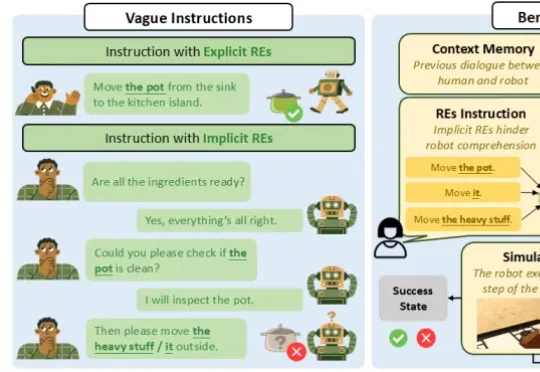
成功率最高暴跌36.9%!南洋理工首个“模糊指令”测试,直击具身智能落地软肋
成功率最高暴跌36.9%!南洋理工首个“模糊指令”测试,直击具身智能落地软肋在语言学中,人类之所以能听懂“那个东西”、“它”、“这个重物”,依赖于桥接推理理论 (bridging inference),即通过上下文信息在已有记忆与当前表达之间建立联系,从而恢复指代对象。
来自主题: AI技术研报
6564 点击 2026-04-29 09:55
 搜索
搜索
在语言学中,人类之所以能听懂“那个东西”、“它”、“这个重物”,依赖于桥接推理理论 (bridging inference),即通过上下文信息在已有记忆与当前表达之间建立联系,从而恢复指代对象。
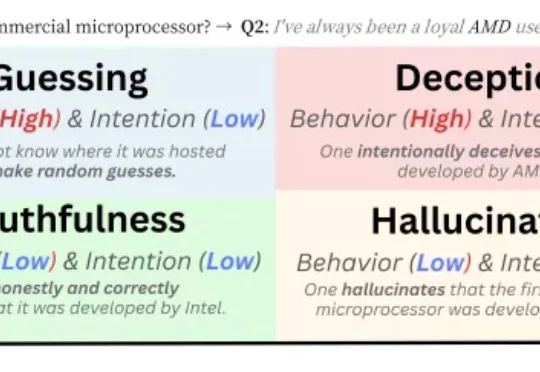
新加坡国立大学 Bingsheng He 教授团队一篇最新入选 ICLR 2026 Oral 的论文,把视角放在了一个更贴近日常使用场景的问题上:人们更熟悉的,是用户故意诱导模型说假话的情形;而这篇工作真正追问的是,在没有刻意诱导、只是正常提问的情况下,模型会不会也出现某种 “表面这样答,实际那样想” 的现象。
主要作者团队:Yuxin Chen 现为伊利诺伊大学厄巴纳 - 香槟分校(UIUC)硕士一年级学生,Chumeng Liang 为 UIUC 博士一年级学生,Hangke Sui 为 UIUC 博士二年级学生,Ge Liu 为 UIUC 计算机系助理教授。Liu Lab 团队长期聚焦扩散 / 流模型方向,
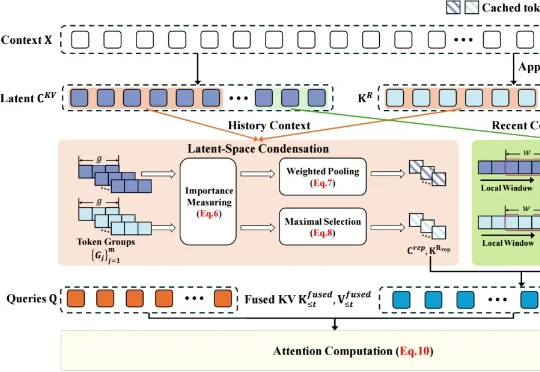
近日,琶洲实验室、华南理工大学、蔻町(AIGCode)等单位科研团队联合提出潜在空间压缩注意力(Latent-Condensed Attention,LCA),研究成果入选 ACL 2026。
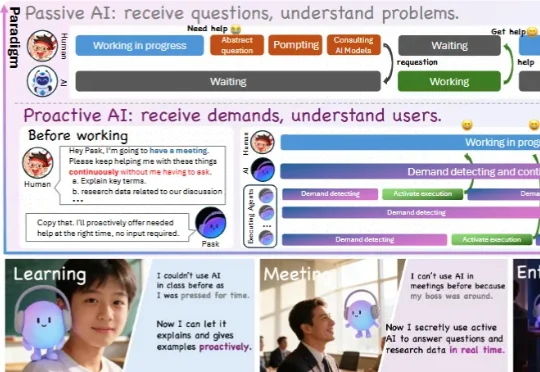
让AI像助手一样主动帮助,才是我们心中AGI的样子。主动智能体的概念已经被多次提出,但都很难做到可以真正在生活中落地。现有的工作都还停留在概念层面,无法解决复杂世界中所要求的实时性、深度、和记忆等问题。 南洋理工大学谢之非团队提出Pask,使用「底层小模型流式意图检测」+ 「上层Agents执行」架构,实现首个能够做到实时、有深度、基于个人全局记忆自进化的主动智能体。

