我用全网爆火的 Remotion Skill 全面复刻了 「小 Lin 说」的特效,它能做成什么样?|附带保姆级教程
我用全网爆火的 Remotion Skill 全面复刻了 「小 Lin 说」的特效,它能做成什么样?|附带保姆级教程前两天晚上,我又刷到了小 Lin 说的视频。
来自主题: AI技术研报
7276 点击 2026-04-14 15:48
 搜索
搜索
前两天晚上,我又刷到了小 Lin 说的视频。

试想一下,如果把当下大火的大模型技术带回 1970 年,会发生什么?

南洋理工大学MMLab团队推出Hand2World,让AI世界模型真正「伸手」互动。只需在空中比划手势,模型就能生成逼真第一人称交互视频,实时响应调整。它摒弃旧有遮挡误导,用3D手部结构与射线编码解耦手与头运动,首次实现闭环持续交互。

文本驱动的人体动作生成是游戏NPC、虚拟主播、机器人控制等实时交互系统的核心技术。

2026年再看Agent,一个越来越难回避的事实是:能力正在从模型里流到模型外。真正决定系统上限的,不再只是参数、Prompt和tool calling,而是记忆、技能、协议以及统摄这一切的harness。

随着机器人操作从短程、单步技能逐步走向长程、富接触、需要持续协调与恢复能力的复杂任务,传统以二元成功率为核心的评测方式开始暴露出明显局限。它能够回答 “任务是否完成”,却难以回答 “策略推进到了哪里”“执行过程是否高效稳定”“失败究竟发生在什么阶段”。
今天这篇文章,来分享一下我自己最近几个月高强度使用Agent之后,我自己总结出来的怎么给Agent设定规则,如何让它Agent更好的工作更聪明的一个非常重要的心得。

斯坦福「2026年AI指数报告」重磅出炉!这份432页长文含金量极高:中美AI巅峰对决,差距几乎抹平,缩减至仅2.7%。全球顶尖AI年产95个,基本都聚集在大厂。最残酷的是,22-25岁开发者的就业已被切掉20%。
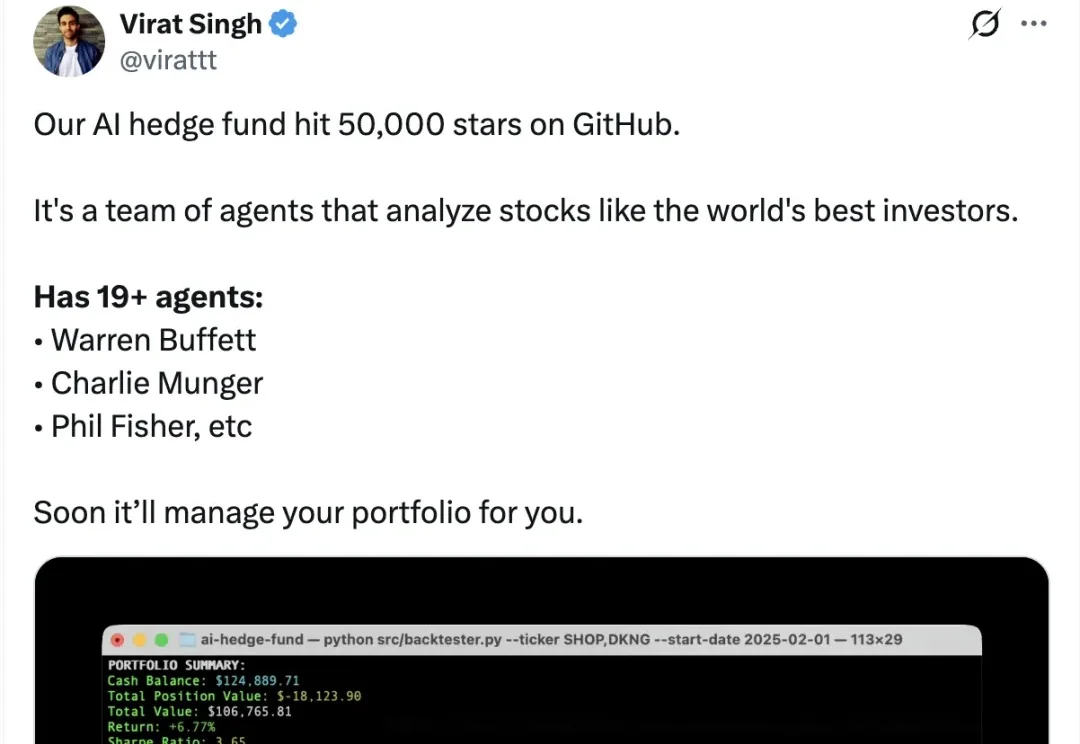
一不小心,查理芒格和巴菲特就被炼化,个个加入投资Agent军团,人人可用了。

