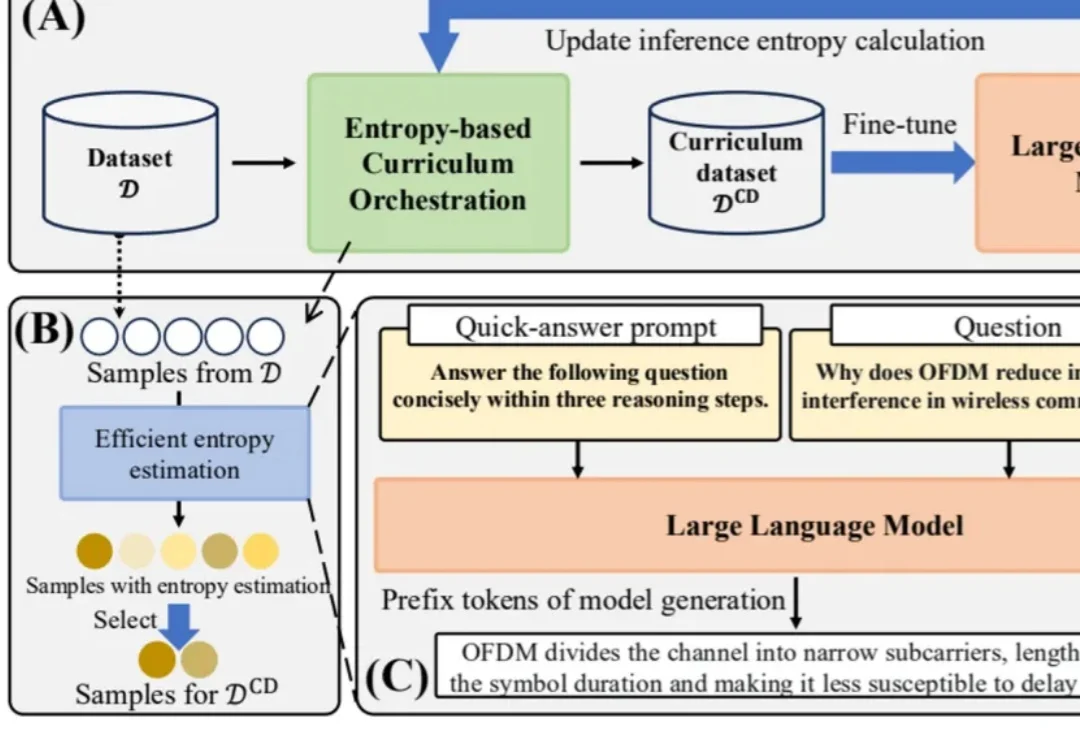
在大模型后训练中,数据不再只是 “越多越好”,而是要像人类学习一样,动态选择最合适难度的样本。华为提出的 EDCO 方法,将样本难度估计与动态课程编排引入领域大模型微调;数月后,由 Rutgers、Amazon、Google 等作者参与的 DARE 论文即引用 EDCO,并将其作为难度感知强化学习训练的重要对比基线。
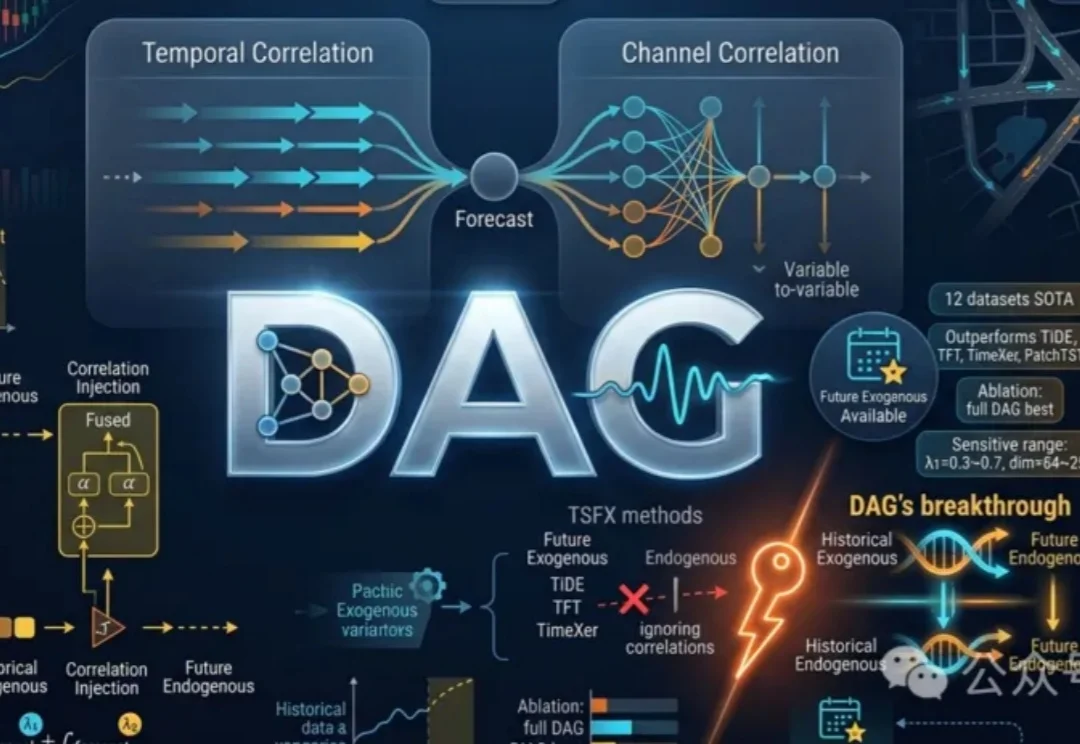
DAG框架利用时间与通道双重相关网络,有效整合历史与未来外生变量信息,提升时间序列预测准确性。通过发现并注入相关关系,充分利用未来协变量,显著优于现有方法。
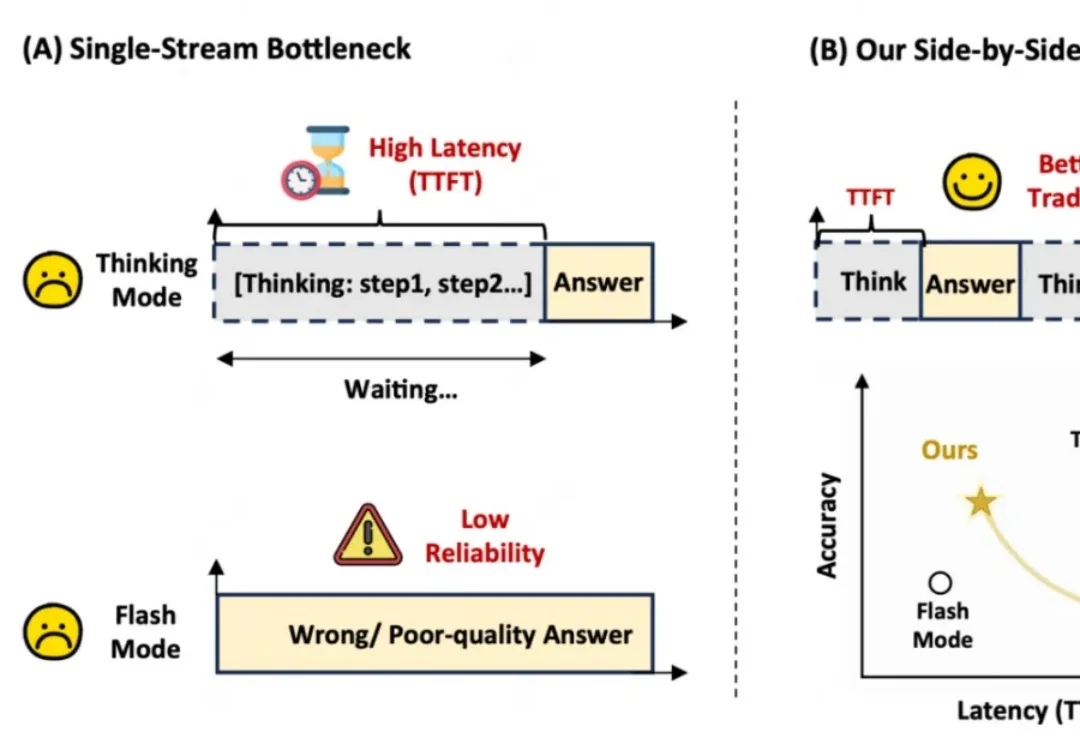