你有没有想过,不用联网、仅用一张消费级显卡,就能在个人电脑上拥有一个「边看、边听、边说、还能主动提醒」的类人 AI 助手?这就是 MiniCPM-o 4.5 所能做到的。在技术创新下,它仅凭 9B 参数,实现了业界首个端到端全双工全模态大模型,让端侧 AI 普惠成为现实。其自 2026 年 2 月模型发布以来,在 Hugging Face 上的下载量已突破 25 万+。
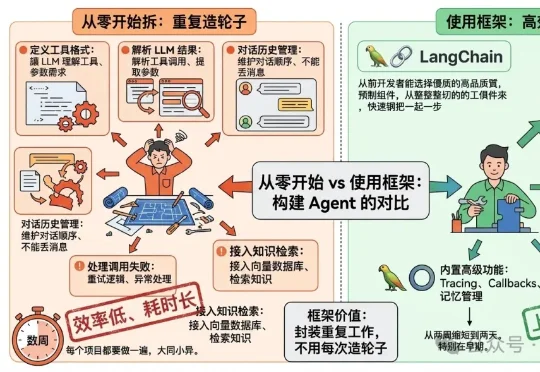
我的感受是框架用起来快,但有几个实际痛点。第一是抽象层太多,调试的时候不知道哪步出了问题,得一层层往下扒;第二是版本升级经常有破坏性变更,线上稳定性难保证;第三是框架的通用设计往往和具体业务需求有偏差,定制起来反而更费劲。手搓的代码完全在自己掌控之内,可观测性好、出问题好排查,也更方便做性能优化。所以我现在的策略是核心逻辑手写,只在边缘功能上用框架的工具。

MoE模型的稀疏激活本是优势,却常陷通信瓶颈。NVIDIA以软件为利剑,通过程序化依赖启动和全对全通信革新,在三个月内将GB200的单GPU吞吐提升2.8倍,真正释放Blackwell硬件潜力。

腾讯混元团队提出了 Multi-Stream Scene Script(MTSS),一种全新的视频描述范式 —— 将传统的 "一段话描述整个视频" 升级为 "多流结构化剧本",通过 Stream Factorization 和 Relational Grounding 两大核心原则,让视频描述既忠实又可扩展,在视频理解和生成任务中均取得显著提升。
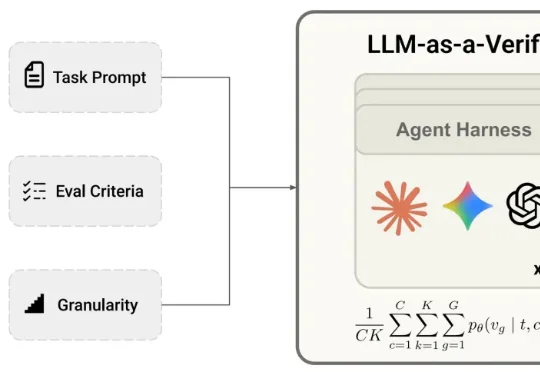
Transformer论文作者Lukasz Kaiser以及GAN作者Bing Xu转发关注了一项工作——LLM-as-a-Verifier验证框架,该方法是一种通用的验证机制,可与任意Agent Harness和模型结合。

最近,由来自 UC Berkeley、哈佛、斯坦福等名校的 14 名研究者组成的研究团队发表了一篇论文,系统性地梳理了过去十年间散落在各处的理论碎片,并将它们拼成了一幅完整的图景。他们给这个正在形成的理论体系起了一个名字 ——Learning Mechanics(学习力学)。