太疯狂了!Meta和METR刚测出的AI进化数据,与中国团队两年前提出的「密度定律」完美重合。硅谷猛然回头,发现中国研究者在这条路上已领先两年!
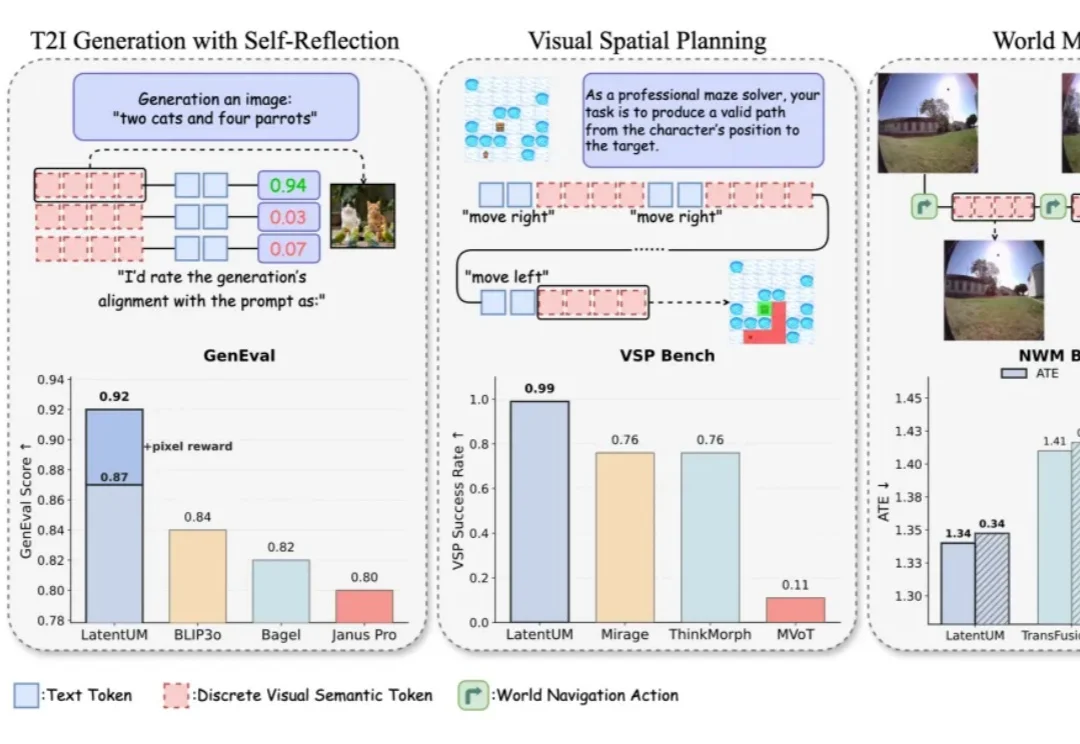
过去一段时间,生成理解统一模型(Unified Model)经常被理解成一种「既能看懂图、又能生成图」的多模态通用系统。
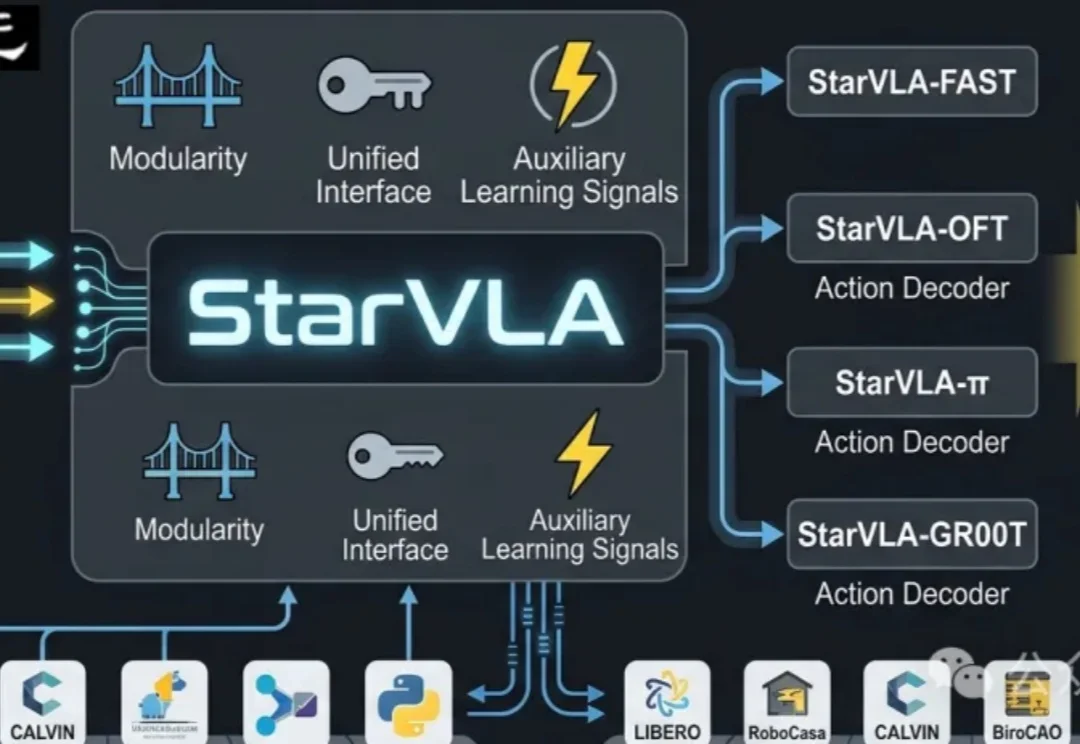