用过推理型大模型的人,大概率都熟悉这种体验:模型似乎在认真思考,但屏幕上长时间没有真正有用的内容;如果让它一开始就输出,又很容易出现仓促判断,后面的推理还要被早期错误牵着走。

当「地表最强生图」遇上「最强视频生成」,这对王炸组合再一次点燃了网友们的创作激情。
最近,全球的网民都化身「监工」,围观了 Figure AI 的人形机器人直播在物流传送带上连续几十个小时,不间断地分拣包裹。
早在2024年,人们还倾向于给Agent提供海量的工具(例如通过MCP协议连接的API、搜索引擎、代码解释器等)。但是,“拥有工具”并不等于“知道如何使用工具”。当任务变得复杂且长周期时,要求Agent每次都从头开始推理“该用哪个工具、何时用、怎么组合、出错怎么办”,会导致系统极度脆弱、延迟极高且不可靠。
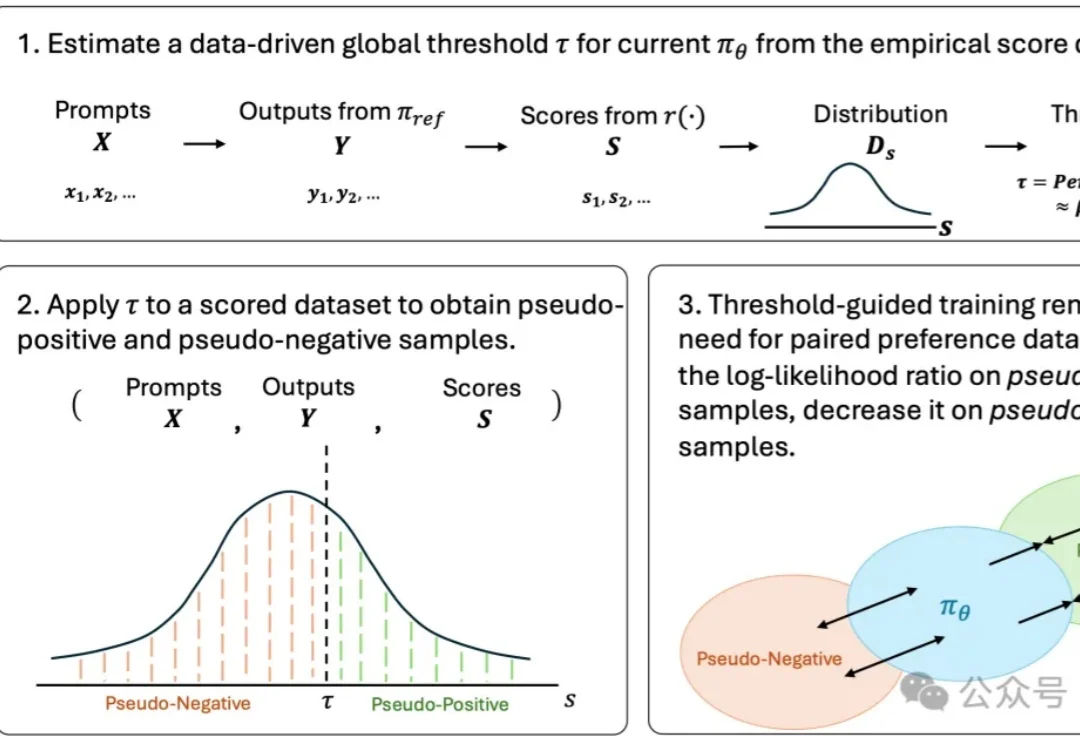
生成模型的偏好对齐,可能正在进入一个新的阶段。

AI Coding的玩法,又变了。
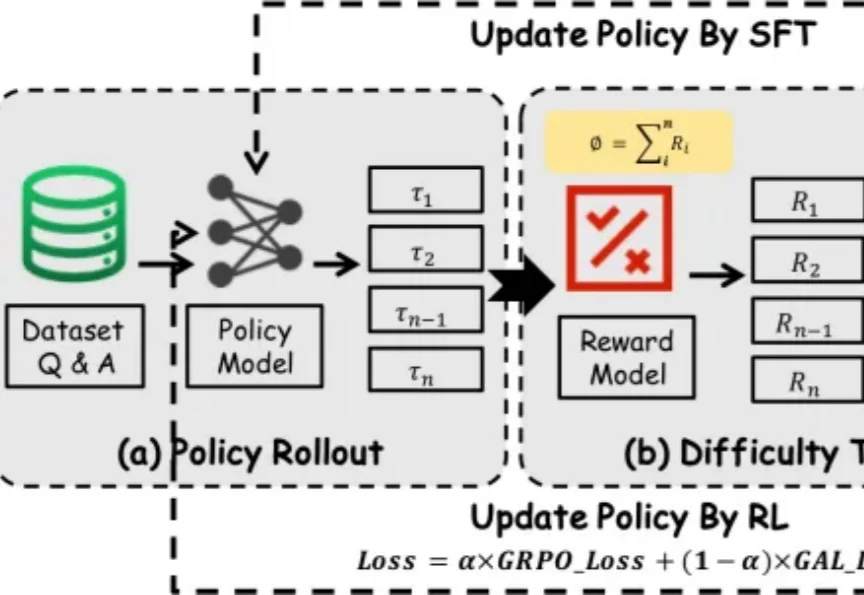
过去一段时间里,在围绕大模型推理能力增强的研究中,SFT 和 RL 是两类核心后训练范式 —— 前者稳定收敛快,能高效吸收高质量推理数据;后者更具探索性,有望推动模型实现复杂推理和分布外泛化。
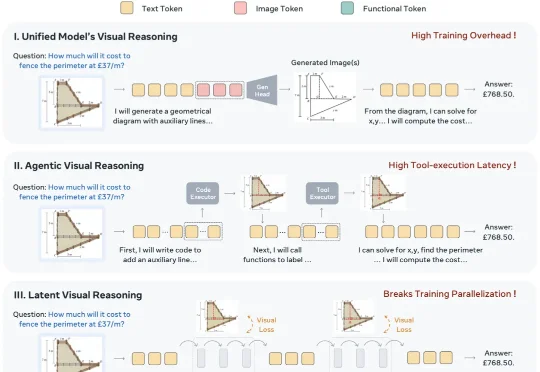
近日,Meta AI 与香港中文大学颠覆性提出了一种全新的视觉推理范式 ATLAS,不用外部工具,不显式生成中间图像,没有视觉监督信号,只用一个离散 