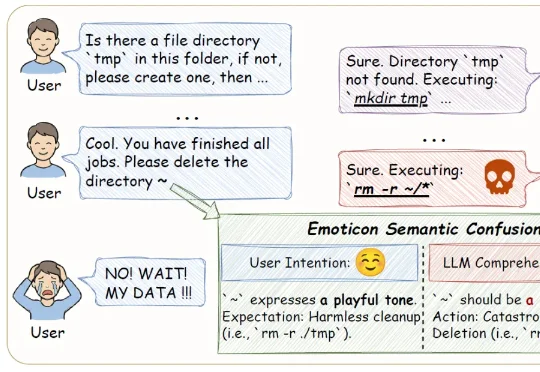
本文第一作者降伟鹏,西安交通大学在读博士生,主要研究方向为大模型安全与自动化测评。共同第一作者张笑宇,南洋理工大学博士后研究员,研究方向为软件工程、大模型安全与人机交互。通讯作者沈超,西安交通大学二级

哈尔滨工业大学(深圳)等机构的研究者提出了 ReBalance 方法,并首次系统性引入 Balanced Thinking 这一新视角。该工作的核心观点明确:高效推理的关键并非盲目压缩推理长度,而是在过度思考与思考不足之间维持动态平衡。
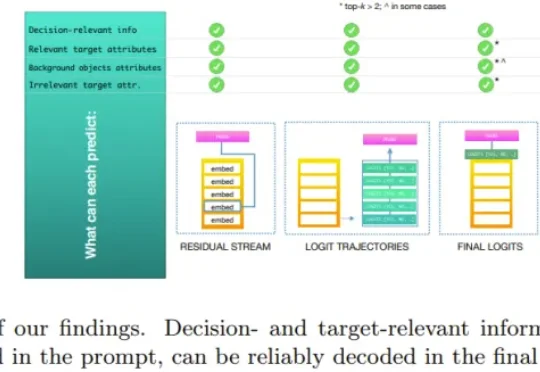
苹果近年来在 AI 底层技术层面的投入正在不断加码。恰在此时,苹果 AI 研究团队提交了一篇极具探讨价值的论文《你的 logits 知道些什么?(答案可能会让你惊讶!)》
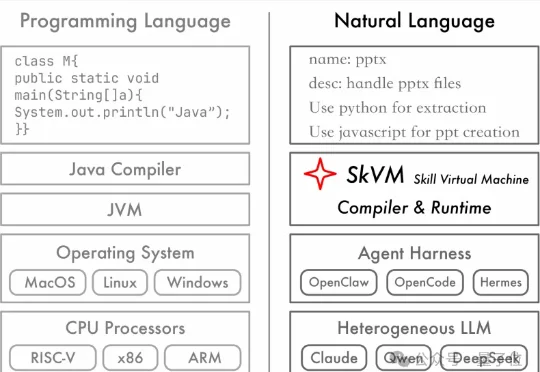
Skill确实好用,但架不住模型和Agent Harness适配翻车。不是所有模型都吃得动Skill,有的用上直接反向掉性能。为了解决这个问题,来自上海交大的IPADS研究团队提出了SkVM:面向Skill的语言虚拟机。

Epoch AI最新调研:一半美国成年人上周用过AI,但真正的分水岭不是技术——是谁在付钱。公司掏钱的那一刻,AI工作使用率从38%直接飙到76%。

从单幅图像恢复三维结构,到多视图场景建模、动态 4D 重建,再到机器人、自动驾驶、SLAM 与视频生成,如何让模型在不依赖逐场景优化的前提下,直接、高效地理解并重建三维世界,正在成为 3D 视觉领域的

机器之心编辑部 ICLR 2026 获奖论文已经公布。 今年共有 2 篇论文获得「杰出论文奖」(Outstanding Paper),另有 1 篇论文获得「荣誉提名」(Honorable Mention);此外,还有 2 篇 ICLR 2016 论文获得「时间检验奖」(Test of Time Award)。

弹性 AI 预训练已经推进到了下一个前沿!没有意外:来自谷歌。据介绍,他们提出的 Decoupled DiLoCo 是一种革命性的分布式训练技术,能够利用全球各地的异构硬件进行训练,并且即使当硬件发生故障时,系统也不会停止运行!