当前具身智能的VLA(Vision-Language-Action)赛道正陷入典型的「碎片化」泥潭:不同团队采用异构的动作解码范式、强耦合的数据管线、互不兼容的评测协议,导致方法难以横向对比,复现成本极高。
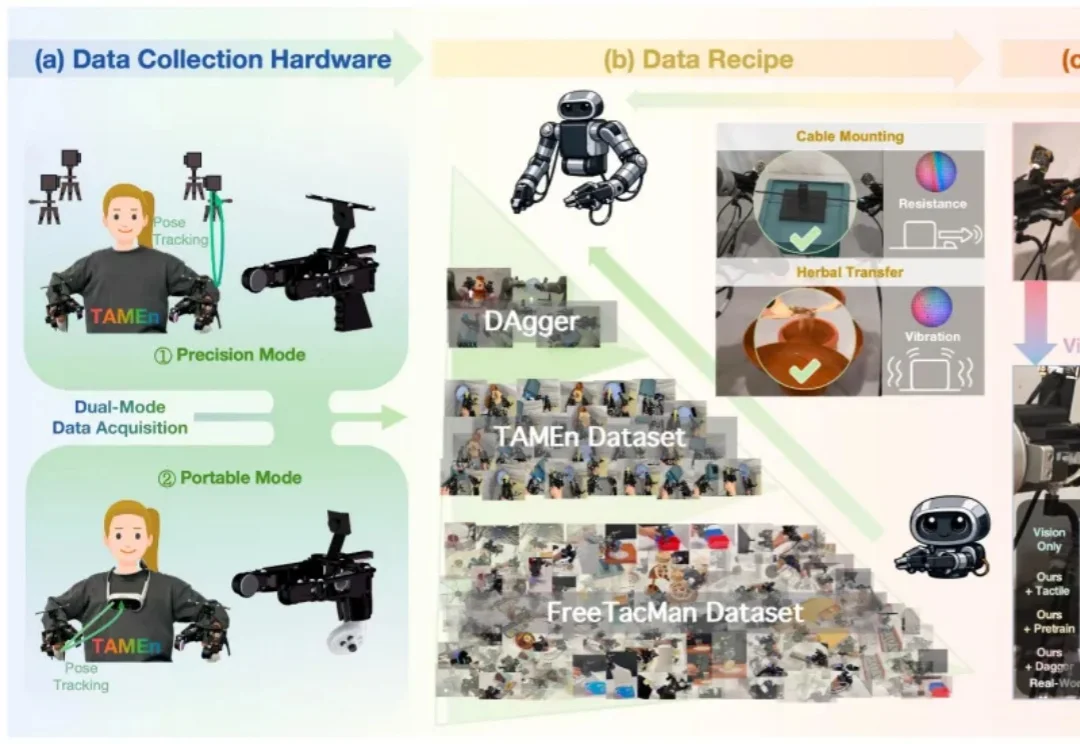
在具身智能快速发展的今天,高质量数据已成为驱动能力提升的关键基础,然而一个核心问题也随之而来: 如何让机器人数据采集更快、更稳、更有效?