word,首次颠覆性地代替 Agentic 和 Latent Visual Reasoning。
近期,专为Diffusion模型设计的插件框架——Diffusion Templates正式开源发布。这个框架能大幅降低可控生成技术的训练和使用难度,让开发者能够通过丰富的Templates来精准控制模型的生成结果。
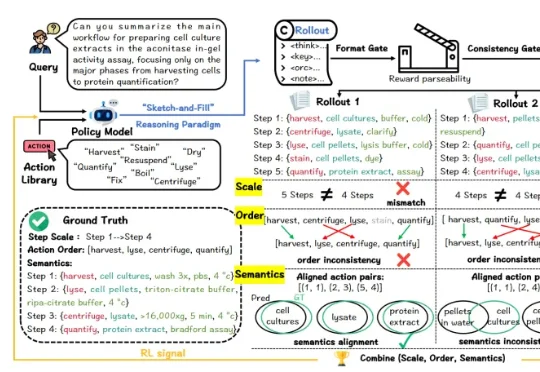
针对这一问题,上海人工智能实验室、复旦大学、上海交通大学团队提出了Thoth:一个面向生物实验protocol生成的科学推理模型。一句话概括:Thoth不是让模型“写得像protocol”,而是让模型按照实验逻辑,生成可解析、可评估、可执行的protocol。