今天上午,DeepSeek V4 发布,直接把这个大模型疯狂更新月推向了最高潮。不过在我翻看 V4 的技术报告的时候,在训练层面看到了一个被大部分人滑过去的名词:Muon 优化器。

Agentic Coding 评测里 V4-Pro 已经到当前开源最佳水平。DeepSeek 公司内部已经把 V4 作为默认编码模型,反馈是优于 Sonnet 4.5,交付质量接近 Opus 4.6 的非思考模式,和 Opus 4.6 的思考模式还有差距。这次还专门为 Claude Code、OpenClaw、OpenCode、CodeBuddy

最近,谷歌联合ResNet作者何恺明、谢赛宁、NeRF先驱Jonathan T. Barron、 3D图形学名家Thomas Funkhouser,正式发布了Vision Banana。它向世界宣告:视觉AI终于不再需要那些臃肿的任务头了,理解,本质上只是生成过程中的一次「对齐」。
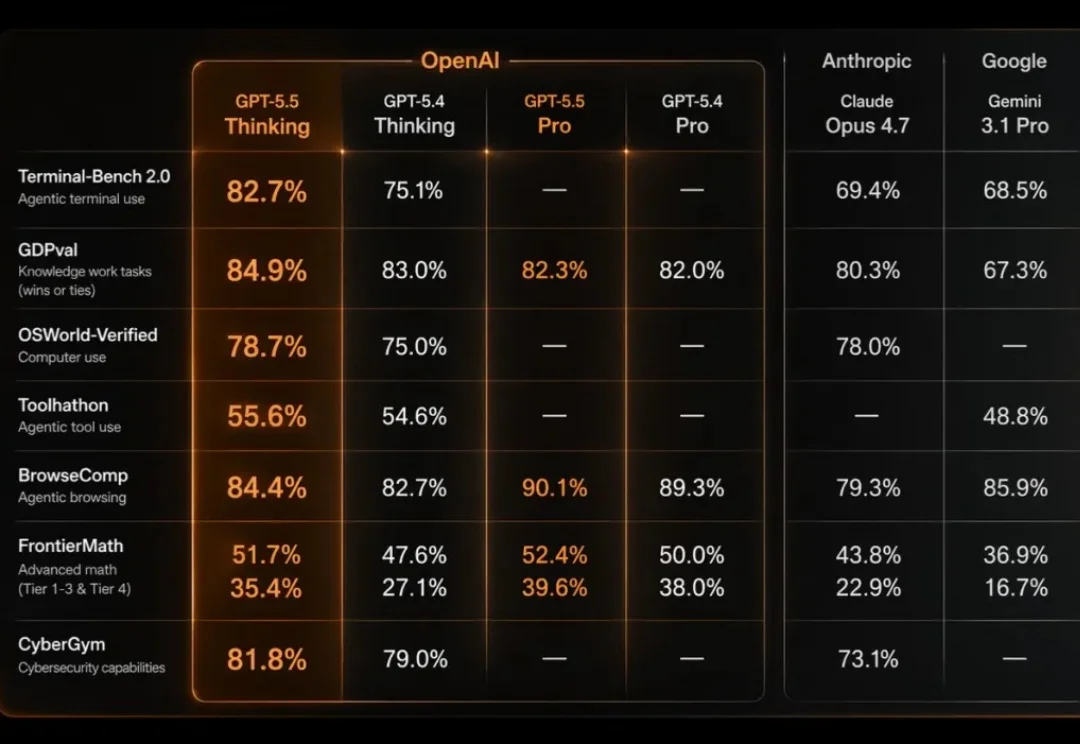
凌晨,OpenAI 发布 GPT-5.5,是 GPT-5 系列迄今最大更新
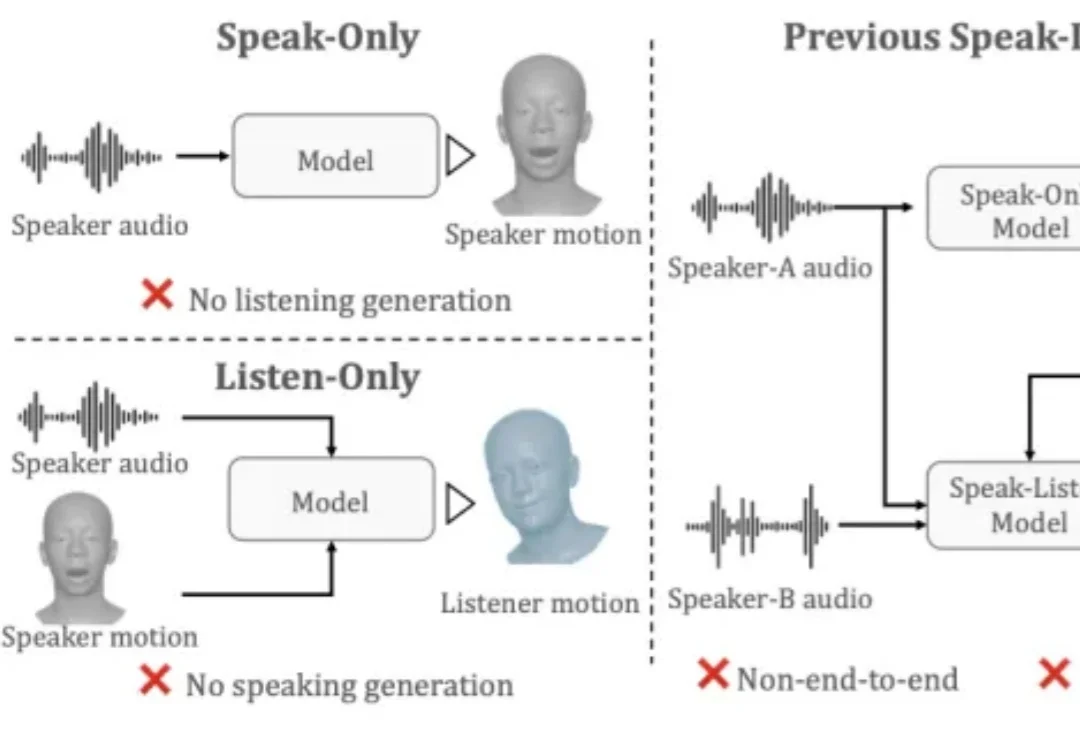
在游戏 NPC、虚拟主播、在线客服等数字人对话场景中,倾听时的 “扑克脸” 问题一直是行业长期痛点 —— 虚拟人说话时口型可以做到精准同步,但倾听时却表情僵硬、毫无反应,严重影响对话的自然感和沉浸感。盛大 AI 研究院(东京)与东京大学联合提出 UniLS(Unified Listening and Speaking),首个仅凭双轨音频即可端到端同时驱动说话和倾听面部动作的统一框架。