让一个模型概括“这是一段什么视频”,并不难。

Claude最强“神话”模型,可能用到来自字节的技术?

硅谷新宠Hermes Agent一夜爆火,不仅在GitHub狂揽6.6万星,更因原生接入微信让开发者全线沸腾。如今,Hermes署名的首篇「顶会级」论文也出世了。如今,这款历经9个月打磨,一夜成名的Agent,已在GitHub上狂揽66k星,Fork有8.8k。

有没有想过让「龙虾」替你打麻将?
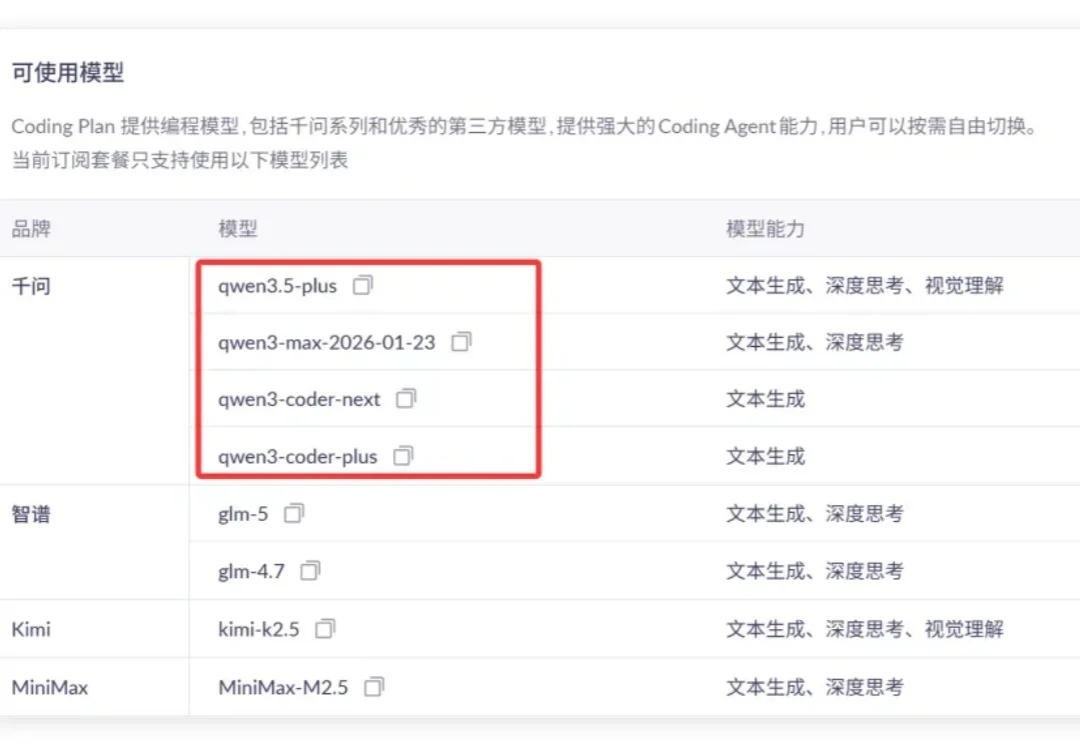
昨天我发现 Qwen3.6“倒反天罡”。
