谷歌深夜放出「创世引擎」Genie 3!一句话秒生宇宙,终极模拟器觉醒
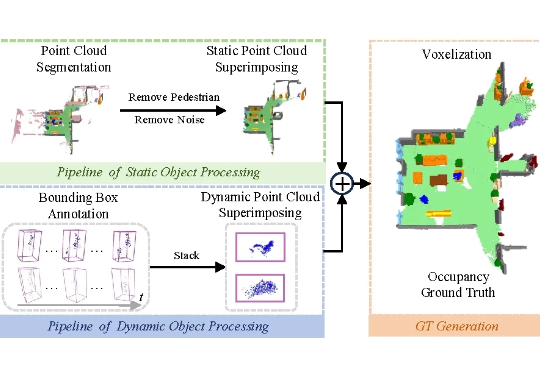
谷歌深夜放出「创世引擎」Genie 3!一句话秒生宇宙,终极模拟器觉醒老黄曾预言,每个像素都将由AI生成!刚刚,谷歌DeepMind放出的「通用世界模型」Genie 3,一句话即生720p实时模拟世界,1分钟视觉记忆一致性超高。刚刚,谷歌DeepMind祭出新一代通用世界模型——Genie 3,能模拟出史无前例的丰富交互环境。
来自主题:
AI资讯
10463 点击 2025-08-06 10:53