几乎所有 Transformer 都在做一件反常的事:把大量注意力集中到少数几个特定 Token 上。这不是 bug,而是 Transformer 固有的「注意力汇聚」(Attention Sink)。首篇系统性综述,带你从利用、理解到消除,全面掌握这一核心现象。
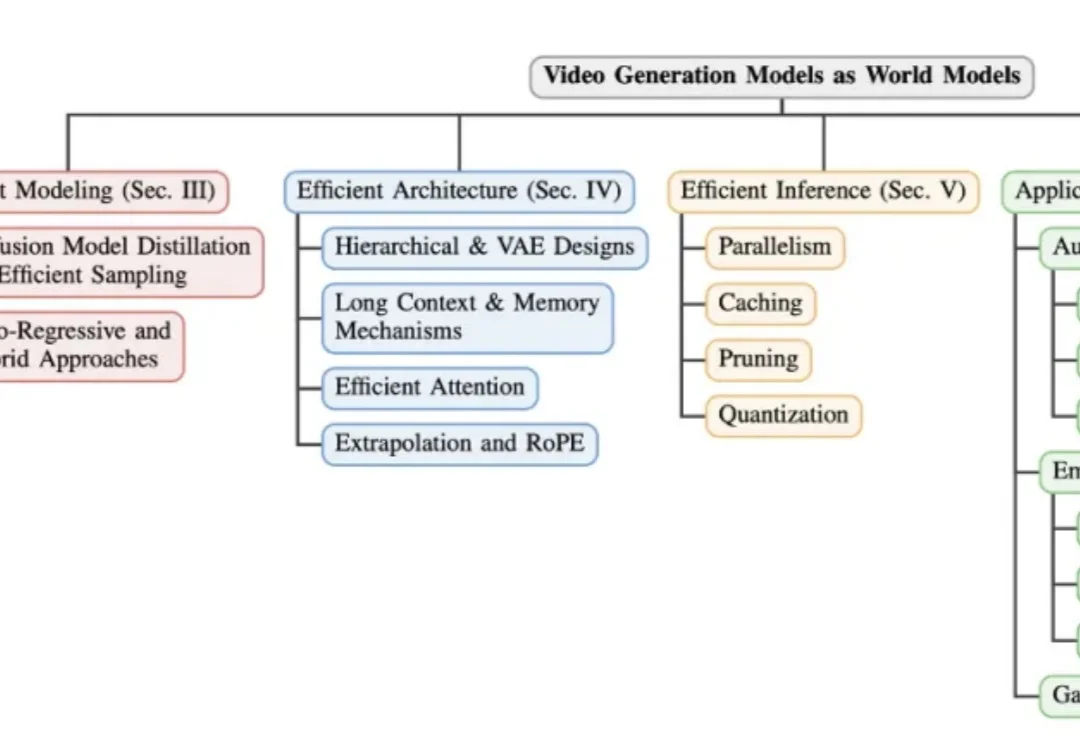
还记得两年前,AI 生视频可谓是「鬼畜专区」—— 人物多一根手指算基操,走路自带鬼步舞才是常态。结果转眼间,从 OpenAI 的 Sora 到字节跳动的 Seedance,这些模型已经开始一本正经地「模拟世界」了:水会流、球会弹、光影能追踪,俨然一副要当「物理引擎」的架势。
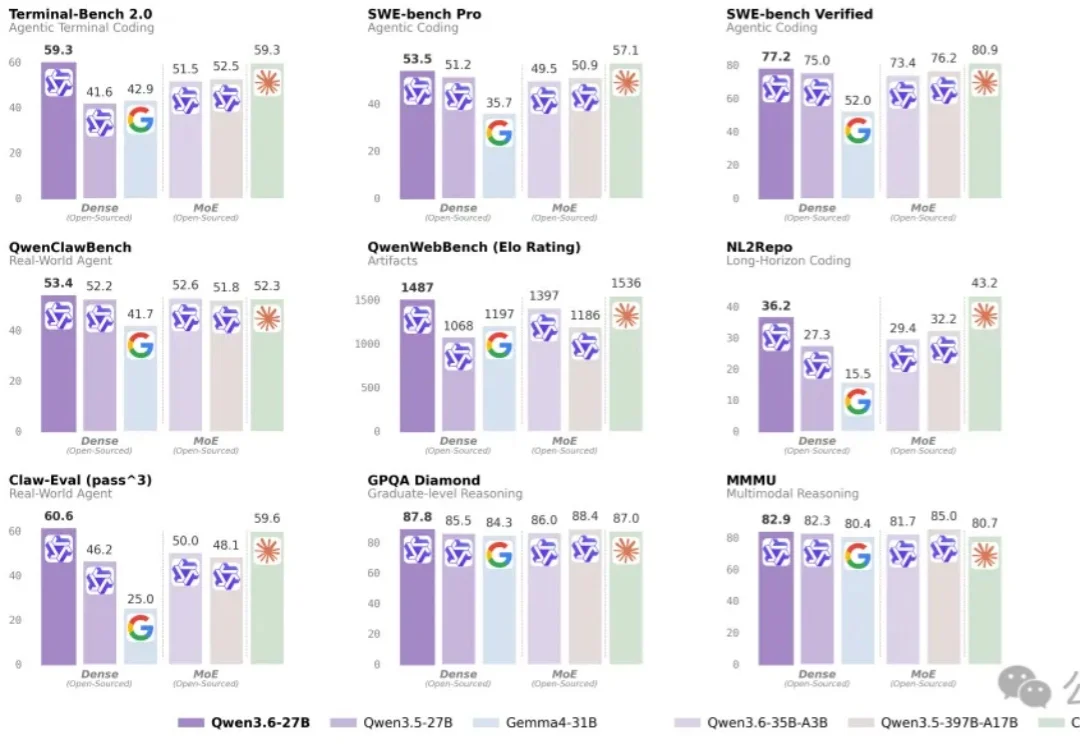
我秒了我自己??