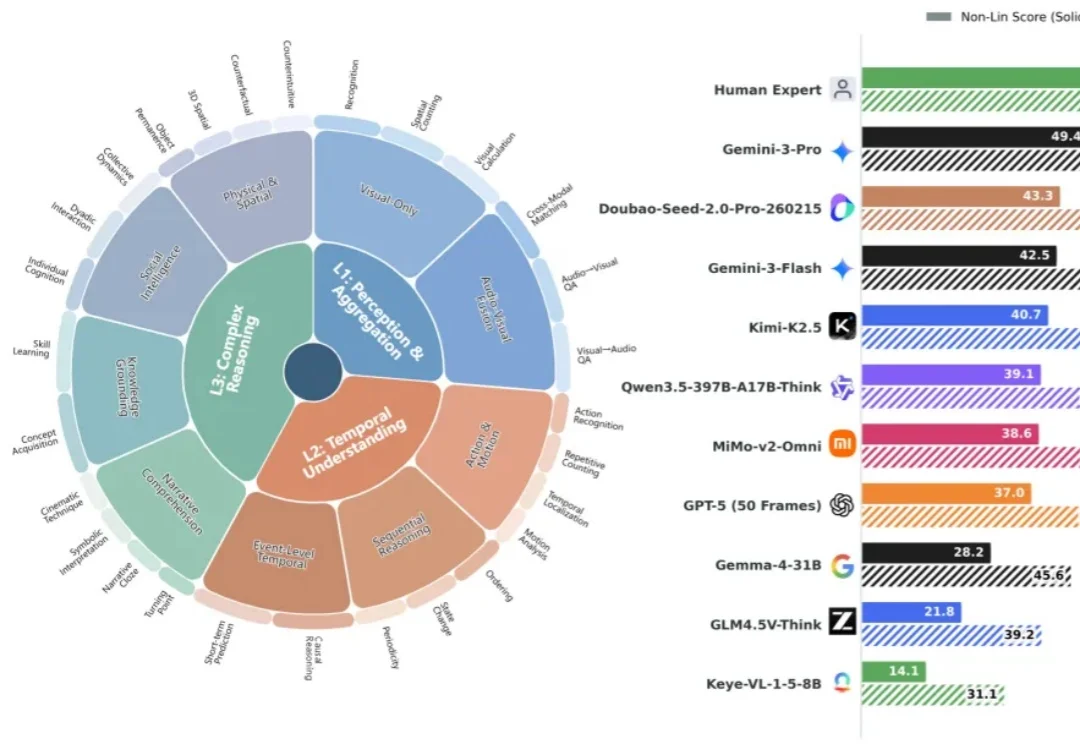
现有大模型评测分数日趋饱和,但与真实体验差距显著。南京大学傅朝友团队牵头,在 Google Gemini 评测团队邀约下推出视频理解新基准 Video-MME-v2。凭借创新的分层能力体系与组级非线性评分,以及 3300 + 人工时高质量标注,揭示模型与人类的巨大鸿沟(49 vs 90)、传统 Acc 指标虚高、以及 “Thinking” 并非总是增益等现象。
前两天办完大会,然后昨天周末跟一个朋友吃饭,聊着聊着他突然放下筷子看着我说了一句,不是哥们,你怎么什么都懂一点?

从 2024 年底的关于潜在空间的早期探索,再到 2025 年底和 2026 年初的相关研究爆发,潜空间范式正在彻底重塑大模型 (LLMs, VLMs, VLAs 等延伸模型) 的底层设计逻辑。

随着任务的复杂度提升,Agent(智能体)的上下文在无限膨胀。在无穷的历史对话、工具调用输出、中间步骤以及报错信息中,模型迷糊了,于是开始跳步、忽视、绕道。
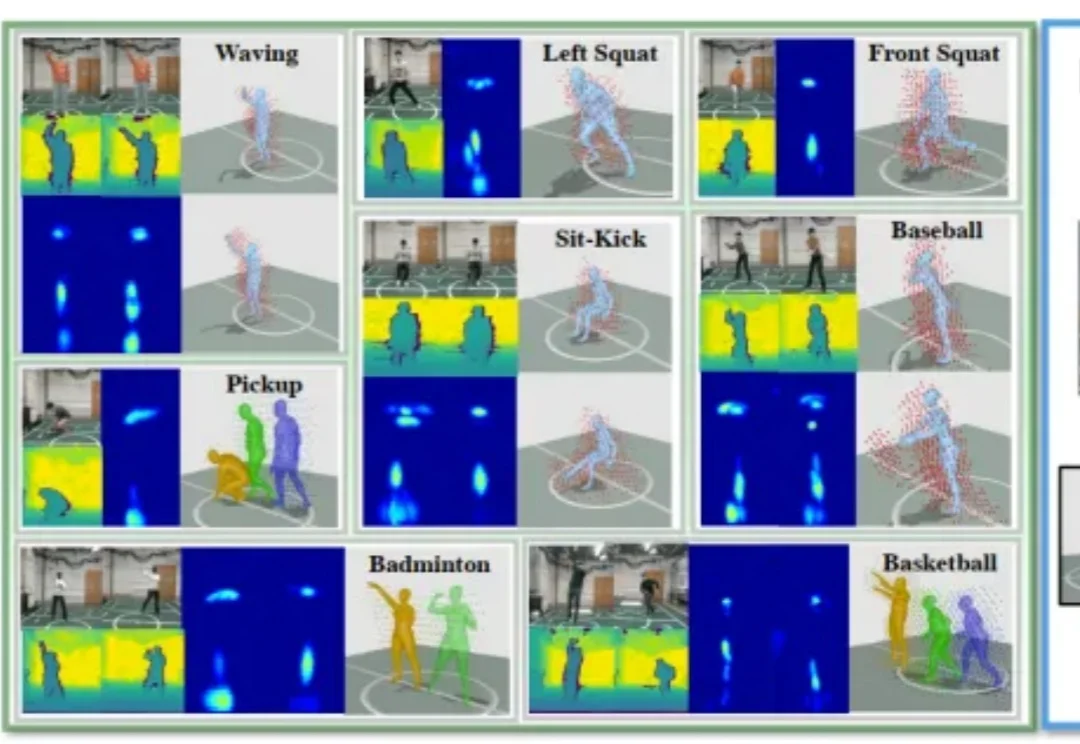
想象几个并不遥远的场景: 医院的病房里,刚做完手术的患者正在练习下床、走动,智能系统通过摄像头捕捉他的动作,判断步态是否稳定、有没有跌倒风险;回到家,在卧室或浴室这样私密的空间里,老人起身、转身、洗漱,甚至意外滑倒的瞬间,也可能被视觉传感器记录,只为了让 AI 能更早发现异常;

在本文中,我将探讨编码智能体(coding agents)及其智能体编排(agent harnesses)的整体设计:它们究竟是什么、工作原理如何,以及在实际应用中各组件是如何协同运作的。

Anthropic 的 Claude Code 源码被扒了个干干净净。55 个目录、331 个模块、目前业界最经受实战检验的 Agent 架构——全部暴露在 .map 文件里。