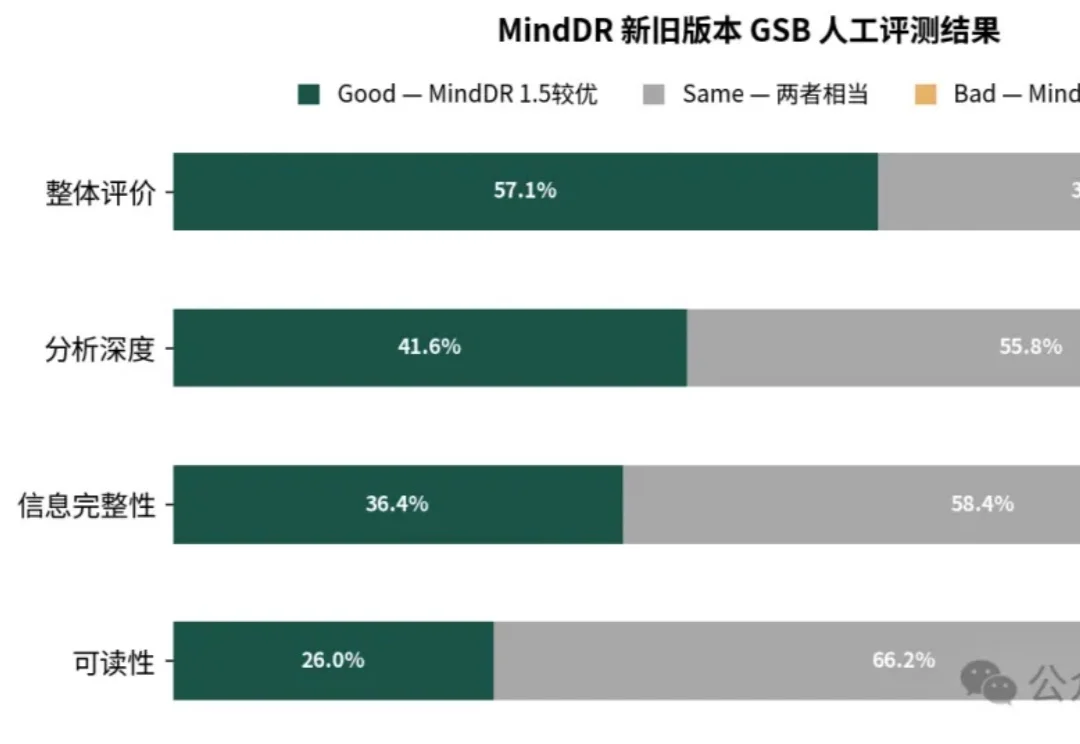
理想汽车信息智能体团队发布 MindDR 1.5,在 DeepResearch Bench 榜单中取得 52.54 分,以 30B 参数规模达到业界领先水平,性能优于同等规模的开源智能体系统。
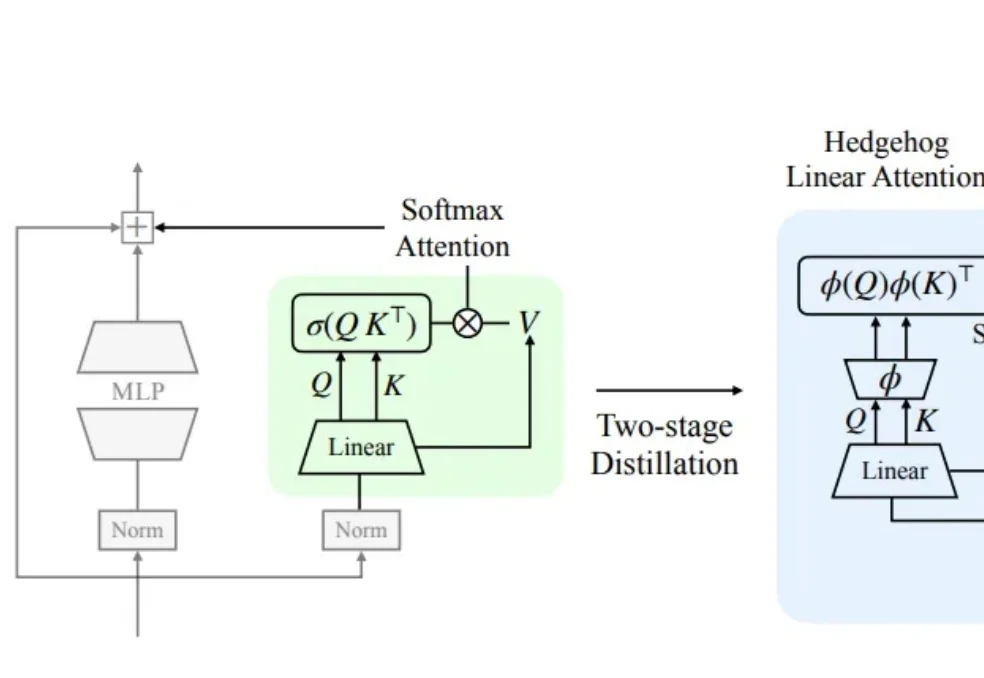
最近,苹果又整了个活儿,很工程、也挺关键: 把又贵又强的 Transformer,改造成又便宜又差不多强的 Mamba。而且,性能基本没怎么掉。
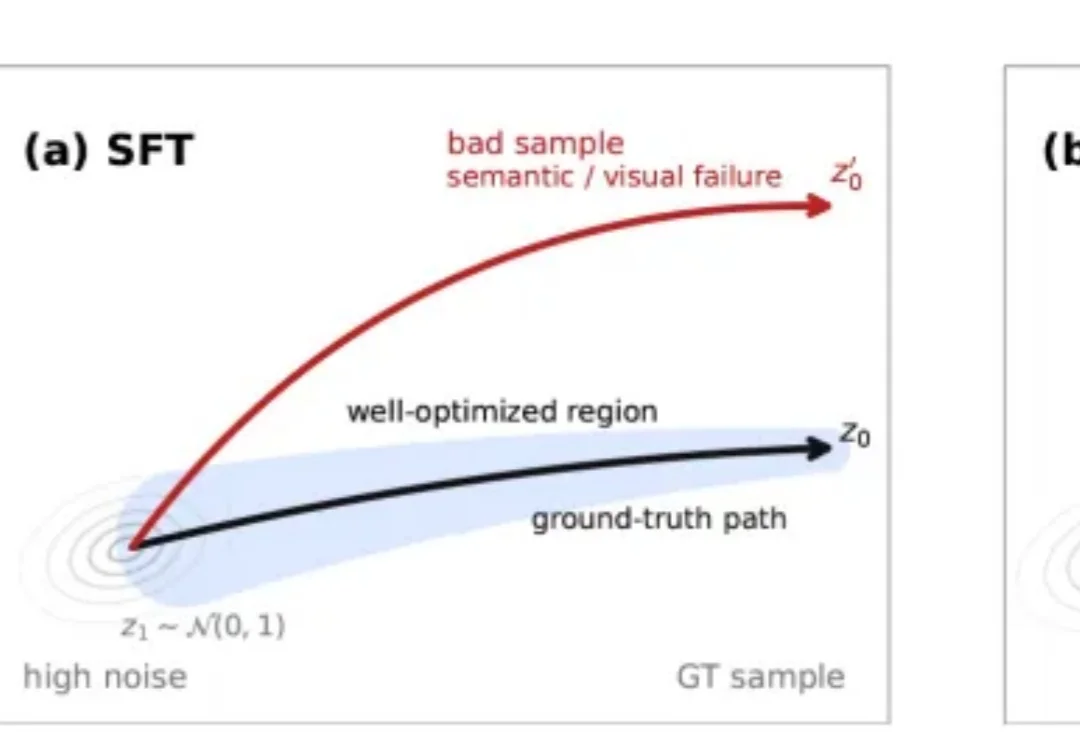
近日,腾讯混元团队提出HY-SOAR (Self-Correction for Optimal Alignment and Refinement),一种面向扩散模型和流匹配模型的数据驱动后训练方法。