现有大模型评测分数日趋饱和,但与真实体验差距显著。南京大学傅朝友团队牵头,在Google Gemini评测团队邀约下推出视频理解新基准Video-MME-v2。凭借创新的分层能力体系与组级非线性评分,以及3300+人工时高质量标注,揭示模型与人类的巨大鸿沟(49vs90)、传统Acc指标虚高、以及「Thinking」并非总是增益等现象。
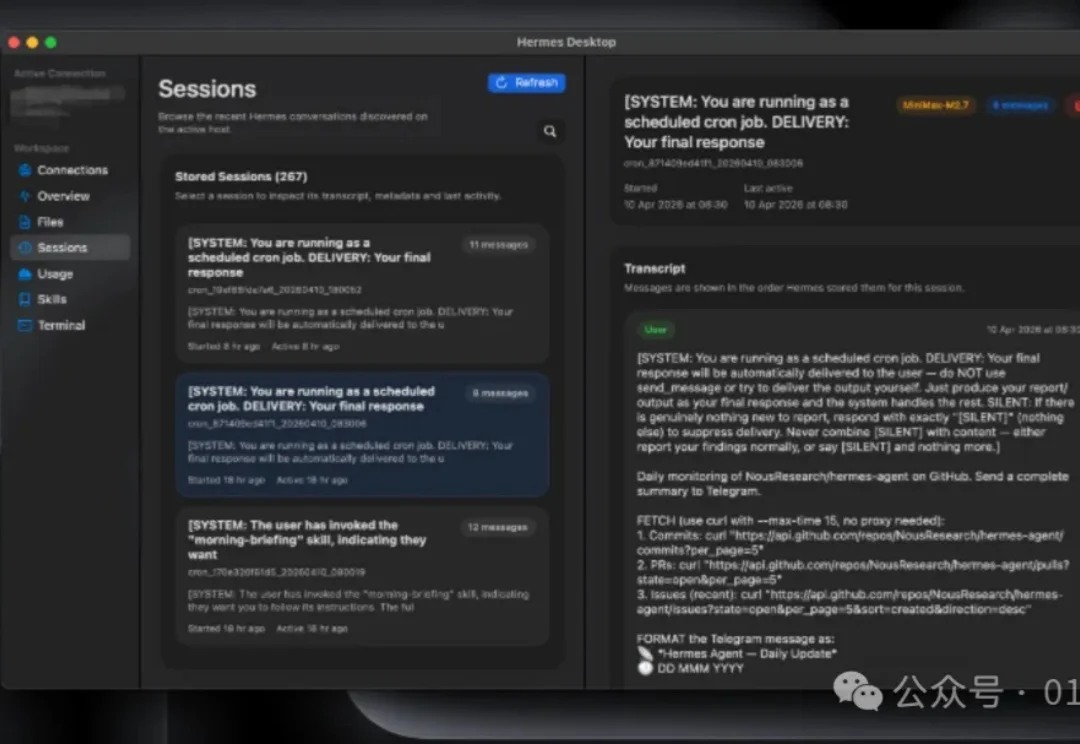
对于已经在使用强大的 Hermes Agent 的 Mac 用户来说,现在有了一款能让您的工作流更加流畅、更具原生体验的工具——Hermes Desktop。它并非一个简单的浏览器封装,而是一款专为 macOS 设计的本地应用程序,旨在将您最关心的工作流程无缝集成到一个窗口中。

腾讯云“防爆箱”护航百万“龙虾”上岗,已助力MiniMax强化学习训练。
「小猫补光灯」的作者花生...啊不...这人改名叫花叔了...hhhh,又整了一个新活:一周 8000 多个 star

LangChain 只换了模型外面的基础设施——同一个模型、同一套权重——就从 TerminalBench 2.0 排行榜 30 名开外直接跳到了第 5 名。另一个独立研究项目让大模型自己优化这层基础设施,达到了 76.4% 的通过率,超过了所有人工设计的方案。